 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Affordances and Attention models for Short-Term Object Interaction Anticipation
Feb 16, 2026Short Term object-interaction Anticipation consists in detecting the location of the next active objects, the noun and verb categories of the interaction, as well as the time to contact from the observation of egocentric video. This ability is fundamental for wearable assistants to understand user goals and provide timely assistance, or to enable human-robot interaction. In this work, we present a method to improve the performance of STA predictions. Our contributions are two-fold: 1 We propose STAformer and STAformer plus plus, two novel attention-based architectures integrating frame-guided temporal pooling, dual image-video attention, and multiscale feature fusion to support STA predictions from an image-input video pair; 2 We introduce two novel modules to ground STA predictions on human behavior by modeling affordances. First, we integrate an environment affordance model which acts as a persistent memory of interactions that can take place in a given physical scene. We explore how to integrate environment affordances via simple late fusion and with an approach which adaptively learns how to best fuse affordances with end-to-end predictions. Second, we predict interaction hotspots from the observation of hands and object trajectories, increasing confidence in STA predictions localized around the hotspot. Our results show significant improvements on Overall Top-5 mAP, with gain up to +23p.p on Ego4D and +31p.p on a novel set of curated EPIC-Kitchens STA labels. We released the code, annotations, and pre-extracted affordances on Ego4D and EPIC-Kitchens to encourage future research in this area.
O-MaMa @ EgoExo4D Correspondence Challenge: Learning Object Mask Matching between Egocentric and Exocentric Views
Jun 06, 2025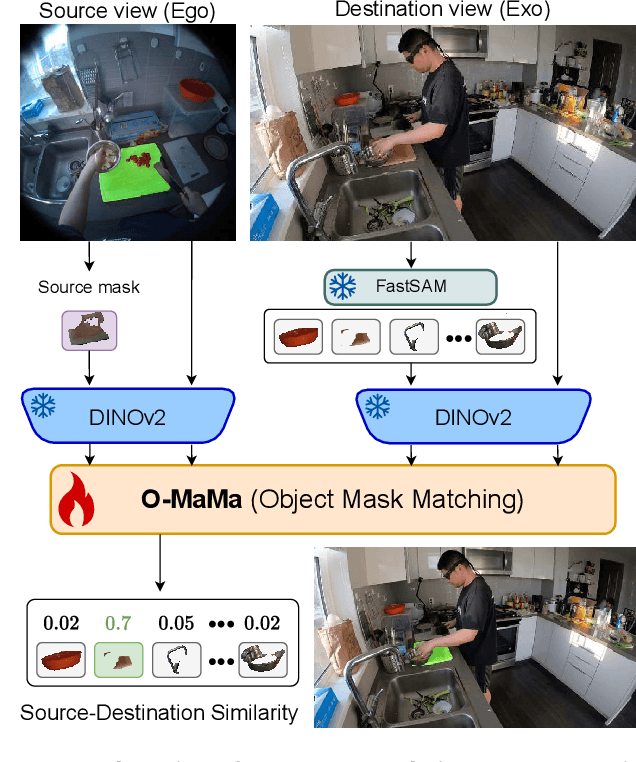
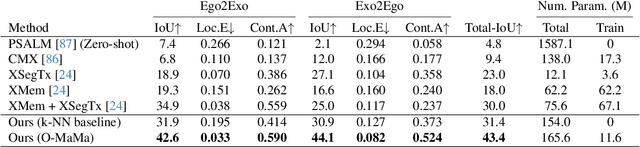

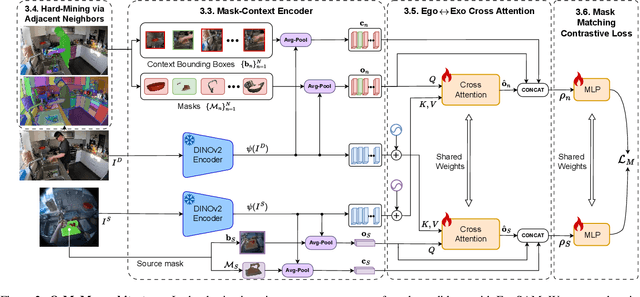
The goal of the correspondence task is to segment specific objects across different views. This technical report re-defines cross-image segmentation by treating it as a mask matching task. Our method consists of: (1) A Mask-Context Encoder that pools dense DINOv2 semantic features to obtain discriminative object-level representations from FastSAM mask candidates, (2) an Ego$\leftrightarrow$Exo Cross-Attention that fuses multi-perspective observations, (3) a Mask Matching contrastive loss that aligns cross-view features in a shared latent space, and (4) a Hard Negative Adjacent Mining strategy to encourage the model to better differentiate between nearby objects.
