Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARLOR @ Ego4D Step Grounding Challenge: Bayesian temporal-order priors for test time refinement
Paper and Code
Jun 13, 2024
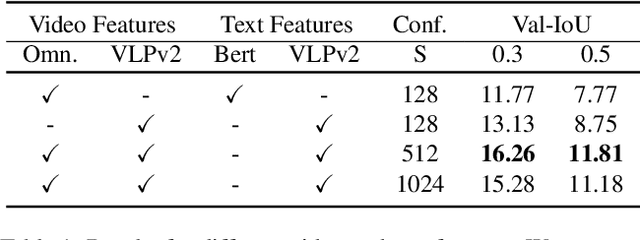


The goal of the Step Grounding task is to locate temporal boundaries of activities based on natural language descriptions. This technical report introduces a Bayesian-VSLNet to address the challenge of identifying such temporal segments in lengthy, untrimmed egocentric videos. Our model significantly improves upon traditional models by incorporating a novel Bayesian temporal-order prior during inference, enhancing the accuracy of moment predictions. This prior adjusts for cyclic and repetitive actions within videos. Our evaluations demonstrate superior performance over existing methods, achieving state-of-the-art results on the Ego4D Goal-Step dataset with a 35.18 Recall Top-1 at 0.3 IoU and 20.48 Recall Top-1 at 0.5 IoU on the test set.
View paper on