 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoARF: Controllable 3D Artistic Style Transfer for Radiance Fields
Apr 23, 2024Creating artistic 3D scenes can be time-consuming and requires specialized knowledge. To address this, recent works such as ARF, use a radiance field-based approach with style constraints to generate 3D scenes that resemble a style image provided by the user. However, these methods lack fine-grained control over the resulting scenes. In this paper, we introduce Controllable Artistic Radiance Fields (CoARF), a novel algorithm for controllable 3D scene stylization. CoARF enables style transfer for specified objects, compositional 3D style transfer and semantic-aware style transfer. We achieve controllability using segmentation masks with different label-dependent loss functions. We also propose a semantic-aware nearest neighbor matching algorithm to improve the style transfer quality. Our extensive experiments demonstrate that CoARF provides user-specified controllability of style transfer and superior style transfer quality with more precise feature matching.
Understanding Aesthetics with Language: A Photo Critique Dataset for Aesthetic Assessment
Jun 17, 2022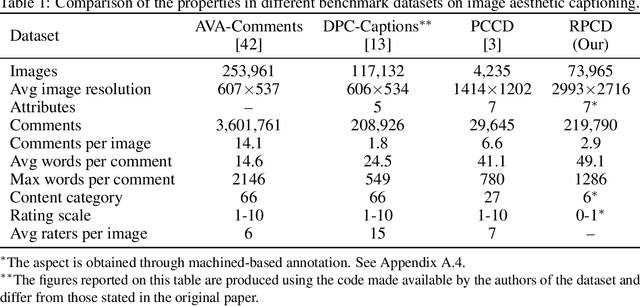

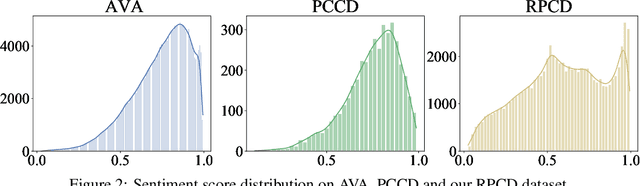
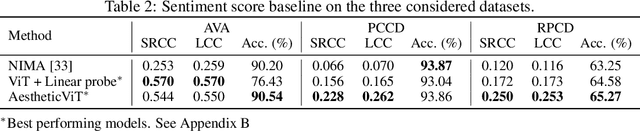
Computational inference of aesthetics is an ill-defined task due to its subjective nature. Many datasets have been proposed to tackle the problem by providing pairs of images and aesthetic scores based on human ratings. However, humans are better at expressing their opinion, taste, and emotions by means of language rather than summarizing them in a single number. In fact, photo critiques provide much richer information as they reveal how and why users rate the aesthetics of visual stimuli. In this regard, we propose the Reddit Photo Critique Dataset (RPCD), which contains tuples of image and photo critiques. RPCD consists of 74K images and 220K comments and is collected from a Reddit community used by hobbyists and professional photographers to improve their photography skills by leveraging constructive community feedback. The proposed dataset differs from previous aesthetics datasets mainly in three aspects, namely (i) the large scale of the dataset and the extension of the comments criticizing different aspects of the image, (ii) it contains mostly UltraHD images, and (iii) it can easily be extended to new data as it is collected through an automatic pipeline. To the best of our knowledge, in this work, we propose the first attempt to estimate the aesthetic quality of visual stimuli from the critiques. To this end, we exploit the polarity of the sentiment of criticism as an indicator of aesthetic judgment. We demonstrate how sentiment polarity correlates positively with the aesthetic judgment available for two aesthetic assessment benchmarks. Finally, we experiment with several models by using the sentiment scores as a target for ranking images. Dataset and baselines are available (https://github.com/mediatechnologycenter/aestheval).
Unsupervised Learning of Category-Specific Symmetric 3D Keypoints from Point Sets
Mar 17, 2020



