 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
Mar 17, 2026We present V-JEPA 2.1, a family of self-supervised models that learn dense, high-quality visual representations for both images and videos while retaining strong global scene understanding. The approach combines four key components. First, a dense predictive loss uses a masking-based objective in which both visible and masked tokens contribute to the training signal, encouraging explicit spatial and temporal grounding. Second, deep self-supervision applies the self-supervised objective hierarchically across multiple intermediate encoder layers to improve representation quality. Third, multi-modal tokenizers enable unified training across images and videos. Finally, the model benefits from effective scaling in both model capacity and training data. Together, these design choices produce representations that are spatially structured, semantically coherent, and temporally consistent. Empirically, V-JEPA 2.1 achieves state-of-the-art performance on several challenging benchmarks, including 7.71 mAP on Ego4D for short-term object-interaction anticipation and 40.8 Recall@5 on EPIC-KITCHENS for high-level action anticipation, as well as a 20-point improvement in real-robot grasping success rate over V-JEPA-2 AC. The model also demonstrates strong performance in robotic navigation (5.687 ATE on TartanDrive), depth estimation (0.307 RMSE on NYUv2 with a linear probe), and global recognition (77.7 on Something-Something-V2). These results show that V-JEPA 2.1 significantly advances the state of the art in dense visual understanding and world modeling.
O-MaMa @ EgoExo4D Correspondence Challenge: Learning Object Mask Matching between Egocentric and Exocentric Views
Jun 06, 2025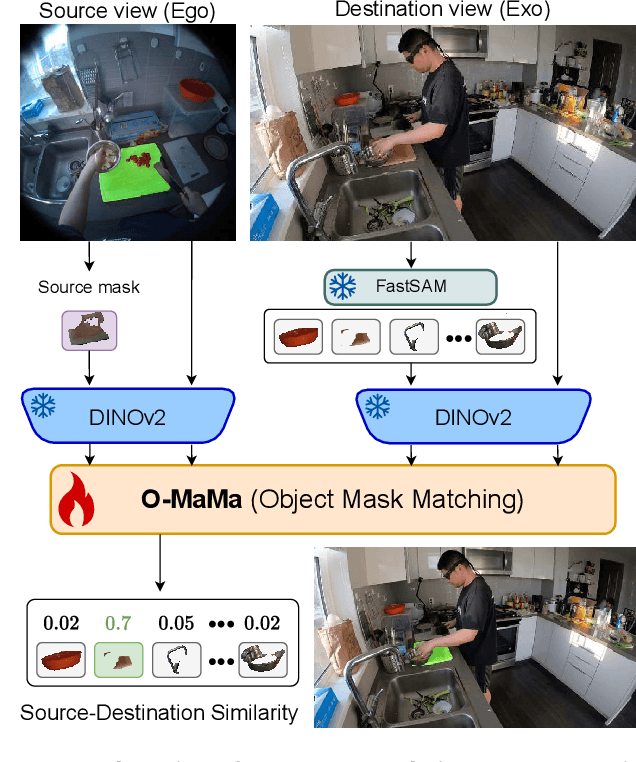
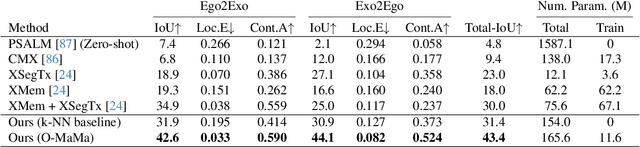

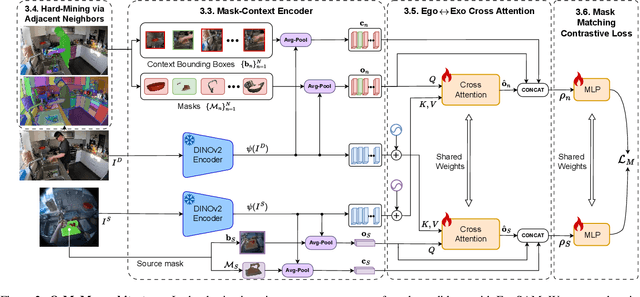
The goal of the correspondence task is to segment specific objects across different views. This technical report re-defines cross-image segmentation by treating it as a mask matching task. Our method consists of: (1) A Mask-Context Encoder that pools dense DINOv2 semantic features to obtain discriminative object-level representations from FastSAM mask candidates, (2) an Ego$\leftrightarrow$Exo Cross-Attention that fuses multi-perspective observations, (3) a Mask Matching contrastive loss that aligns cross-view features in a shared latent space, and (4) a Hard Negative Adjacent Mining strategy to encourage the model to better differentiate between nearby objects.
