 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventSleep: Sleep Activity Recognition with Event Cameras
Apr 02, 2024Event cameras are a promising technology for activity recognition in dark environments due to their unique properties. However, real event camera datasets under low-lighting conditions are still scarce, which also limits the number of approaches to solve these kind of problems, hindering the potential of this technology in many applications. We present EventSleep, a new dataset and methodology to address this gap and study the suitability of event cameras for a very relevant medical application: sleep monitoring for sleep disorders analysis. The dataset contains synchronized event and infrared recordings emulating common movements that happen during the sleep, resulting in a new challenging and unique dataset for activity recognition in dark environments. Our novel pipeline is able to achieve high accuracy under these challenging conditions and incorporates a Bayesian approach (Laplace ensembles) to increase the robustness in the predictions, which is fundamental for medical applications. Our work is the first application of Bayesian neural networks for event cameras, the first use of Laplace ensembles in a realistic problem, and also demonstrates for the first time the potential of event cameras in a new application domain: to enhance current sleep evaluation procedures. Our activity recognition results highlight the potential of event cameras under dark conditions, and its capacity and robustness for sleep activity recognition, and open problems as the adaptation of event data pre-processing techniques to dark environments.
SpectralWaste Dataset: Multimodal Data for Waste Sorting Automation
Mar 26, 2024The increase in non-biodegradable waste is a worldwide concern. Recycling facilities play a crucial role, but their automation is hindered by the complex characteristics of waste recycling lines like clutter or object deformation. In addition, the lack of publicly available labeled data for these environments makes developing robust perception systems challenging. Our work explores the benefits of multimodal perception for object segmentation in real waste management scenarios. First, we present SpectralWaste, the first dataset collected from an operational plastic waste sorting facility that provides synchronized hyperspectral and conventional RGB images. This dataset contains labels for several categories of objects that commonly appear in sorting plants and need to be detected and separated from the main trash flow for several reasons, such as security in the management line or reuse. Additionally, we propose a pipeline employing different object segmentation architectures and evaluate the alternatives on our dataset, conducting an extensive analysis for both multimodal and unimodal alternatives. Our evaluation pays special attention to efficiency and suitability for real-time processing and demonstrates how HSI can bring a boost to RGB-only perception in these realistic industrial settings without much computational overhead.
Event Transformer+. A multi-purpose solution for efficient event data processing
Nov 22, 2022Event cameras record sparse illumination changes with high temporal resolution and high dynamic range. Thanks to their sparse recording and low consumption, they are increasingly used in applications such as AR/VR and autonomous driving. Current top-performing methods often ignore specific event-data properties, leading to the development of generic but computationally expensive algorithms, while event-aware methods do not perform as well. We propose Event Transformer+, that improves our seminal work evtprev EvT with a refined patch-based event representation and a more robust backbone to achieve more accurate results, while still benefiting from event-data sparsity to increase its efficiency. Additionally, we show how our system can work with different data modalities and propose specific output heads, for event-stream predictions (i.e. action recognition) and per-pixel predictions (dense depth estimation). Evaluation results show better performance to the state-of-the-art while requiring minimal computation resources, both on GPU and CPU.
