 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace anonymization preserving facial expressions and photometric realism
Mar 18, 2026The widespread sharing of face images on social media platforms and in large-scale datasets raises pressing privacy concerns, as biometric identifiers can be exploited without consent. Face anonymization seeks to generate realistic facial images that irreversibly conceal the subject's identity while preserving their usefulness for downstream tasks. However, most existing generative approaches focus on identity removal and image realism, often neglecting facial expressions as well as photometric consistency -- specifically attributes such as illumination and skin tone -- that are critical for applications like relighting, color constancy, and medical or affective analysis. In this work, we propose a feature-preserving anonymization framework that extends DeepPrivacy by incorporating dense facial landmarks to better retain expressions, and by introducing lightweight post-processing modules that ensure consistency in lighting direction and skin color. We further establish evaluation metrics specifically designed to quantify expression fidelity, lighting consistency, and color preservation, complementing standard measures of image realism, pose accuracy, and re-identification resistance. Experiments on the CelebA-HQ dataset demonstrate that our method produces anonymized faces with improved realism and significantly higher fidelity in expression, illumination, and skin tone compared to state-of-the-art baselines. These results underscore the importance of feature-aware anonymization as a step toward more useful, fair, and trustworthy privacy-preserving facial data.
Leveraging Multispectral Sensors for Color Correction in Mobile Cameras
Dec 09, 2025Recent advances in snapshot multispectral (MS) imaging have enabled compact, low-cost spectral sensors for consumer and mobile devices. By capturing richer spectral information than conventional RGB sensors, these systems can enhance key imaging tasks, including color correction. However, most existing methods treat the color correction pipeline in separate stages, often discarding MS data early in the process. We propose a unified, learning-based framework that (i) performs end-to-end color correction and (ii) jointly leverages data from a high-resolution RGB sensor and an auxiliary low-resolution MS sensor. Our approach integrates the full pipeline within a single model, producing coherent and color-accurate outputs. We demonstrate the flexibility and generality of our framework by refactoring two different state-of-the-art image-to-image architectures. To support training and evaluation, we construct a dedicated dataset by aggregating and repurposing publicly available spectral datasets, rendering under multiple RGB camera sensitivities. Extensive experiments show that our approach improves color accuracy and stability, reducing error by up to 50% compared to RGB-only and MS-driven baselines. Datasets, code, and models will be made available upon acceptance.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Visual RAG: Expanding MLLM visual knowledge without fine-tuning
Jan 18, 2025



Multimodal Large Language Models (MLLMs) have achieved notable performance in computer vision tasks that require reasoning across visual and textual modalities, yet their capabilities are limited to their pre-trained data, requiring extensive fine-tuning for updates. Recent researches have explored the use of In-Context Learning (ICL) to overcome these challenges by providing a set of demonstrating examples as context to augment MLLMs performance in several tasks, showing that many-shot ICL leads to substantial improvements compared to few-shot ICL. However, the reliance on numerous demonstrating examples and the limited MLLMs context windows presents significant obstacles. This paper aims to address these challenges by introducing a novel approach, Visual RAG, that synergically combines the MLLMs capability to learn from the context, with a retrieval mechanism. The crux of this approach is to ensure to augment the MLLM knowledge by selecting only the most relevant demonstrating examples for the query, pushing it to learn by analogy. In this way, relying on the new information provided dynamically during inference time, the resulting system is not limited to the knowledge extracted from the training data, but can be updated rapidly and easily without fine-tuning. Furthermore, this greatly reduces the computational costs for improving the model image classification performance, and augments the model knowledge to new visual domains and tasks it was not trained for. Extensive experiments on eight different datasets in the state of the art spanning several domains and image classification tasks show that the proposed Visual RAG, compared to the most recent state of the art (i.e., many-shot ICL), is able to obtain an accuracy that is very close or even higher (approx. +2% improvement on average) while using a much smaller set of demonstrating examples (approx. only 23% on average).
Cross-Camera Distracted Driver Classification through Feature Disentanglement and Contrastive Learning
Nov 20, 2024



The classification of distracted drivers is pivotal for ensuring safe driving. Previous studies demonstrated the effectiveness of neural networks in automatically predicting driver distraction, fatigue, and potential hazards. However, recent research has uncovered a significant loss of accuracy in these models when applied to samples acquired under conditions that differ from the training data. In this paper, we introduce a robust model designed to withstand changes in camera position within the vehicle. Our Driver Behavior Monitoring Network (DBMNet) relies on a lightweight backbone and integrates a disentanglement module to discard camera view information from features, coupled with contrastive learning to enhance the encoding of various driver actions. Experiments conducted on the daytime and nighttime subsets of the 100-Driver dataset validate the effectiveness of our approach with an increment on average of 9\% in Top-1 accuracy in comparison with the state of the art. In addition, cross-dataset and cross-camera experiments conducted on three benchmark datasets, namely AUCDD-V1, EZZ2021 and SFD, demonstrate the superior generalization capability of the proposed method.
NTIRE 2024 Challenge on Night Photography Rendering
Jun 18, 2024