DIV-FF: Dynamic Image-Video Feature Fields For Environment Understanding in Egocentric Videos
Mar 11, 2025Environment understanding in egocentric videos is an important step for applications like robotics, augmented reality and assistive technologies. These videos are characterized by dynamic interactions and a strong dependence on the wearer engagement with the environment. Traditional approaches often focus on isolated clips or fail to integrate rich semantic and geometric information, limiting scene comprehension. We introduce Dynamic Image-Video Feature Fields (DIV FF), a framework that decomposes the egocentric scene into persistent, dynamic, and actor based components while integrating both image and video language features. Our model enables detailed segmentation, captures affordances, understands the surroundings and maintains consistent understanding over time. DIV-FF outperforms state-of-the-art methods, particularly in dynamically evolving scenarios, demonstrating its potential to advance long term, spatio temporal scene understanding.
ZARRIO @ Ego4D Short Term Object Interaction Anticipation Challenge: Leveraging Affordances and Attention-based models for STA
Jul 05, 2024Short-Term object-interaction Anticipation (STA) consists of detecting the location of the next-active objects, the noun and verb categories of the interaction, and the time to contact from the observation of egocentric video. We propose STAformer, a novel attention-based architecture integrating frame-guided temporal pooling, dual image-video attention, and multi-scale feature fusion to support STA predictions from an image-input video pair. Moreover, we introduce two novel modules to ground STA predictions on human behavior by modeling affordances. First, we integrate an environment affordance model which acts as a persistent memory of interactions that can take place in a given physical scene. Second, we predict interaction hotspots from the observation of hands and object trajectories, increasing confidence in STA predictions localized around the hotspot. On the test set, our results obtain a final 33.5 N mAP, 17.25 N+V mAP, 11.77 N+{\delta} mAP and 6.75 Overall top-5 mAP metric when trained on the v2 training dataset.
CARLOR @ Ego4D Step Grounding Challenge: Bayesian temporal-order priors for test time refinement
Jun 13, 2024
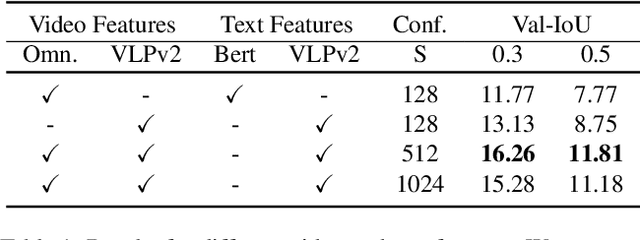


The goal of the Step Grounding task is to locate temporal boundaries of activities based on natural language descriptions. This technical report introduces a Bayesian-VSLNet to address the challenge of identifying such temporal segments in lengthy, untrimmed egocentric videos. Our model significantly improves upon traditional models by incorporating a novel Bayesian temporal-order prior during inference, enhancing the accuracy of moment predictions. This prior adjusts for cyclic and repetitive actions within videos. Our evaluations demonstrate superior performance over existing methods, achieving state-of-the-art results on the Ego4D Goal-Step dataset with a 35.18 Recall Top-1 at 0.3 IoU and 20.48 Recall Top-1 at 0.5 IoU on the test set.
