 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace anonymization preserving facial expressions and photometric realism
Mar 18, 2026The widespread sharing of face images on social media platforms and in large-scale datasets raises pressing privacy concerns, as biometric identifiers can be exploited without consent. Face anonymization seeks to generate realistic facial images that irreversibly conceal the subject's identity while preserving their usefulness for downstream tasks. However, most existing generative approaches focus on identity removal and image realism, often neglecting facial expressions as well as photometric consistency -- specifically attributes such as illumination and skin tone -- that are critical for applications like relighting, color constancy, and medical or affective analysis. In this work, we propose a feature-preserving anonymization framework that extends DeepPrivacy by incorporating dense facial landmarks to better retain expressions, and by introducing lightweight post-processing modules that ensure consistency in lighting direction and skin color. We further establish evaluation metrics specifically designed to quantify expression fidelity, lighting consistency, and color preservation, complementing standard measures of image realism, pose accuracy, and re-identification resistance. Experiments on the CelebA-HQ dataset demonstrate that our method produces anonymized faces with improved realism and significantly higher fidelity in expression, illumination, and skin tone compared to state-of-the-art baselines. These results underscore the importance of feature-aware anonymization as a step toward more useful, fair, and trustworthy privacy-preserving facial data.
Cross-Camera Distracted Driver Classification through Feature Disentanglement and Contrastive Learning
Nov 20, 2024



The classification of distracted drivers is pivotal for ensuring safe driving. Previous studies demonstrated the effectiveness of neural networks in automatically predicting driver distraction, fatigue, and potential hazards. However, recent research has uncovered a significant loss of accuracy in these models when applied to samples acquired under conditions that differ from the training data. In this paper, we introduce a robust model designed to withstand changes in camera position within the vehicle. Our Driver Behavior Monitoring Network (DBMNet) relies on a lightweight backbone and integrates a disentanglement module to discard camera view information from features, coupled with contrastive learning to enhance the encoding of various driver actions. Experiments conducted on the daytime and nighttime subsets of the 100-Driver dataset validate the effectiveness of our approach with an increment on average of 9\% in Top-1 accuracy in comparison with the state of the art. In addition, cross-dataset and cross-camera experiments conducted on three benchmark datasets, namely AUCDD-V1, EZZ2021 and SFD, demonstrate the superior generalization capability of the proposed method.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Improving Image Captioning Descriptiveness by Ranking and LLM-based Fusion
Jun 20, 2023



State-of-The-Art (SoTA) image captioning models often rely on the Microsoft COCO (MS-COCO) dataset for training. This dataset contains annotations provided by human annotators, who typically produce captions averaging around ten tokens. However, this constraint presents a challenge in effectively capturing complex scenes and conveying detailed information. Furthermore, captioning models tend to exhibit bias towards the ``average'' caption, which captures only the more general aspects. What would happen if we were able to automatically generate longer captions, thereby making them more detailed? Would these captions, evaluated by humans, be more or less representative of the image content compared to the original MS-COCO captions? In this paper, we present a novel approach to address previous challenges by showcasing how captions generated from different SoTA models can be effectively fused, resulting in richer captions. Our proposed method leverages existing models from the literature, eliminating the need for additional training. Instead, it utilizes an image-text based metric to rank the captions generated by SoTA models for a given image. Subsequently, the top two captions are fused using a Large Language Model (LLM). Experimental results demonstrate the effectiveness of our approach, as the captions generated by our model exhibit higher consistency with human judgment when evaluated on the MS-COCO test set. By combining the strengths of various SoTA models, our method enhances the quality and appeal of image captions, bridging the gap between automated systems and the rich, informative nature of human-generated descriptions. This advance opens up new possibilities for generating captions that are more suitable for the training of both vision-language and captioning models.
