 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo-METAS: Egocentric online Multimodal Energy-efficient Temporal Action Segmentation benchmark
May 29, 2026To operate in the physical world, embodied agents must perceive their environment in an "always-on" fashion, selectively accessing the most informative sensors to balance energy constraints and task accuracy. Despite its importance for resource-constrained devices, energy-aware perception remains under-explored, with most prior work assuming unlimited compute. To address this, we introduce Ego-METAS: the first Egocentric online Multimodal Energy-efficient Temporal Action Segmentation benchmark. Ego-METAS provides a unified testbed of more than 100 hours of untrimmed egocentric video from EgoExo4D, CMU-MMAC, and CaptainCook4D, spanning 5 modalities (RGB, audio, gaze, IMU, and monochrome camera). We formulate an online temporal action segmentation task where models must dynamically select which sensors to activate at each timestep while strictly adhering to hardware-representative energy budgets. Alongside the benchmark, we release unified splits, cleaned annotations, pre-extracted features, and a diverse suite of baseline routing policies. Our evaluations show that optimal routing is highly scenario-dependent, and that existing policy-learning methods, designed primarily for trimmed clips, struggle to adapt to continuous, untrimmed environments. However, even simple dynamic fusion of complementary modalities (e.g., via random routing) proves critical for balancing predictive accuracy against strict energy budgets. Ultimately, Ego-METAS provides a standardized foundation to develop robust, cost-aware policies for autonomous, always-on embodied AI.
O-MaMa @ EgoExo4D Correspondence Challenge: Learning Object Mask Matching between Egocentric and Exocentric Views
Jun 06, 2025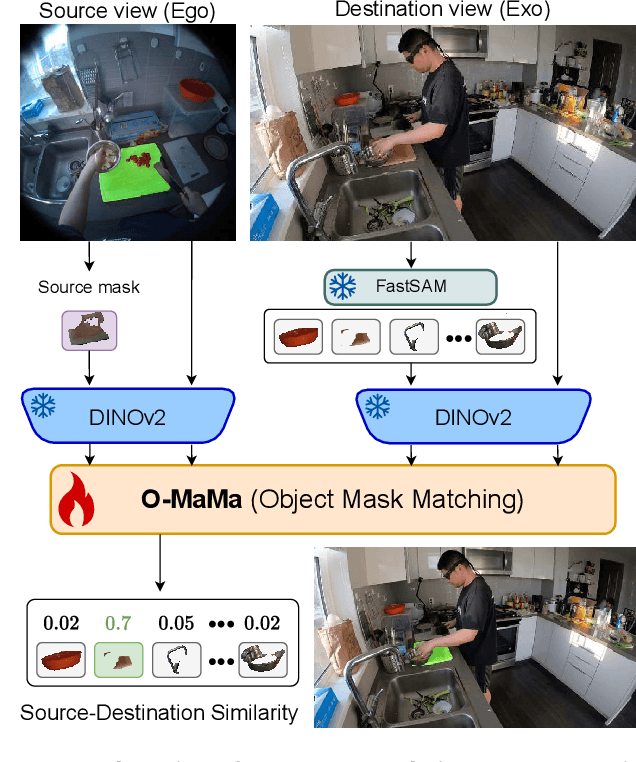
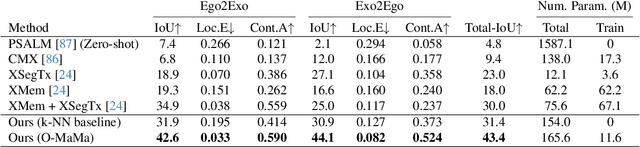