Automatic discovery of category-specific 3D keypoints from a collection of objects of some category is a challenging problem. One reason is that not all objects in a category necessarily have the same semantic parts. The level of difficulty adds up further when objects are represented by 3D point clouds, with variations in shape and unknown coordinate frames. We define keypoints to be category-specific, if they meaningfully represent objects' shape and their correspondences can be simply established order-wise across all objects. This paper aims at learning category-specific 3D keypoints, in an unsupervised manner, using a collection of misaligned 3D point clouds of objects from an unknown category. In order to do so, we model shapes defined by the keypoints, within a category, using the symmetric linear basis shapes without assuming the plane of symmetry to be known. The usage of symmetry prior leads us to learn stable keypoints suitable for higher misalignments. To the best of our knowledge, this is the first work on learning such keypoints directly from 3D point clouds. Using categories from four benchmark datasets, we demonstrate the quality of our learned keypoints by quantitative and qualitative evaluations. Our experiments also show that the keypoints discovered by our method are geometrically and semantically consistent.
What's in my Room? Object Recognition on Indoor Panoramic Images
Oct 14, 2019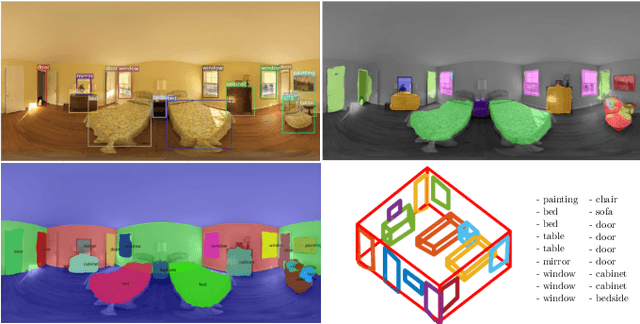

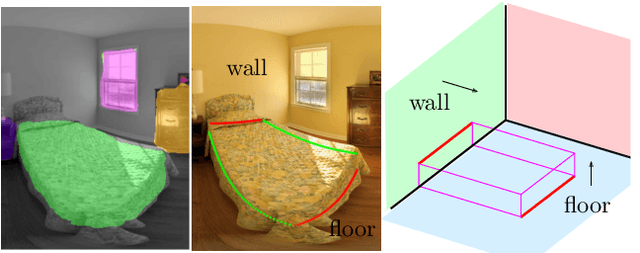
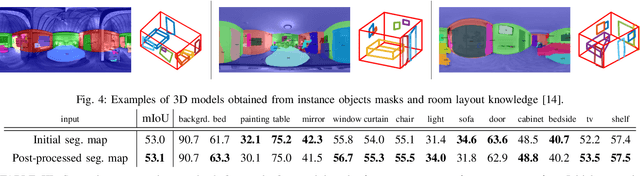
In the last few years, there has been a growing interest in taking advantage of the 360 panoramic images potential, while managing the new challenges they imply. While several tasks have been improved thanks to the contextual information these images offer, object recognition in indoor scenes still remains a challenging problem that has not been deeply investigated. This paper provides an object recognition system that performs object detection and semantic segmentation tasks by using a deep learning model adapted to match the nature of equirectangular images. From these results, instance segmentation masks are recovered, refined and transformed into 3D bounding boxes that are placed into the 3D model of the room. Quantitative and qualitative results support that our method outperforms the state of the art by a large margin and show a complete understanding of the main objects in indoor scenes.
Corners for Layout: End-to-End Layout Recovery from 360 Images
Mar 25, 2019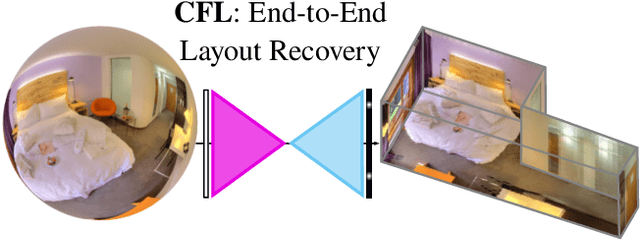