FALCONEye: Finding Answers and Localizing Content in ONE-hour-long videos with multi-modal LLMs
Mar 25, 2025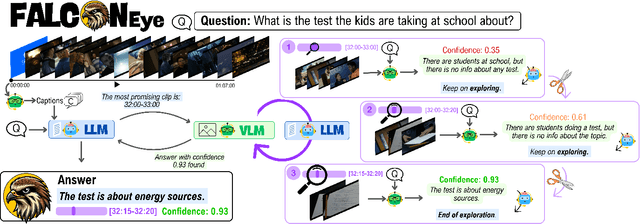
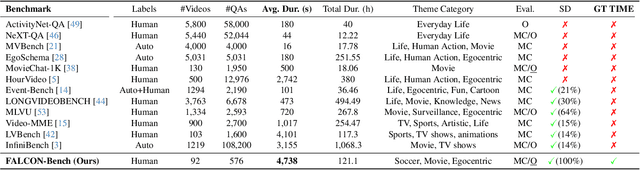
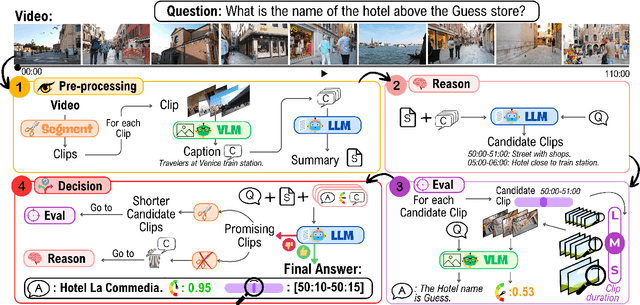
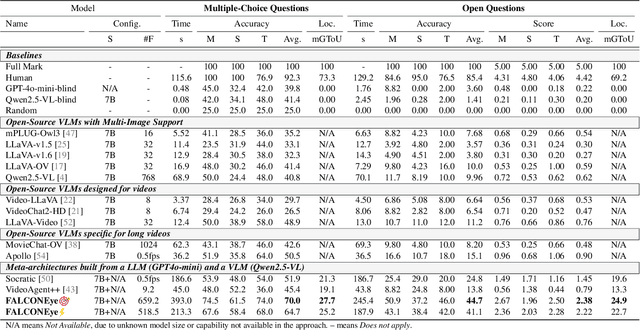
Information retrieval in hour-long videos presents a significant challenge, even for state-of-the-art Vision-Language Models (VLMs), particularly when the desired information is localized within a small subset of frames. Long video data presents challenges for VLMs due to context window limitations and the difficulty of pinpointing frames containing the answer. Our novel video agent, FALCONEye, combines a VLM and a Large Language Model (LLM) to search relevant information along the video, and locate the frames with the answer. FALCONEye novelty relies on 1) the proposed meta-architecture, which is better suited to tackle hour-long videos compared to short video approaches in the state-of-the-art; 2) a new efficient exploration algorithm to locate the information using short clips, captions and answer confidence; and 3) our state-of-the-art VLMs calibration analysis for the answer confidence. Our agent is built over a small-size VLM and a medium-size LLM being accessible to run on standard computational resources. We also release FALCON-Bench, a benchmark to evaluate long (average > 1 hour) Video Answer Search challenges, highlighting the need for open-ended question evaluation. Our experiments show FALCONEye's superior performance than the state-of-the-art in FALCON-Bench, and similar or better performance in related benchmarks.
DIV-FF: Dynamic Image-Video Feature Fields For Environment Understanding in Egocentric Videos
Mar 11, 2025Environment understanding in egocentric videos is an important step for applications like robotics, augmented reality and assistive technologies. These videos are characterized by dynamic interactions and a strong dependence on the wearer engagement with the environment. Traditional approaches often focus on isolated clips or fail to integrate rich semantic and geometric information, limiting scene comprehension. We introduce Dynamic Image-Video Feature Fields (DIV FF), a framework that decomposes the egocentric scene into persistent, dynamic, and actor based components while integrating both image and video language features. Our model enables detailed segmentation, captures affordances, understands the surroundings and maintains consistent understanding over time. DIV-FF outperforms state-of-the-art methods, particularly in dynamically evolving scenarios, demonstrating its potential to advance long term, spatio temporal scene understanding.