Semi-supervised cross-lingual speech emotion recognition
Jul 14, 2022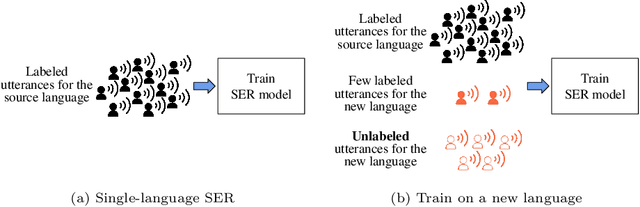
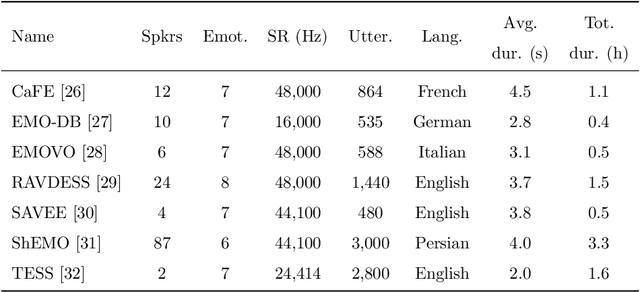
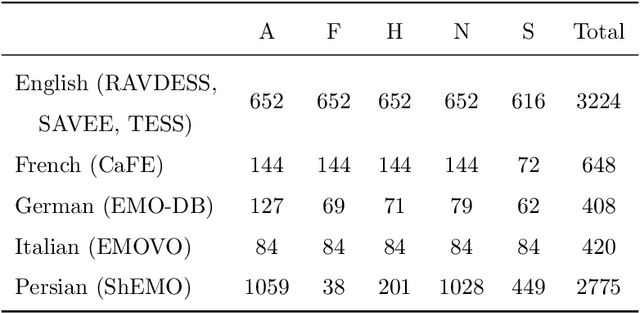
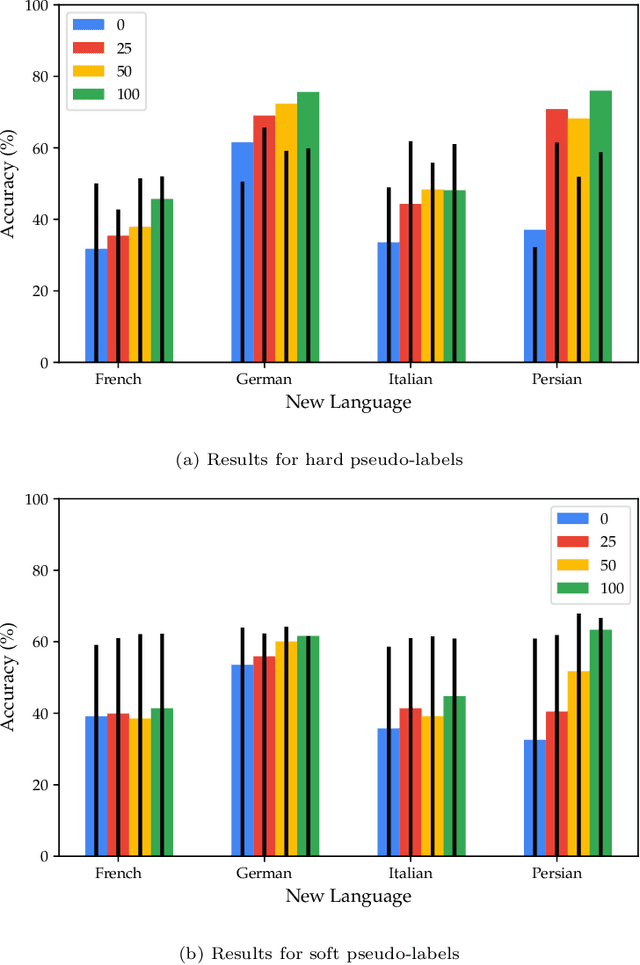
Speech emotion recognition (SER) on a single language has achieved remarkable results through deep learning approaches over the last decade. However, cross-lingual SER remains a challenge in real-world applications due to (i) a large difference between the source and target domain distributions, (ii) the availability of few labeled and many unlabeled utterances for the new language. Taking into account previous aspects, we propose a Semi-Supervised Learning (SSL) method for cross-lingual emotion recognition when a few labels from the new language are available. Based on a Convolutional Neural Network (CNN), our method adapts to a new language by exploiting a pseudo-labeling strategy for the unlabeled utterances. In particular, the use of a hard and soft pseudo-labels approach is investigated. We thoroughly evaluate the performance of the method in a speaker-independent setup on both the source and the new language and show its robustness across five languages belonging to different linguistic strains.