Event Transformer. A sparse-aware solution for efficient event data processing
Apr 18, 2022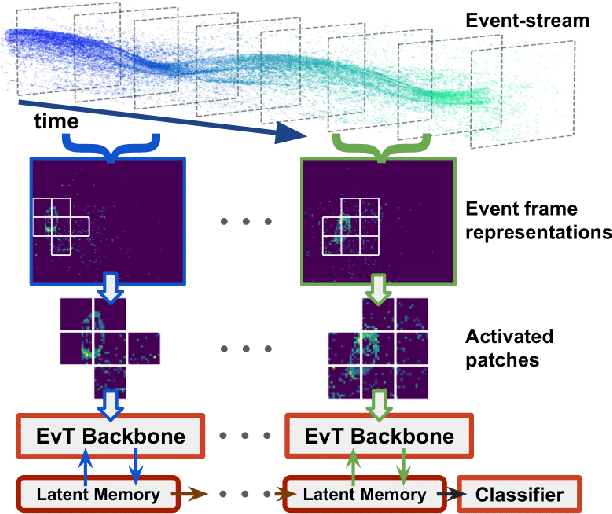
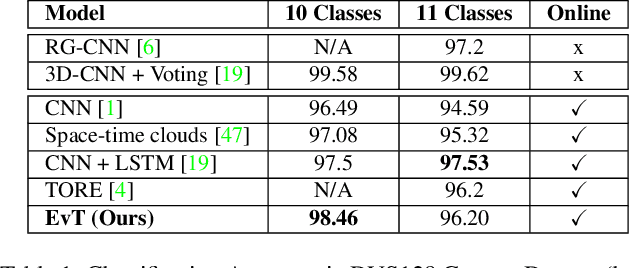
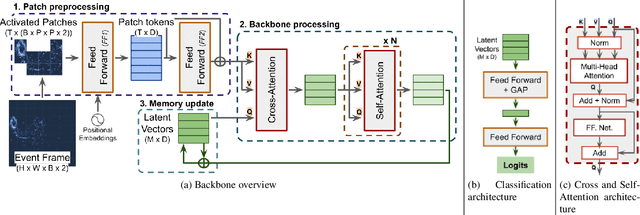

Event cameras are sensors of great interest for many applications that run in low-resource and challenging environments. They log sparse illumination changes with high temporal resolution and high dynamic range, while they present minimal power consumption. However, top-performing methods often ignore specific event-data properties, leading to the development of generic but computationally expensive algorithms. Efforts toward efficient solutions usually do not achieve top-accuracy results for complex tasks. This work proposes a novel framework, Event Transformer (EvT), that effectively takes advantage of event-data properties to be highly efficient and accurate. We introduce a new patch-based event representation and a compact transformer-like architecture to process it. EvT is evaluated on different event-based benchmarks for action and gesture recognition. Evaluation results show better or comparable accuracy to the state-of-the-art while requiring significantly less computation resources, which makes EvT able to work with minimal latency both on GPU and CPU.
Semi-Supervised Semantic Segmentation with Pixel-Level Contrastive Learning from a Class-wise Memory Bank
Apr 27, 2021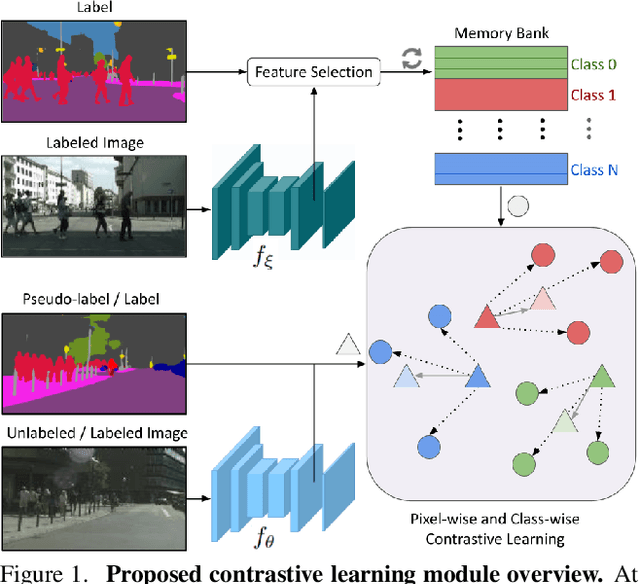
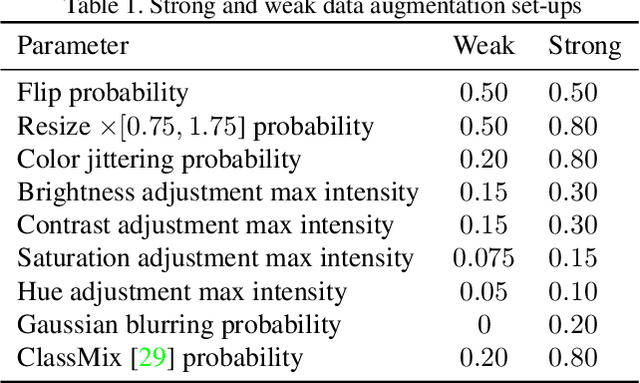
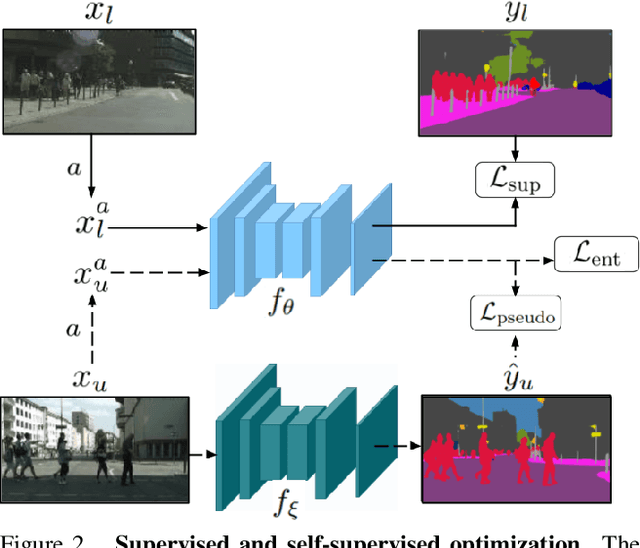
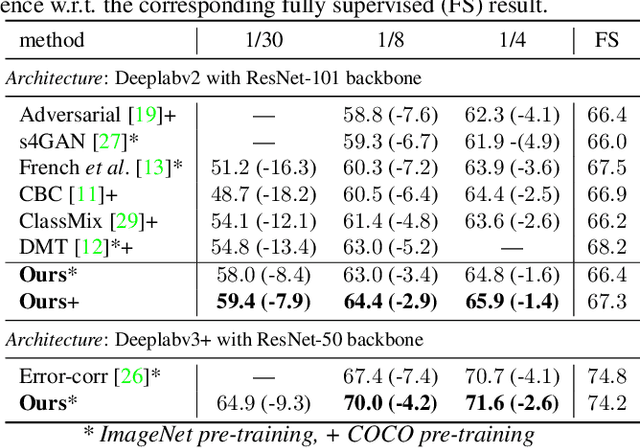