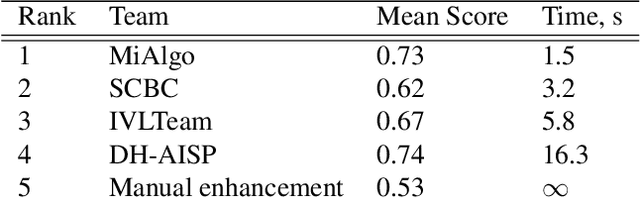
This paper presents a review of the NTIRE 2024 challenge on night photography rendering. The goal of the challenge was to find solutions that process raw camera images taken in nighttime conditions, and thereby produce a photo-quality output images in the standard RGB (sRGB) space. Unlike the previous year's competition, the challenge images were collected with a mobile phone and the speed of algorithms was also measured alongside the quality of their output. To evaluate the results, a sufficient number of viewers were asked to assess the visual quality of the proposed solutions, considering the subjective nature of the task. There were 2 nominations: quality and efficiency. Top 5 solutions in terms of output quality were sorted by evaluation time (see Fig. 1). The top ranking participants' solutions effectively represent the state-of-the-art in nighttime photography rendering. More results can be found at https://nightimaging.org.
Pathspace Kalman Filters with Dynamic Process Uncertainty for Analyzing Time-course Data
Feb 07, 2024



Kalman Filter (KF) is an optimal linear state prediction algorithm, with applications in fields as diverse as engineering, economics, robotics, and space exploration. Here, we develop an extension of the KF, called a Pathspace Kalman Filter (PKF) which allows us to a) dynamically track the uncertainties associated with the underlying data and prior knowledge, and b) take as input an entire trajectory and an underlying mechanistic model, and using a Bayesian methodology quantify the different sources of uncertainty. An application of this algorithm is to automatically detect temporal windows where the internal mechanistic model deviates from the data in a time-dependent manner. First, we provide theorems characterizing the convergence of the PKF algorithm. Then, we numerically demonstrate that the PKF outperforms conventional KF methods on a synthetic dataset lowering the mean-squared-error by several orders of magnitude. Finally, we apply this method to biological time-course dataset involving over 1.8 million gene expression measurements.
Improving Image Captioning Descriptiveness by Ranking and LLM-based Fusion
Jun 20, 2023



State-of-The-Art (SoTA) image captioning models often rely on the Microsoft COCO (MS-COCO) dataset for training. This dataset contains annotations provided by human annotators, who typically produce captions averaging around ten tokens. However, this constraint presents a challenge in effectively capturing complex scenes and conveying detailed information. Furthermore, captioning models tend to exhibit bias towards the ``average'' caption, which captures only the more general aspects. What would happen if we were able to automatically generate longer captions, thereby making them more detailed? Would these captions, evaluated by humans, be more or less representative of the image content compared to the original MS-COCO captions? In this paper, we present a novel approach to address previous challenges by showcasing how captions generated from different SoTA models can be effectively fused, resulting in richer captions. Our proposed method leverages existing models from the literature, eliminating the need for additional training. Instead, it utilizes an image-text based metric to rank the captions generated by SoTA models for a given image. Subsequently, the top two captions are fused using a Large Language Model (LLM). Experimental results demonstrate the effectiveness of our approach, as the captions generated by our model exhibit higher consistency with human judgment when evaluated on the MS-COCO test set. By combining the strengths of various SoTA models, our method enhances the quality and appeal of image captions, bridging the gap between automated systems and the rich, informative nature of human-generated descriptions. This advance opens up new possibilities for generating captions that are more suitable for the training of both vision-language and captioning models.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022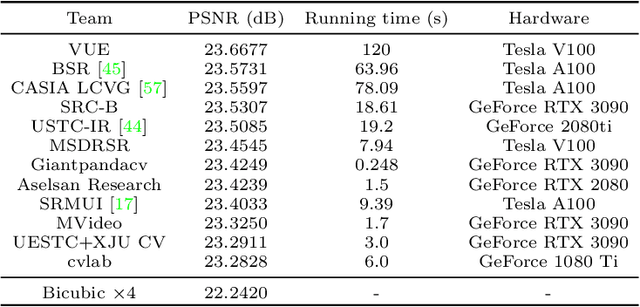
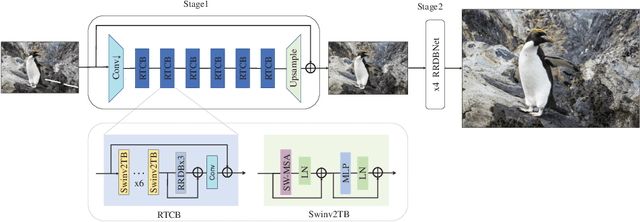

