 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAM-Convs: Camera-Aware Multi-Scale Convolutions for Single-View Depth
Apr 03, 2019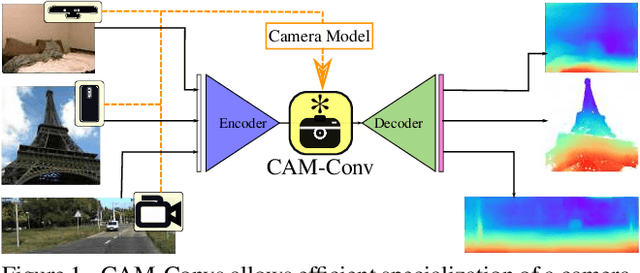

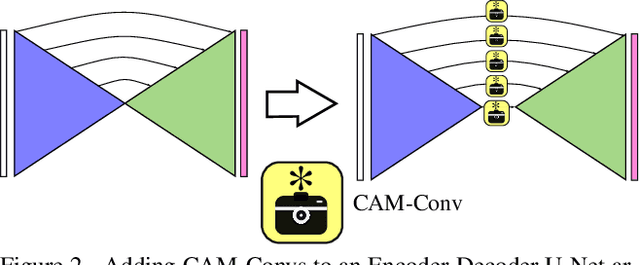
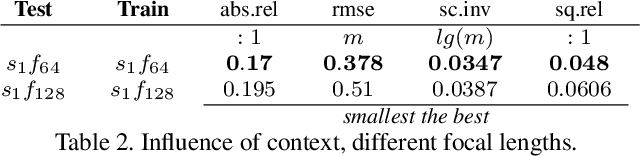
Single-view depth estimation suffers from the problem that a network trained on images from one camera does not generalize to images taken with a different camera model. Thus, changing the camera model requires collecting an entirely new training dataset. In this work, we propose a new type of convolution that can take the camera parameters into account, thus allowing neural networks to learn calibration-aware patterns. Experiments confirm that this improves the generalization capabilities of depth prediction networks considerably, and clearly outperforms the state of the art when the train and test images are acquired with different cameras.
Corners for Layout: End-to-End Layout Recovery from 360 Images
Mar 25, 2019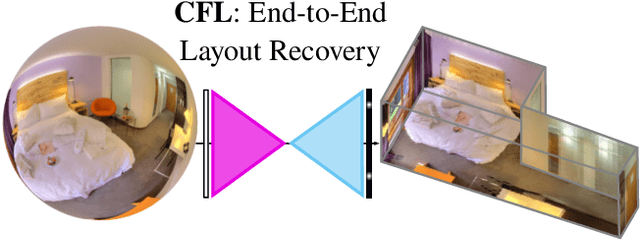

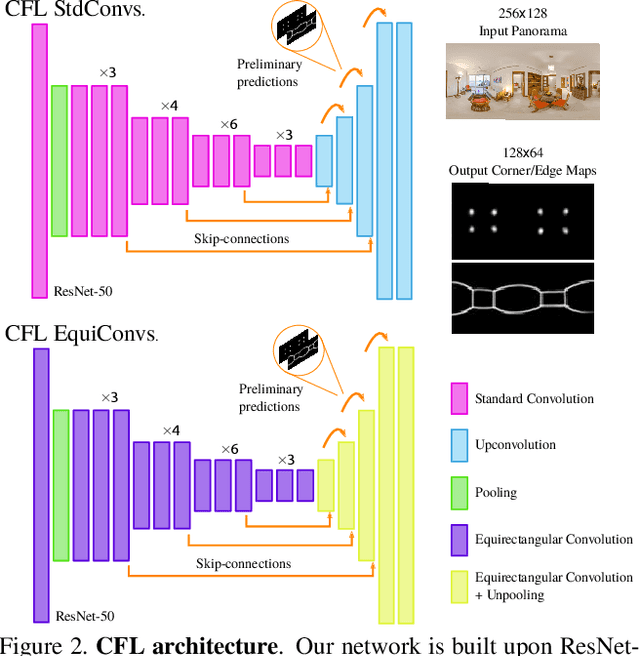

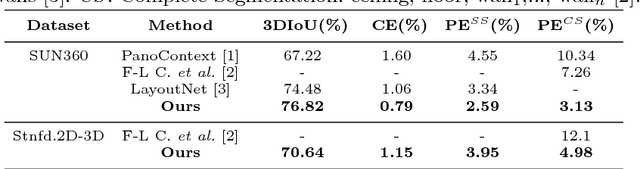
The problem of 3D layout recovery in indoor scenes has been a core research topic for over a decade. However, there are still several major challenges that remain unsolved. Among the most relevant ones, a major part of the state-of-the-art methods make implicit or explicit assumptions on the scenes -- e.g. box-shaped or Manhattan layouts. Also, current methods are computationally expensive and not suitable for real-time applications like robot navigation and AR/VR. In this work we present CFL (Corners for Layout), the first end-to-end model for 3D layout recovery on 360 images. Our experimental results show that we outperform the state of the art relaxing assumptions about the scene and at a lower cost. We also show that our model generalizes better to camera position variations than conventional approaches by using EquiConvs, a type of convolution applied directly on the sphere projection and hence invariant to the equirectangular distortions. CFL Webpage: https://cfernandezlab.github.io/CFL/
Condition-Invariant Multi-View Place Recognition
Feb 25, 2019



Visual place recognition is particularly challenging when places suffer changes in its appearance. Such changes are indeed common, e.g., due to weather, night/day or seasons. In this paper we leverage on recent research using deep networks, and explore how they can be improved by exploiting the temporal sequence information. Specifically, we propose 3 different alternatives (Descriptor Grouping, Fusion and Recurrent Descriptors) for deep networks to use several frames of a sequence. We show that our approaches produce more compact and best performing descriptors than single- and multi-view baselines in the literature in two public databases.
PanoRoom: From the Sphere to the 3D Layout
Aug 29, 2018


We propose a novel FCN able to work with omnidirectional images that outputs accurate probability maps representing the main structure of indoor scenes, which is able to generalize on different data. Our approach handles occlusions and recovers complex shaped rooms more faithful to the actual shape of the real scenes. We outperform the state of the art not only in accuracy of the 3D models but also in speed.