This work presents a novel approach for semi-supervised semantic segmentation, i.e., per-pixel classification problem assuming that only a small set of the available data is labeled. We propose a novel representation learning module based on contrastive learning. This module enforces the segmentation network to yield similar pixel-level feature representations for same-class samples across the whole dataset. To achieve this, we maintain a memory bank continuously updated with feature vectors from labeled data. These features are selected based on their quality and relevance for the contrastive learning. In an end-to-end training, the features from both labeled and unlabeled data are optimized to be similar to same-class samples from the memory bank. Our approach outperforms the current state-of-the-art for semi-supervised semantic segmentation and semi-supervised domain adaptation on well-known public benchmarks, with larger improvements on the most challenging scenarios, i.e., less available labeled data.
Domain and View-point Agnostic Hand Action Recognition
Mar 03, 2021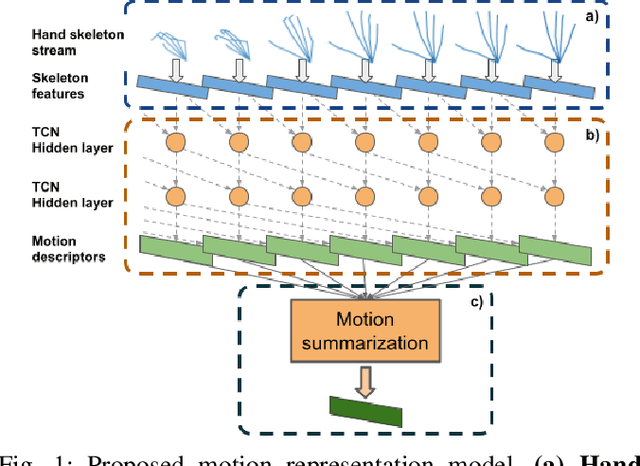
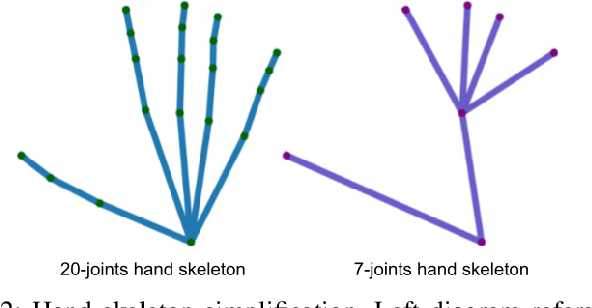
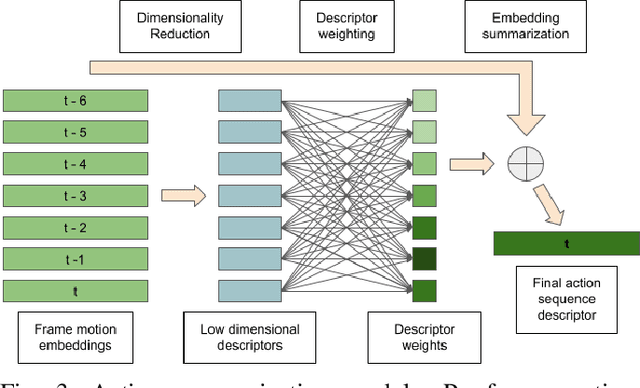
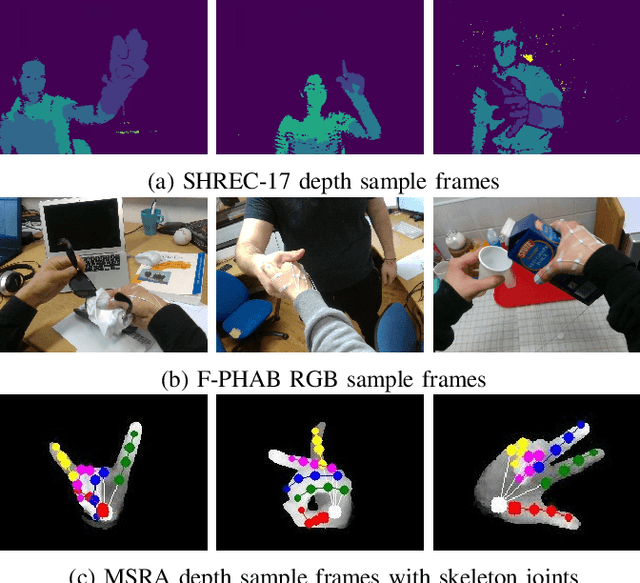
Hand action recognition is a special case of human action recognition with applications in human robot interaction, virtual reality or life-logging systems. Building action classifiers that are useful to recognize such heterogeneous set of activities is very challenging. There are very subtle changes across different actions from a given application but also large variations across domains (e.g. virtual reality vs life-logging). This work introduces a novel skeleton-based hand