Understanding Aesthetics with Language: A Photo Critique Dataset for Aesthetic Assessment
Jun 17, 2022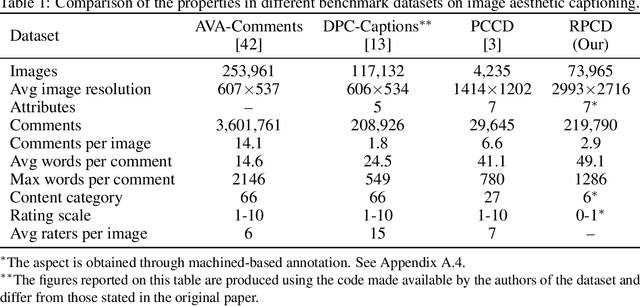

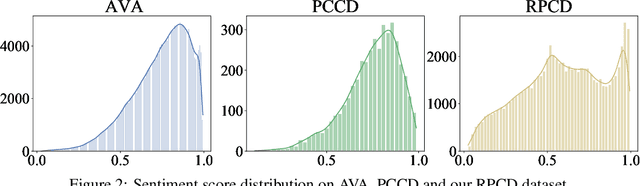
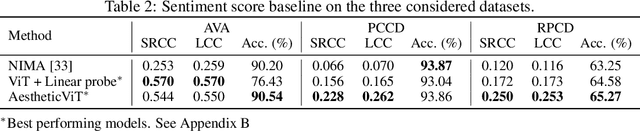
Computational inference of aesthetics is an ill-defined task due to its subjective nature. Many datasets have been proposed to tackle the problem by providing pairs of images and aesthetic scores based on human ratings. However, humans are better at expressing their opinion, taste, and emotions by means of language rather than summarizing them in a single number. In fact, photo critiques provide much richer information as they reveal how and why users rate the aesthetics of visual stimuli. In this regard, we propose the Reddit Photo Critique Dataset (RPCD), which contains tuples of image and photo critiques. RPCD consists of 74K images and 220K comments and is collected from a Reddit community used by hobbyists and professional photographers to improve their photography skills by leveraging constructive community feedback. The proposed dataset differs from previous aesthetics datasets mainly in three aspects, namely (i) the large scale of the dataset and the extension of the comments criticizing different aspects of the image, (ii) it contains mostly UltraHD images, and (iii) it can easily be extended to new data as it is collected through an automatic pipeline. To the best of our knowledge, in this work, we propose the first attempt to estimate the aesthetic quality of visual stimuli from the critiques. To this end, we exploit the polarity of the sentiment of criticism as an indicator of aesthetic judgment. We demonstrate how sentiment polarity correlates positively with the aesthetic judgment available for two aesthetic assessment benchmarks. Finally, we experiment with several models by using the sentiment scores as a target for ranking images. Dataset and baselines are available (https://github.com/mediatechnologycenter/aestheval).
