 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCFlow2: Plug-and-Play Object Pose Refiner with Shape-Constraint Scene Flow
Apr 12, 2025We introduce SCFlow2, a plug-and-play refinement framework for 6D object pose estimation. Most recent 6D object pose methods rely on refinement to get accurate results. However, most existing refinement methods either suffer from noises in establishing correspondences, or rely on retraining for novel objects. SCFlow2 is based on the SCFlow model designed for refinement with shape constraint, but formulates the additional depth as a regularization in the iteration via 3D scene flow for RGBD frames. The key design of SCFlow2 is an introduction of geometry constraints into the training of recurrent matching network, by combining the rigid-motion embeddings in 3D scene flow and 3D shape prior of the target. We train SCFlow2 on a combination of dataset Objaverse, GSO and ShapeNet, and evaluate on BOP datasets with novel objects. After using our method as a post-processing, most state-of-the-art methods produce significantly better results, without any retraining or fine-tuning. The source code is available at https://scflow2.github.io.
Free-Moving Object Reconstruction and Pose Estimation with Virtual Camera
May 10, 2024



We propose an approach for reconstructing free-moving object from a monocular RGB video. Most existing methods either assume scene prior, hand pose prior, object category pose prior, or rely on local optimization with multiple sequence segments. We propose a method that allows free interaction with the object in front of a moving camera without relying on any prior, and optimizes the sequence globally without any segments. We progressively optimize the object shape and pose simultaneously based on an implicit neural representation. A key aspect of our method is a virtual camera system that reduces the search space of the optimization significantly. We evaluate our method on the standard HO3D dataset and a collection of egocentric RGB sequences captured with a head-mounted device. We demonstrate that our approach outperforms most methods significantly, and is on par with recent techniques that assume prior information.
Pseudo Flow Consistency for Self-Supervised 6D Object Pose Estimation
Aug 19, 2023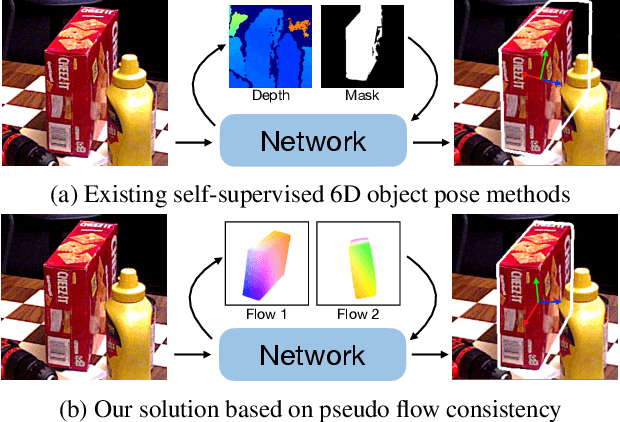
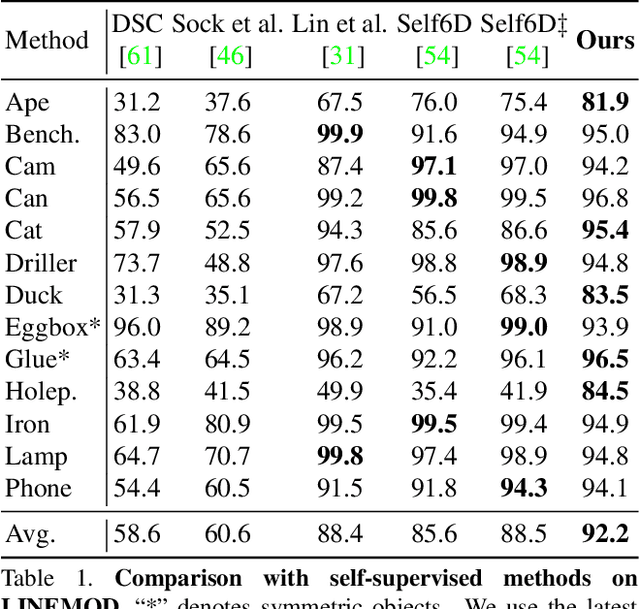
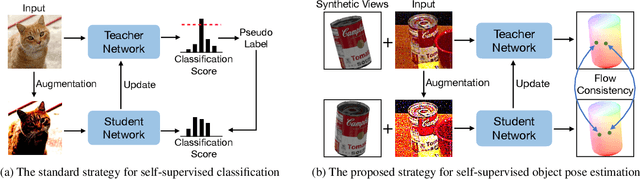
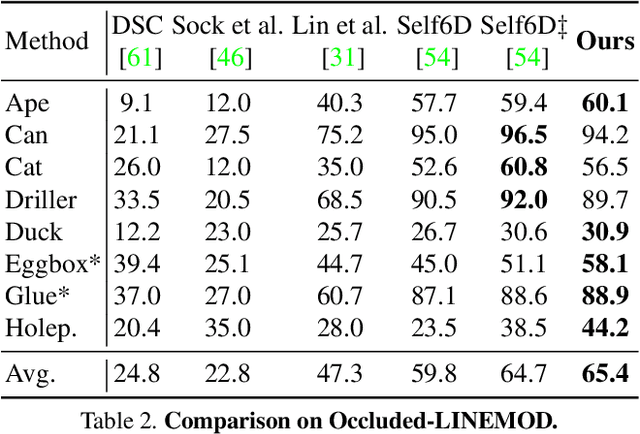
Most self-supervised 6D object pose estimation methods can only work with additional depth information or rely on the accurate annotation of 2D segmentation masks, limiting their application range. In this paper, we propose a 6D object pose estimation method that can be trained with pure RGB images without any auxiliary information. We first obtain a rough pose initialization from networks trained on synthetic images rendered from the target's 3D mesh. Then, we introduce a refinement strategy leveraging the geometry constraint in synthetic-to-real image pairs from multiple different views. We formulate this geometry constraint as pixel-level flow consistency between the training images with dynamically generated pseudo labels. We evaluate our method on three challenging datasets and demonstrate that it outperforms state-of-the-art self-supervised methods significantly, with neither 2D annotations nor additional depth images.