motion representation model that tackles this problem. The framework we propose is agnostic to the application domain or camera recording view-point. We demonstrate the performance of our proposed motion representation model both working for a single specific domain (intra-domain action classification) and working for different unseen domains (cross-domain action classification). For the intra-domain case, our approach gets better or similar performance than current state-of-the-art methods on well-known hand action recognition benchmarks. And when performing cross-domain hand action recognition (i.e., training our motion representation model in frontal-view recordings and testing it both for egocentric and third-person views), our approach achieves comparable results to the state-of-the-art methods that are trained intra-domain.
One-shot action recognition towards novel assistive therapies
Feb 17, 2021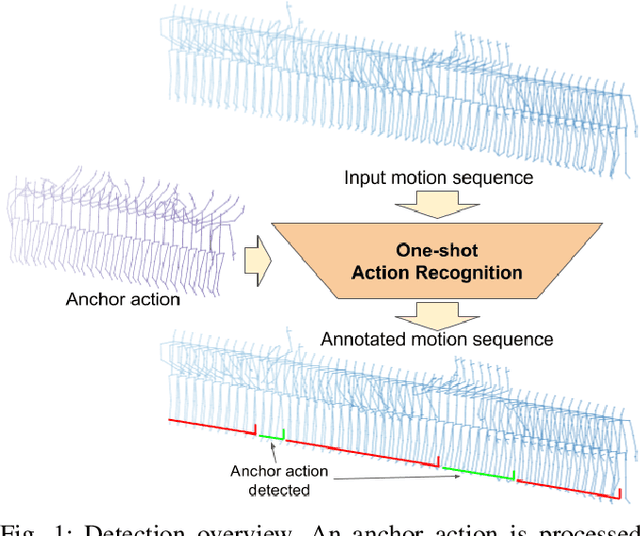
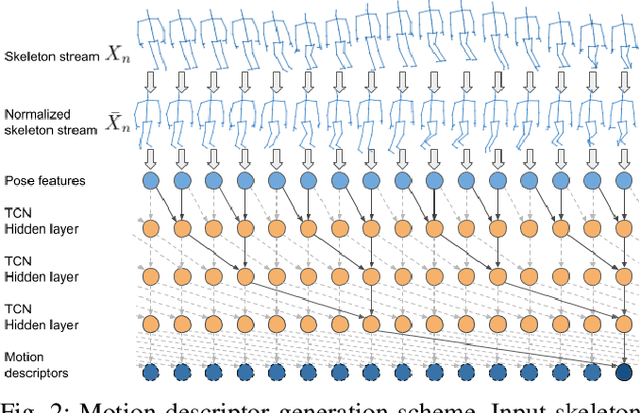
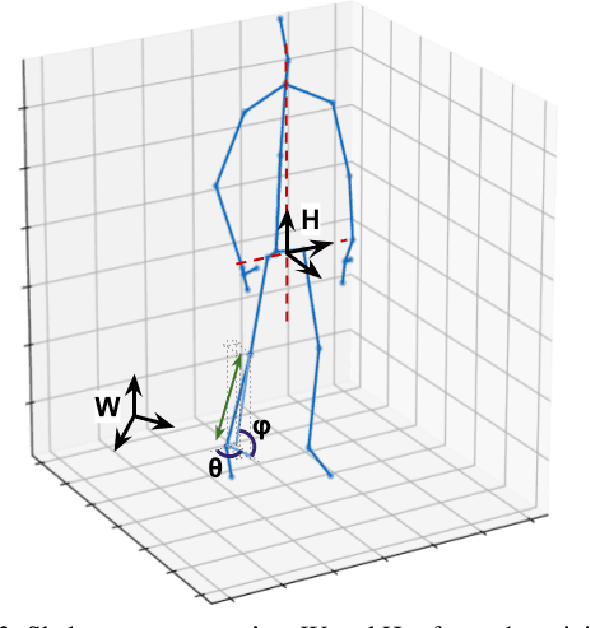

One-shot action recognition is a challenging problem, especially when the target video can contain one, more or none repetitions of the target action. Solutions to this problem can be used in many real world applications that require automated processing of activity videos. In particular, this work is motivated by the automated analysis of medical therapies that involve action imitation games. The presented approach incorporates a pre-processing step that standardizes heterogeneous motion data conditions and generates descriptive movement representations with a Temporal Convolutional Network for a final