Composition and Style Attributes Guided Image Aesthetic Assessment
Nov 08, 2021
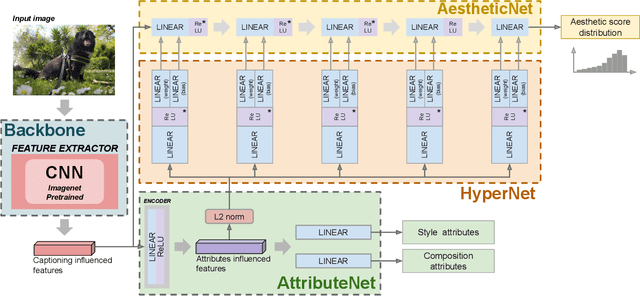

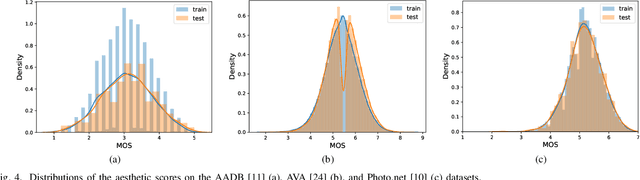
The aesthetic quality of an image is defined as the measure or appreciation of the beauty of an image. Aesthetics is inherently a subjective property but there are certain factors that influence it such as, the semantic content of the image, the attributes describing the artistic aspect, the photographic setup used for the shot, etc. In this paper we propose a method for the automatic prediction of the aesthetics of an image that is based on the analysis of the semantic content, the artistic style and the composition of the image. The proposed network includes: a pre-trained network for semantic features extraction (the Backbone); a Multi Layer Perceptron (MLP) network that relies on the Backbone features for the prediction of image attributes (the AttributeNet); a self-adaptive Hypernetwork that exploits the attributes prior encoded into the embedding generated by the AttributeNet to predict the parameters of the target network dedicated to aesthetic estimation (the AestheticNet). Given an image, the proposed multi-network is able to predict: style and composition attributes, and aesthetic score distribution. Results on three benchmark datasets demonstrate the effectiveness of the proposed method, while the ablation study gives a better understanding of the proposed network.
Disentangling Image Distortions in Deep Feature Space
Feb 26, 2020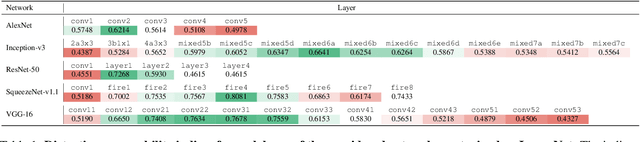

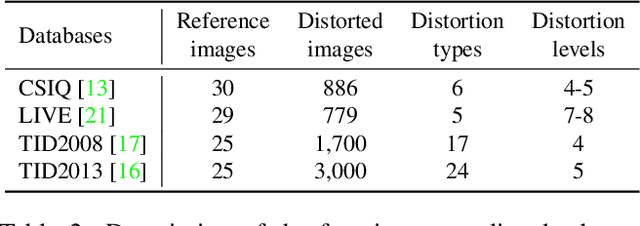
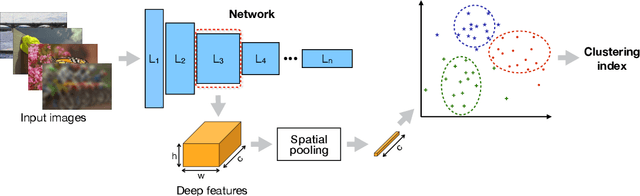
Previous literature suggests that perceptual similarity is an emergent property shared across deep visual representations. Experiments conducted on a dataset of human-judged image distortions have proven that deep features outperform, by a large margin, classic perceptual metrics. In this work we take a further step in the direction of a broader understanding of such property by analyzing the capability of deep visual representations to intrinsically characterize different types of image distortions. To this end, we firstly generate a number of synthetically distorted images by applying three mainstream distortion types to the LIVE database and then we analyze the features extracted by different layers of different Deep Network architectures. We observe that a dimension-reduced representation of the features extracted from a given layer permits to efficiently separate types of distortions in the feature space. Moreover, each network layer exhibits a different ability to separate between different types of distortions, and this ability varies according to the network architecture. As a further analysis, we evaluate the exploitation of features taken from the layer that better separates image distortions for: i) reduced-reference image quality assessment, and ii) distortion types and severity levels characterization on both single and multiple distortion databases. Results achieved on both tasks suggest that deep visual representations can be unsupervisedly employed to efficiently characterize various image distortions.