Influence of field of view in visual prostheses design: Analysis with a VR system
Jan 28, 2025Visual prostheses are designed to restore partial functional vision in patients with total vision loss. Retinal visual prostheses provide limited capabilities as a result of low resolution, limited field of view and poor dynamic range. Understanding the influence of these parameters in the perception results can guide prostheses research and design. In this work, we evaluate the influence of field of view with respect to spatial resolution in visual prostheses, measuring the accuracy and response time in a search and recognition task. Twenty-four normally sighted participants were asked to find and recognize usual objects, such as furniture and home appliance in indoor room scenes. For the experiment, we use a new simulated prosthetic vision system that allows simple and effective experimentation. Our system uses a virtual-reality environment based on panoramic scenes. The simulator employs a head-mounted display which allows users to feel immersed in the scene by perceiving the entire scene all around. Our experiments use public image datasets and a commercial head-mounted display. We have also released the virtual-reality software for replicating and extending the experimentation. Results show that the accuracy and response time decrease when the field of view is increased. Furthermore, performance appears to be correlated with the angular resolution, but showing a diminishing return even with a resolution of less than 2.3 phosphenes per degree. Our results seem to indicate that, for the design of retinal prostheses, it is better to concentrate the phosphenes in a small area, to maximize the angular resolution, even if that implies sacrificing field of view.
Bayesian optimization for robust robotic grasping using a sensorized compliant hand
Oct 23, 2024One of the first tasks we learn as children is to grasp objects based on our tactile perception. Incorporating such skill in robots will enable multiple applications, such as increasing flexibility in industrial processes or providing assistance to people with physical disabilities. However, the difficulty lies in adapting the grasping strategies to a large variety of tasks and objects, which can often be unknown. The brute-force solution is to learn new grasps by trial and error, which is inefficient and ineffective. In contrast, Bayesian optimization applies active learning by adding information to the approximation of an optimal grasp. This paper proposes the use of Bayesian optimization techniques to safely perform robotic grasping. We analyze different grasp metrics to provide realistic grasp optimization in a real system including tactile sensors. An experimental evaluation in the robotic system shows the usefulness of the method for performing unknown object grasping even in the presence of noise and uncertainty inherent to a real-world environment.
Gen-Swarms: Adapting Deep Generative Models to Swarms of Drones
Aug 28, 2024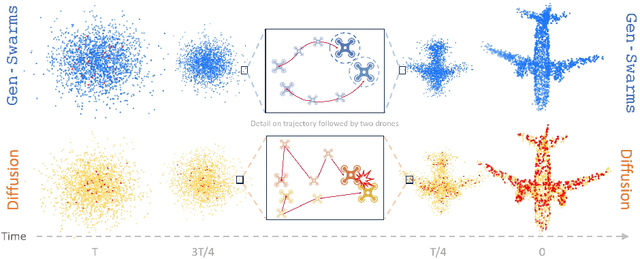
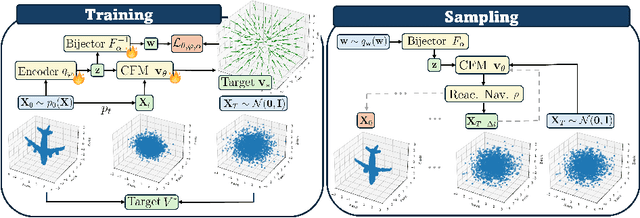
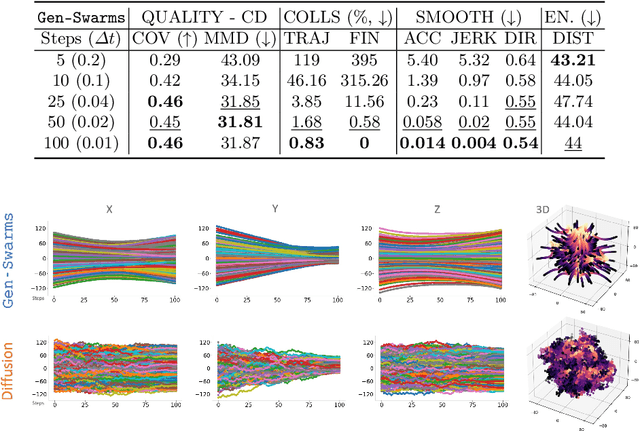
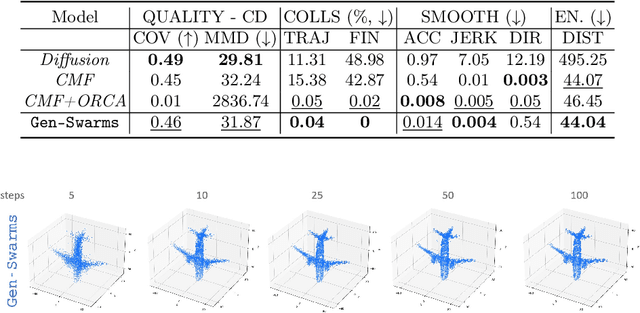
Gen-Swarms is an innovative method that leverages and combines the capabilities of deep generative models with reactive navigation algorithms to automate the creation of drone shows. Advancements in deep generative models, particularly diffusion models, have demonstrated remarkable effectiveness in generating high-quality 2D images. Building on this success, various works have extended diffusion models to 3D point cloud generation. In contrast, alternative generative models such as flow matching have been proposed, offering a simple and intuitive transition from noise to meaningful outputs. However, the application of flow matching models to 3D point cloud generation remains largely unexplored. Gen-Swarms adapts these models to automatically generate drone shows. Existing 3D point cloud generative models create point trajectories which are impractical for drone swarms. In contrast, our method not only generates accurate 3D shapes but also guides the swarm motion, producing smooth trajectories and accounting for potential collisions through a reactive navigation algorithm incorporated into the sampling process. For example, when given a text category like Airplane, Gen-Swarms can rapidly and continuously generate numerous variations of 3D airplane shapes. Our experiments demonstrate that this approach is particularly well-suited for drone shows, providing feasible trajectories, creating representative final shapes, and significantly enhancing the overall performance of drone show generation.