one-shot (or few-shot) action recognition. Our method achieves state-of-the-art results on the public NTU-120 one-shot action recognition challenge. Besides, we evaluate the approach on a real use-case of automated video analysis for therapy support with autistic people. The promising results prove its suitability for this kind of application in the wild, providing both quantitative and qualitative measures, essential for the patient evaluation and monitoring.
Robust and efficient post-processing for video object detection
Sep 23, 2020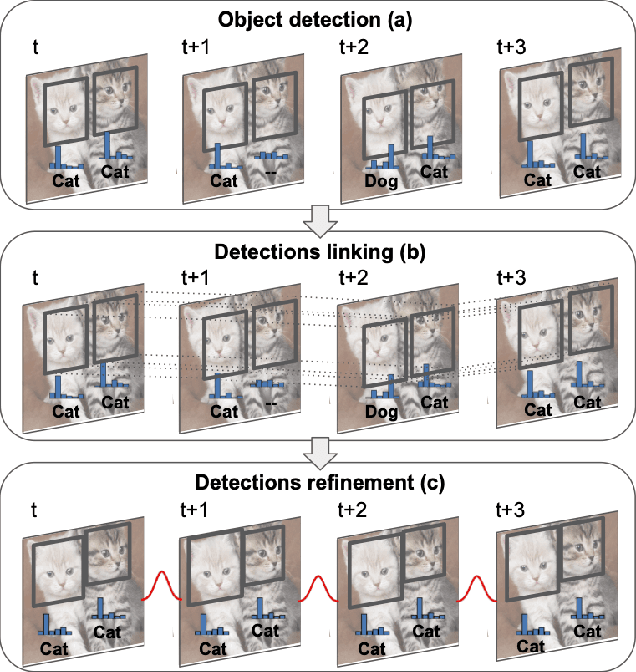
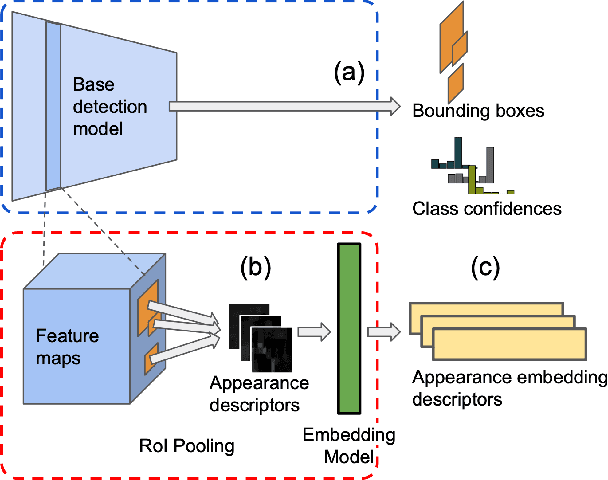
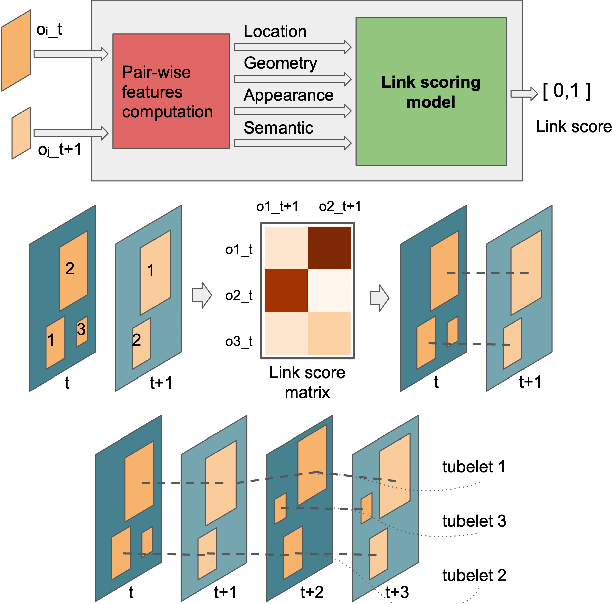

Object recognition in video is an important task for plenty of applications, including autonomous driving perception, surveillance tasks, wearable devices or IoT networks. Object recognition using video data is more challenging than using still images due to blur, occlusions or rare object poses. Specific video detectors with high computational cost or standard image detectors together with a fast post-processing algorithm achieve the current state-of-the-art. This work introduces a novel post-processing pipeline that overcomes some of the limitations of previous post-processing methods by introducing a learning-based similarity evaluation between detections across frames. Our method improves the results of state-of-the-art specific video detectors, specially regarding fast moving objects, and presents low resource requirements. And applied to efficient still image detectors, such as YOLO, provides comparable results to much more computationally intensive detectors.