Benchmark Analysis of Representative Deep Neural Network Architectures
Oct 19, 2018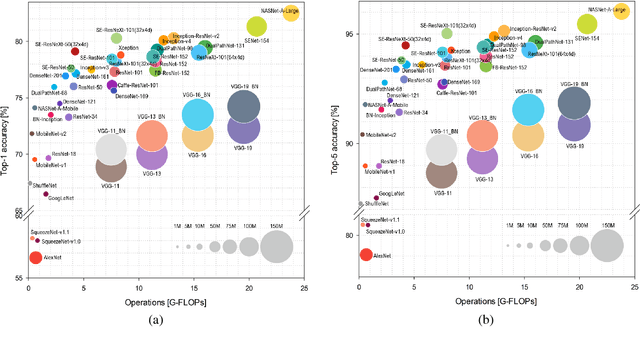
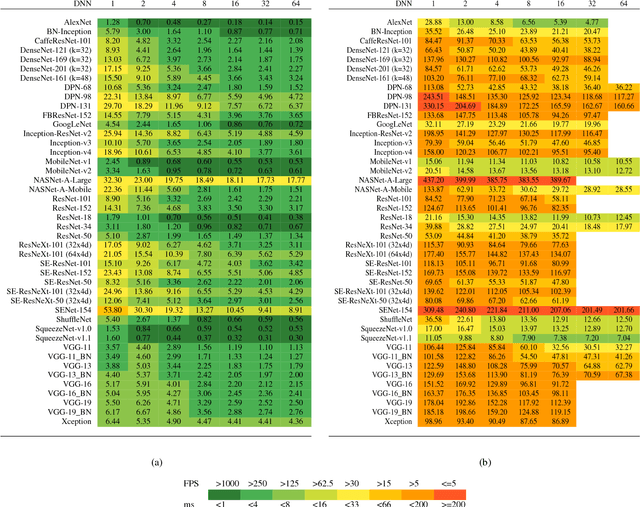
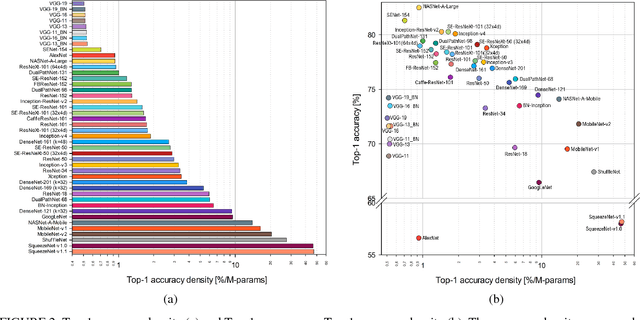
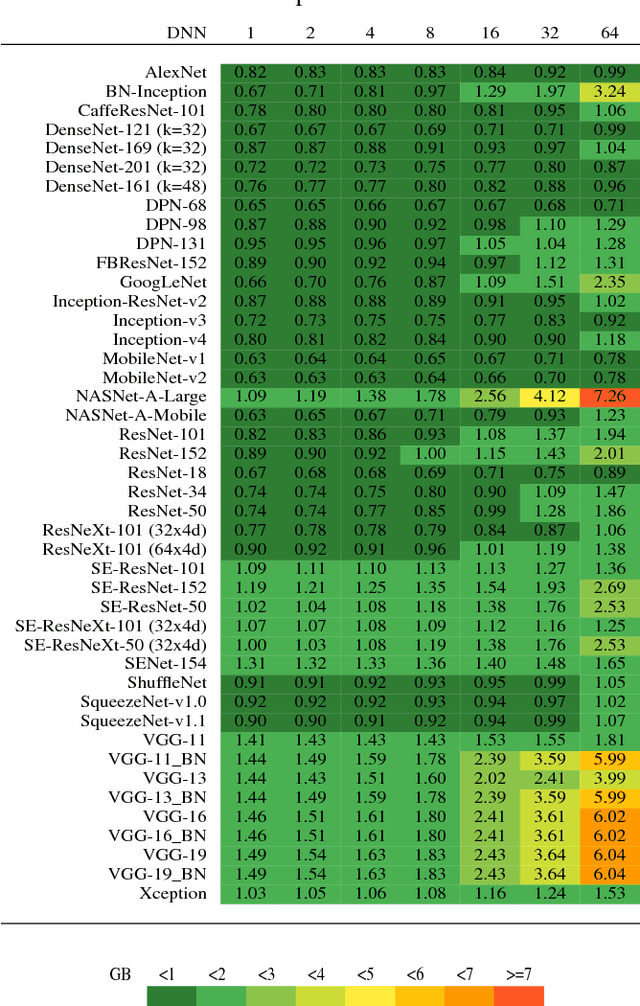
This work presents an in-depth analysis of the majority of the deep neural networks (DNNs) proposed in the state of the art for image recognition. For each DNN multiple performance indices are observed, such as recognition accuracy, model complexity, computational complexity, memory usage, and inference time. The behavior of such performance indices and some combinations of them are analyzed and discussed. To measure the indices we experiment the use of DNNs on two different computer architectures, a workstation equipped with a NVIDIA Titan X Pascal and an embedded system based on a NVIDIA Jetson TX1 board. This experimentation allows a direct comparison between DNNs running on machines with very different computational capacity. This study is useful for researchers to have a complete view of what solutions have been explored so far and in which research directions are worth exploring in the future; and for practitioners to select the DNN architecture(s) that