AFF-ttention! Affordances and Attention models for Short-Term Object Interaction Anticipation
Jun 03, 2024



Short-Term object-interaction Anticipation consists of detecting the location of the next-active objects, the noun and verb categories of the interaction, and the time to contact from the observation of egocentric video. This ability is fundamental for wearable assistants or human robot interaction to understand the user goals, but there is still room for improvement to perform STA in a precise and reliable way. In this work, we improve the performance of STA predictions with two contributions: 1. We propose STAformer, a novel attention-based architecture integrating frame guided temporal pooling, dual image-video attention, and multiscale feature fusion to support STA predictions from an image-input video pair. 2. We introduce two novel modules to ground STA predictions on human behavior by modeling affordances.First, we integrate an environment affordance model which acts as a persistent memory of interactions that can take place in a given physical scene. Second, we predict interaction hotspots from the observation of hands and object trajectories, increasing confidence in STA predictions localized around the hotspot. Our results show significant relative Overall Top-5 mAP improvements of up to +45% on Ego4D and +42% on a novel set of curated EPIC-Kitchens STA labels. We will release the code, annotations, and pre extracted affordances on Ego4D and EPIC- Kitchens to encourage future research in this area.
Multi-label affordance mapping from egocentric vision
Sep 05, 2023Accurate affordance detection and segmentation with pixel precision is an important piece in many complex systems based on interactions, such as robots and assitive devices. We present a new approach to affordance perception which enables accurate multi-label segmentation. Our approach can be used to automatically extract grounded affordances from first person videos of interactions using a 3D map of the environment providing pixel level precision for the affordance location. We use this method to build the largest and most complete dataset on affordances based on the EPIC-Kitchen dataset, EPIC-Aff, which provides interaction-grounded, multi-label, metric and spatial affordance annotations. Then, we propose a new approach to affordance segmentation based on multi-label detection which enables multiple affordances to co-exists in the same space, for example if they are associated with the same object. We present several strategies of multi-label detection using several segmentation architectures. The experimental results highlight the importance of the multi-label detection. Finally, we show how our metric representation can be exploited for build a map of interaction hotspots in spatial action-centric zones and use that representation to perform a task-oriented navigation.
Robust Fusion for Bayesian Semantic Mapping
Mar 14, 2023



The integration of semantic information in a map allows robots to understand better their environment and make high-level decisions. In the last few years, neural networks have shown enormous progress in their perception capabilities. However, when fusing multiple observations from a neural network in a semantic map, its inherent overconfidence with unknown data gives too much weight to the outliers and decreases the robustness of the resulting map. In this work, we propose a novel robust fusion method to combine multiple Bayesian semantic predictions. Our method uses the uncertainty estimation provided by a Bayesian neural network to calibrate the way in which the measurements are fused. This is done by regularizing the observations to mitigate the problem of overconfident outlier predictions and using the epistemic uncertainty to weigh their influence in the fusion, resulting in a different formulation of the probability distributions. We validate our robust fusion strategy by performing experiments on photo-realistic simulated environments and real scenes. In both cases, we use a network trained on different data to expose the model to varying data distributions. The results show that considering the model's uncertainty and regularizing the probability distribution of the observations distribution results in a better semantic segmentation performance and more robustness to outliers, compared with other methods.
Bayesian Deep Learning for Affordance Segmentation in images
Mar 02, 2023Affordances are a fundamental concept in robotics since they relate available actions for an agent depending on its sensory-motor capabilities and the environment. We present a novel Bayesian deep network to detect affordances in images, at the same time that we quantify the distribution of the aleatoric and epistemic variance at the spatial level. We adapt the Mask-RCNN architecture to learn a probabilistic representation using Monte Carlo dropout. Our results outperform the state-of-the-art of deterministic networks. We attribute this improvement to a better probabilistic feature space representation on the encoder and the Bayesian variability induced at the mask generation, which adapts better to the object contours. We also introduce the new Probability-based Mask Quality measure that reveals the semantic and spatial differences on a probabilistic instance segmentation model. We modify the existing Probabilistic Detection Quality metric by comparing the binary masks rather than the predicted bounding boxes, achieving a finer-grained evaluation of the probabilistic segmentation. We find aleatoric variance in the contours of the objects due to the camera noise, while epistemic variance appears in visual challenging pixels.