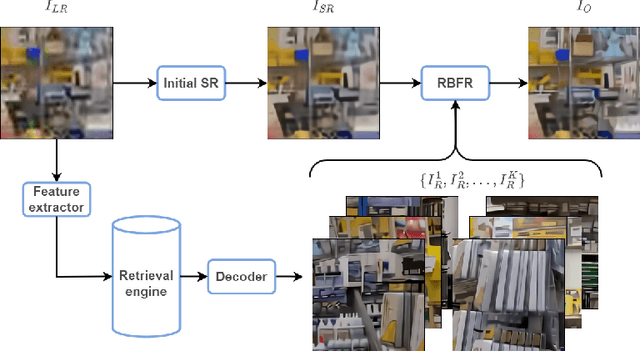
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
Semi-supervised cross-lingual speech emotion recognition
Jul 14, 2022
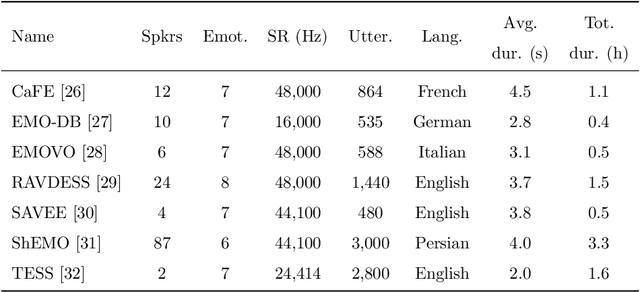
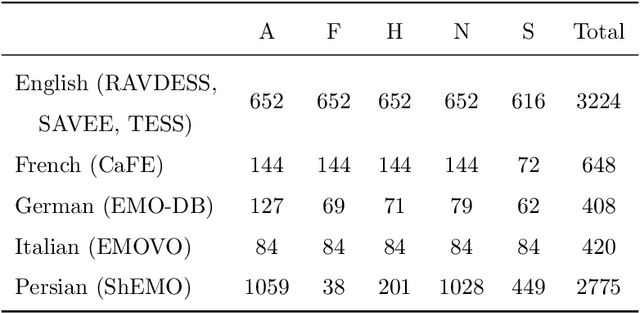
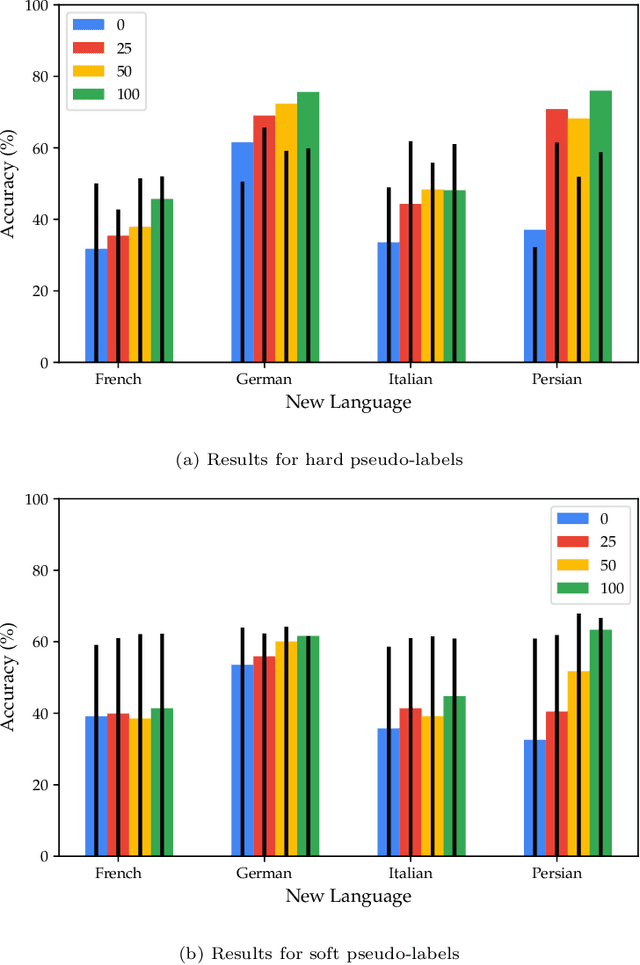
Speech emotion recognition (SER) on a single language has achieved remarkable results through deep learning approaches over the last decade. However, cross-lingual SER remains a challenge in real-world applications due to (i) a large difference between the source and target domain distributions, (ii) the availability of few labeled and many unlabeled utterances for the new language. Taking into account previous aspects, we propose a Semi-Supervised Learning (SSL) method for cross-lingual emotion recognition when a few labels from the new language are available. Based on a Convolutional Neural Network (CNN), our method adapts to a new language by exploiting a pseudo-labeling strategy for the unlabeled utterances. In particular, the use of a hard and soft pseudo-labels approach is investigated. We thoroughly evaluate the performance of the method in a speaker-independent setup on both the source and the new language and show its robustness across five languages belonging to different linguistic strains.