better fit the resource constraints of practical deployments and applications. To complete this work, all the DNNs, as well as the software used for the analysis, are available online.
Aesthetics Assessment of Images Containing Faces
May 22, 2018
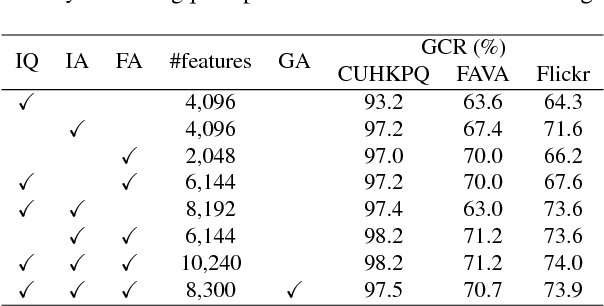
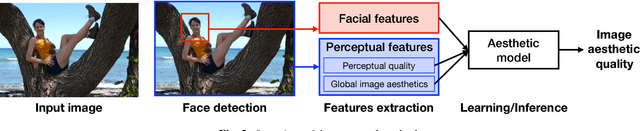
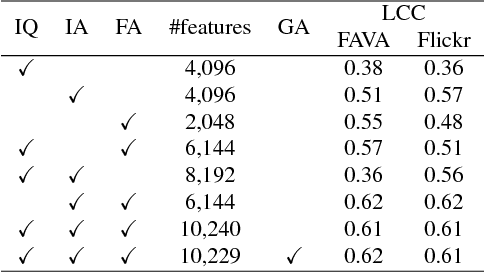
Recent research has widely explored the problem of aesthetics assessment of images with generic content. However, few approaches have been specifically designed to predict the aesthetic quality of images containing human faces, which make up a massive portion of photos in the web. This paper introduces a method for aesthetic quality assessment of images with faces. We exploit three different Convolutional Neural Networks to encode information regarding perceptual quality, global image aesthetics, and facial attributes; then, a model is trained to combine these features to explicitly predict the aesthetics of images containing faces. Experimental results show that our approach outperforms existing methods for both binary, i.e. low/high, and continuous aesthetic score prediction on four different databases in the state-of-the-art.