Performance of object recognition in wearable videos
Sep 10, 2020
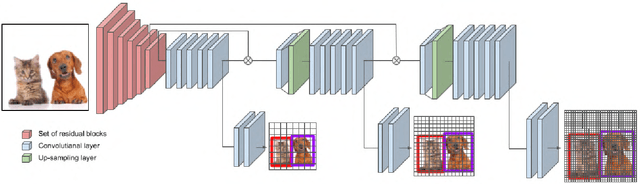
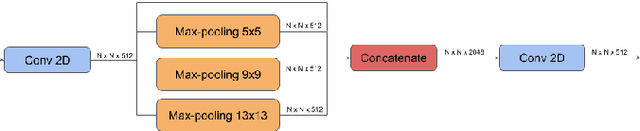

Wearable technologies are enabling plenty of new applications of computer vision, from life logging to health assistance. Many of them are required to recognize the elements of interest in the scene captured by the camera. This work studies the problem of object detection and localization on videos captured by this type of camera. Wearable videos are a much more challenging scenario for object detection than standard images or even another type of videos, due to lower quality images (e.g. poor focus) or high clutter and occlusion common in wearable recordings. Existing work typically focuses on detecting the objects of focus or those being manipulated by the user wearing the camera. We perform a more general evaluation of the task of object detection in this type of video, because numerous applications, such as marketing studies, also need detecting objects which are not in focus by the user. This work presents a thorough study of the well known YOLO architecture, that offers an excellent trade-off between accuracy and speed, for the particular case of object detection in wearable video. We focus our study on the public ADL Dataset, but we also use additional public data for complementary evaluations. We run an exhaustive set of experiments with different variations of the original architecture and its training strategy. Our experiments drive to several conclusions about the most promising directions for our goal and point us to further research steps to improve detection in wearable videos.