Bayesian deep learning of affordances from RGB images
Sep 27, 2021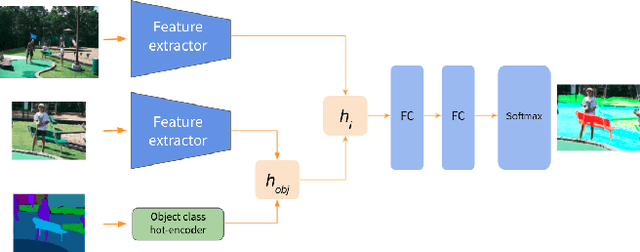
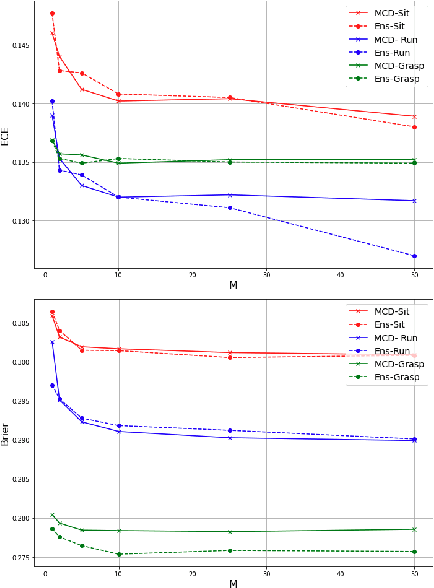
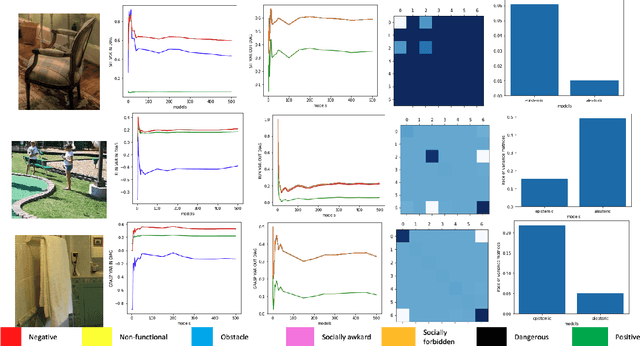
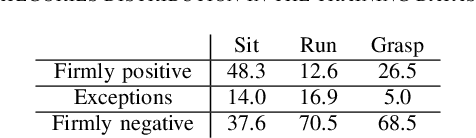
Autonomous agents, such as robots or intelligent devices, need to understand how to interact with objects and its environment. Affordances are defined as the relationships between an agent, the objects, and the possible future actions in the environment. In this paper, we present a Bayesian deep learning method to predict the affordances available in the environment directly from RGB images. Based on previous work on socially accepted affordances, our model is based on a multiscale CNN that combines local and global information from the object and the full image. However, previous works assume a deterministic model, but uncertainty quantification is fundamental for robust detection, affordance-based reason, continual learning, etc. Our Bayesian model is able to capture both the aleatoric uncertainty from the scene and the epistemic uncertainty associated with the model and previous learning process. For comparison, we estimate the uncertainty using two state-of-the-art techniques: Monte Carlo dropout and deep ensembles. We also compare different types of CNN encoders for feature extraction. We have performed several experiments on an affordance database on socially acceptable behaviours and we have shown improved performance compared with previous works. Furthermore, the uncertainty estimation is consistent with the the type of objects and scenarios. Our results show a marginal better performance of deep ensembles, compared to MC-dropout on the Brier score and the Expected Calibration Error.