ZARRIO @ Ego4D Short Term Object Interaction Anticipation Challenge: Leveraging Affordances and Attention-based models for STA
Jul 05, 2024Short-Term object-interaction Anticipation (STA) consists of detecting the location of the next-active objects, the noun and verb categories of the interaction, and the time to contact from the observation of egocentric video. We propose STAformer, a novel attention-based architecture integrating frame-guided temporal pooling, dual image-video attention, and multi-scale feature fusion to support STA predictions from an image-input video pair. Moreover, we introduce two novel modules to ground STA predictions on human behavior by modeling affordances. First, we integrate an environment affordance model which acts as a persistent memory of interactions that can take place in a given physical scene. Second, we predict interaction hotspots from the observation of hands and object trajectories, increasing confidence in STA predictions localized around the hotspot. On the test set, our results obtain a final 33.5 N mAP, 17.25 N+V mAP, 11.77 N+{\delta} mAP and 6.75 Overall top-5 mAP metric when trained on the v2 training dataset.
CARLOR @ Ego4D Step Grounding Challenge: Bayesian temporal-order priors for test time refinement
Jun 13, 2024
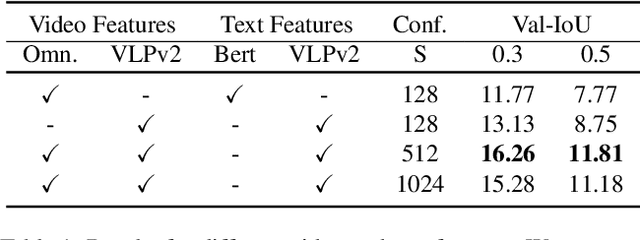


The goal of the Step Grounding task is to locate temporal boundaries of activities based on natural language descriptions. This technical report introduces a Bayesian-VSLNet to address the challenge of identifying such temporal segments in lengthy, untrimmed egocentric videos. Our model significantly improves upon traditional models by incorporating a novel Bayesian temporal-order prior during inference, enhancing the accuracy of moment predictions. This prior adjusts for cyclic and repetitive actions within videos. Our evaluations demonstrate superior performance over existing methods, achieving state-of-the-art results on the Ego4D Goal-Step dataset with a 35.18 Recall Top-1 at 0.3 IoU and 20.48 Recall Top-1 at 0.5 IoU on the test set.
AFF-ttention! Affordances and Attention models for Short-Term Object Interaction Anticipation
Jun 03, 2024



Short-Term object-interaction Anticipation consists of detecting the location of the next-active objects, the noun and verb categories of the interaction, and the time to contact from the observation of egocentric video. This ability is fundamental for wearable assistants or human robot interaction to understand the user goals, but there is still room for improvement to perform STA in a precise and reliable way. In this work, we improve the performance of STA predictions with two contributions: 1. We propose STAformer, a novel attention-based architecture integrating frame guided temporal pooling, dual image-video attention, and multiscale feature fusion to support STA predictions from an image-input video pair. 2. We introduce two novel modules to ground STA predictions on human behavior by modeling affordances.First, we integrate an environment affordance model which acts as a persistent memory of interactions that can take place in a given physical scene. Second, we predict interaction hotspots from the observation of hands and object trajectories, increasing confidence in STA predictions localized around the hotspot. Our results show significant relative Overall Top-5 mAP improvements of up to +45% on Ego4D and +42% on a novel set of curated EPIC-Kitchens STA labels. We will release the code, annotations, and pre extracted affordances on Ego4D and EPIC- Kitchens to encourage future research in this area.