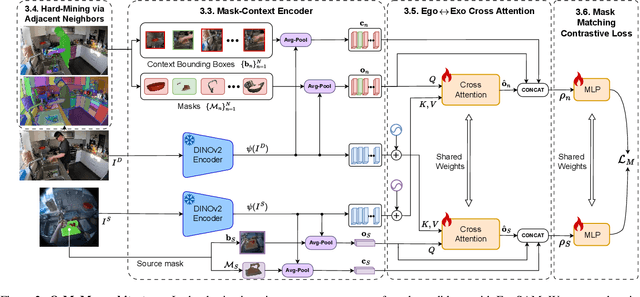
The goal of the correspondence task is to segment specific objects across different views. This technical report re-defines cross-image segmentation by treating it as a mask matching task. Our method consists of: (1) A Mask-Context Encoder that pools dense DINOv2 semantic features to obtain discriminative object-level representations from FastSAM mask candidates, (2) an Ego$\leftrightarrow$Exo Cross-Attention that fuses multi-perspective observations, (3) a Mask Matching contrastive loss that aligns cross-view features in a shared latent space, and (4) a Hard Negative Adjacent Mining strategy to encourage the model to better differentiate between nearby objects.
Knowledge Distillation for Multimodal Egocentric Action Recognition Robust to Missing Modalities
Apr 11, 2025Action recognition is an essential task in egocentric vision due to its wide range of applications across many fields. While deep learning methods have been proposed to address this task, most rely on a single modality, typically video. However, including additional modalities may improve the robustness of the approaches to common issues in egocentric videos, such as blurriness and occlusions. Recent efforts in multimodal egocentric action recognition often assume the availability of all modalities, leading to failures or performance drops when any modality is missing. To address this, we introduce an efficient multimodal knowledge distillation approach for egocentric action recognition that is robust to missing modalities (KARMMA) while still benefiting when multiple modalities are available. Our method focuses on resource-efficient development by leveraging pre-trained models as unimodal feature extractors in our teacher model, which distills knowledge into a much smaller and faster student model. Experiments on the Epic-Kitchens and Something-Something datasets demonstrate that our student model effectively handles missing modalities while reducing its accuracy drop in this scenario.
Convolution kernel adaptation to calibrated fisheye
Feb 02, 2024Convolution kernels are the basic structural component of convolutional neural networks (CNNs). In the last years there has been a growing interest in fisheye cameras for many applications. However, the radially symmetric projection model of these cameras produces high distortions that affect the performance of CNNs, especially when the field of view is very large. In this work, we tackle this problem by proposing a method that leverages the calibration of cameras to deform the convolution kernel accordingly and adapt to the distortion. That way, the receptive field of the convolution is similar to standard convolutions in perspective images, allowing us to take advantage of pre-trained networks in large perspective datasets. We show how, with just a brief fine-tuning stage in a small dataset, we improve the performance of the network for the calibrated fisheye with respect to standard convolutions in depth estimation and semantic segmentation.
Floor extraction and door detection for visually impaired guidance
Jan 30, 2024Finding obstacle-free paths in unknown environments is a big navigation issue for visually impaired people and autonomous robots. Previous works focus on obstacle avoidance, however they do not have a general view of the environment they are moving in. New devices based on computer vision systems can help impaired people to overcome the difficulties of navigating in unknown environments in safe conditions. In this work it is proposed a combination of sensors and algorithms that can lead to the building of a navigation system for visually impaired people. Based on traditional systems that use RGB-D cameras for obstacle avoidance, it is included and combined the information of a fish-eye camera, which will give a better understanding of the user's surroundings. The combination gives robustness and reliability to the system as well as a wide field of view that allows to obtain many information from the environment. This combination of sensors is inspired by human vision where the center of the retina (fovea) provides more accurate information than the periphery, where humans have a wider field of view. The proposed system is mounted on a wearable device that provides the obstacle-free zones of the scene, allowing the planning of trajectories for people guidance.
Augmented reality navigation system for visual prosthesis
Sep 30, 2021
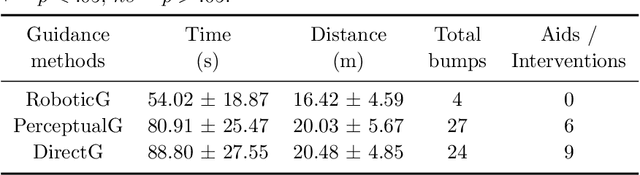

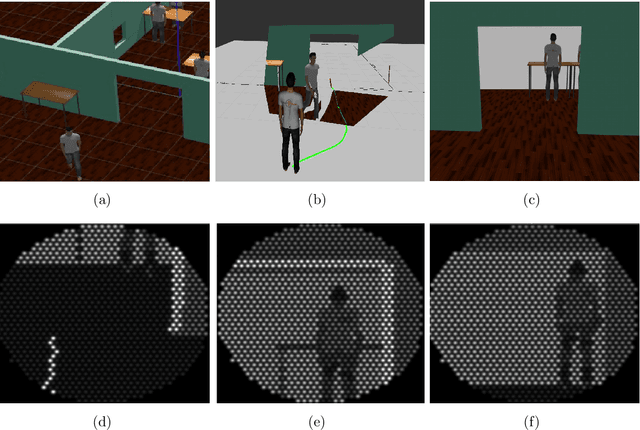
The visual functions of visual prostheses such as field of view, resolution and dynamic range, seriously restrict the person's ability to navigate in unknown environments. Implanted patients still require constant assistance for navigating from one location to another. Hence, there is a need for a system that is able to assist them safely during their journey. In this work, we propose an augmented reality navigation system for visual prosthesis that incorporates a software of reactive navigation and path planning which guides the subject through convenient, obstacle-free route. It consists on four steps: locating the subject on a map, planning the subject trajectory, showing it to the subject and re-planning without obstacles. We have also designed a simulated prosthetic vision environment which allows us to systematically study navigation performance. Twelve subjects participated in the experiment. Subjects were guided by the augmented reality navigation system and their instruction was to navigate through different environments until they reached two goals, cross the door and find an object (bin), as fast and accurately as possible. Results show how our augmented navigation system help navigation performance by reducing the time and distance to reach the goals, even significantly reducing the number of obstacles collisions, compared to other baseline methods.
Corners for Layout: End-to-End Layout Recovery from 360 Images
Mar 25, 2019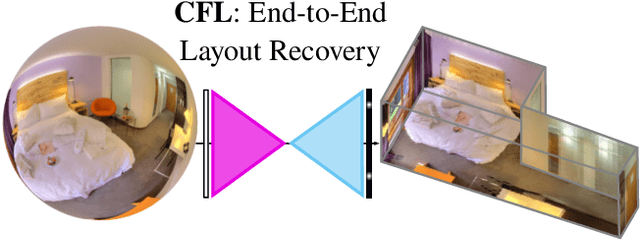