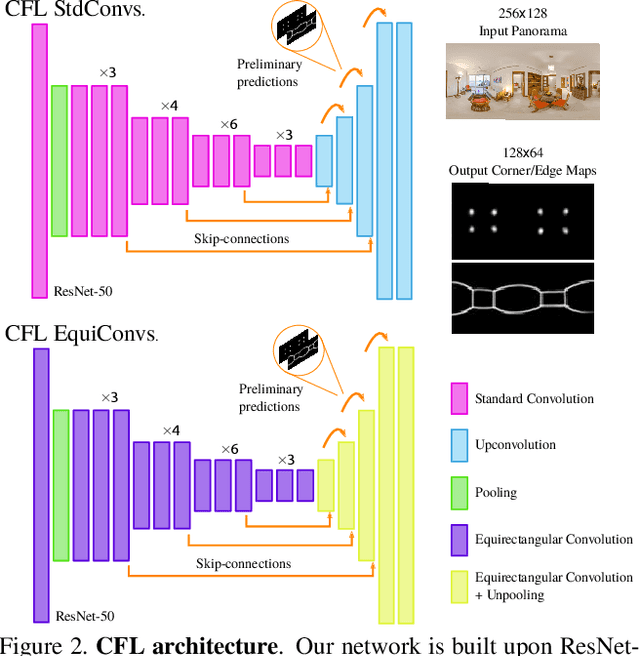

The problem of 3D layout recovery in indoor scenes has been a core research topic for over a decade. However, there are still several major challenges that remain unsolved. Among the most relevant ones, a major part of the state-of-the-art methods make implicit or explicit assumptions on the scenes -- e.g. box-shaped or Manhattan layouts. Also, current methods are computationally expensive and not suitable for real-time applications like robot navigation and AR/VR. In this work we present CFL (Corners for Layout), the first end-to-end model for 3D layout recovery on 360 images. Our experimental results show that we outperform the state of the art relaxing assumptions about the scene and at a lower cost. We also show that our model generalizes better to camera position variations than conventional approaches by using EquiConvs, a type of convolution applied directly on the sphere projection and hence invariant to the equirectangular distortions. CFL Webpage: https://cfernandezlab.github.io/CFL/
PanoRoom: From the Sphere to the 3D Layout
Aug 29, 2018


We propose a novel FCN able to work with omnidirectional images that outputs accurate probability maps representing the main structure of indoor scenes, which is able to generalize on different data. Our approach handles occlusions and recovers complex shaped rooms more faithful to the actual shape of the real scenes. We outperform the state of the art not only in accuracy of the 3D models but also in speed.
Layouts from Panoramic Images with Geometry and Deep Learning
Jun 21, 2018



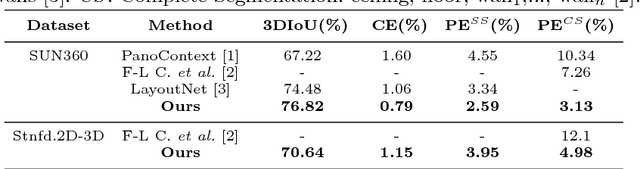
In this paper, we propose a novel procedure for 3D layout recovery of indoor scenes from single 360 degrees panoramic images. With such images, all scene is seen at once, allowing to recover closed geometries. Our method combines strategically the accuracy provided by geometric reasoning (lines and vanishing points) with the higher level of data abstraction and pattern recognition achieved by deep learning techniques (edge and normal maps). Thus, we extract structural corners from which we generate layout hypotheses of the room assuming Manhattan world. The best layout model is selected, achieving good performance on both simple rooms (box-type) and complex shaped rooms (with more than four walls). Experiments of the proposed approach are conducted within two public datasets, SUN360 and Stanford (2D-3D-S) demonstrating the advantages of estimating layouts by combining geometry and deep learning and the effectiveness of our proposal with respect to the state of the art.