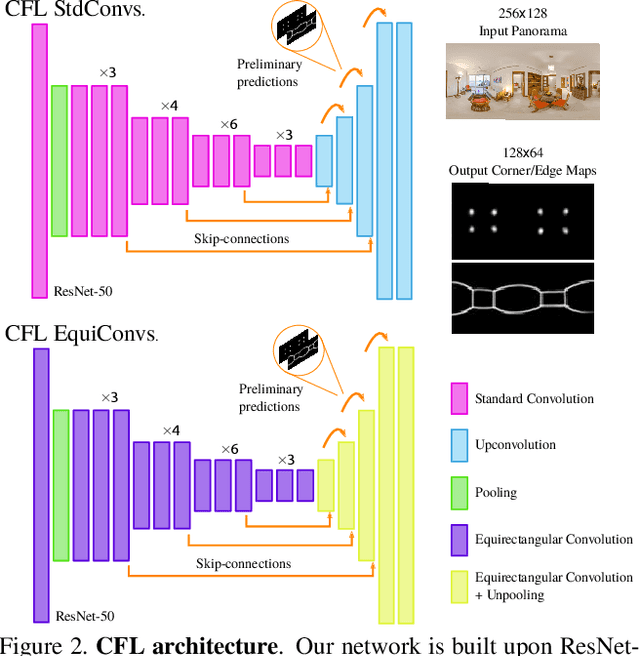

The problem of 3D layout recovery in indoor scenes has been a core research topic for over a decade. However, there are still several major challenges that remain unsolved. Among the most relevant ones, a major part of the state-of-the-art methods make implicit or explicit assumptions on the scenes -- e.g. box-shaped or Manhattan layouts. Also, current methods are computationally expensive and not suitable for real-time applications like robot navigation and AR/VR. In this work we present CFL (Corners for Layout), the first end-to-end model for 3D layout recovery on 360 images. Our experimental results show that we outperform the state of the art relaxing assumptions about the scene and at a lower cost. We also show that our model generalizes better to camera position variations than conventional approaches by using EquiConvs, a type of convolution applied directly on the sphere projection and hence invariant to the equirectangular distortions. CFL Webpage: https://cfernandezlab.github.io/CFL/
PanoRoom: From the Sphere to the 3D Layout
Aug 29, 2018


We propose a novel FCN able to work with omnidirectional images that outputs accurate probability maps representing the main structure of indoor scenes, which is able to generalize on different data. Our approach handles occlusions and recovers complex shaped rooms more faithful to the actual shape of the real scenes. We outperform the state of the art not only in accuracy of the 3D models but also in speed.
Layouts from Panoramic Images with Geometry and Deep Learning
Jun 21, 2018



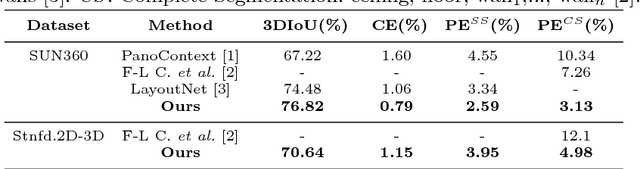
In this paper, we propose a novel procedure for 3D layout recovery of indoor scenes from single 360 degrees panoramic images. With such images, all scene is seen at once, allowing to recover closed geometries. Our method combines strategically the accuracy provided by geometric reasoning (lines and vanishing points) with the higher level of data abstraction and pattern recognition achieved by deep learning techniques (edge and normal maps). Thus, we extract structural corners from which we generate layout hypotheses of the room assuming Manhattan world. The best layout model is selected, achieving good performance on both simple rooms (box-type) and complex shaped rooms (with more than four walls). Experiments of the proposed approach are conducted within two public datasets, SUN360 and Stanford (2D-3D-S) demonstrating the advantages of estimating layouts by combining geometry and deep learning and the effectiveness of our proposal with respect to the state of the art.