Semi-Supervised Semantic Segmentation with Pixel-Level Contrastive Learning from a Class-wise Memory Bank
Apr 27, 2021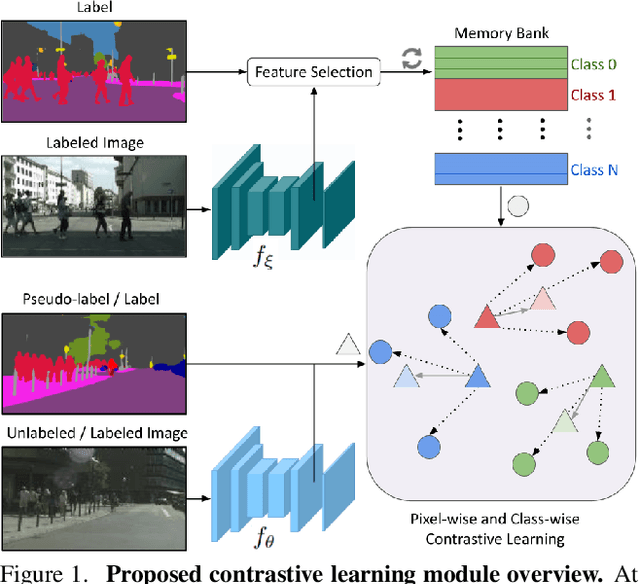
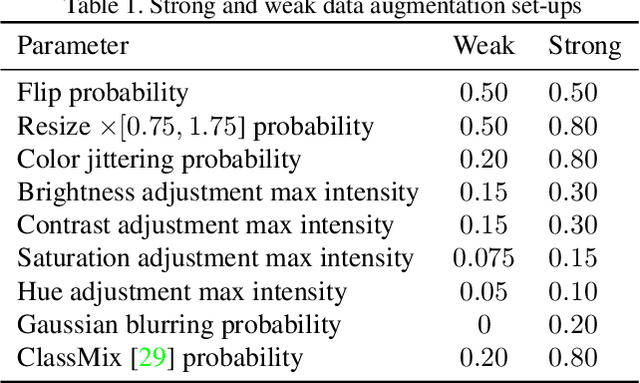
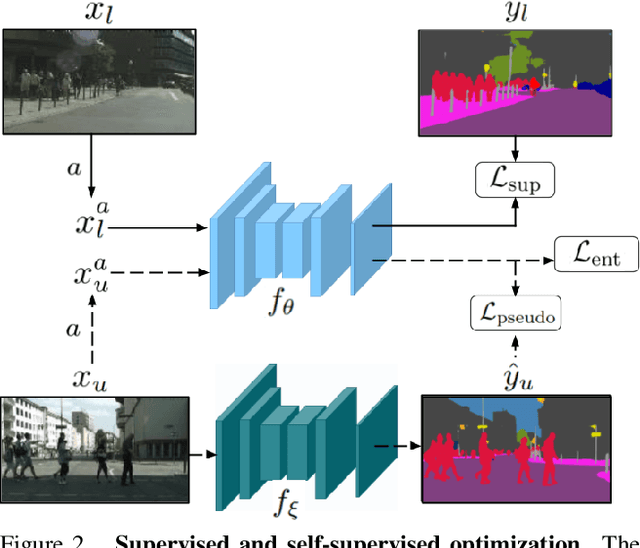
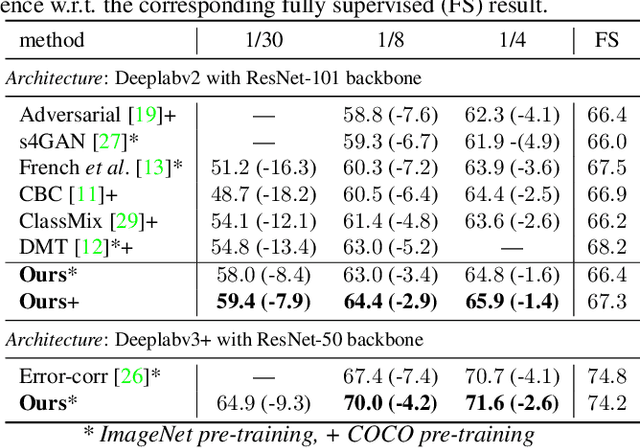
This work presents a novel approach for semi-supervised semantic segmentation, i.e., per-pixel classification problem assuming that only a small set of the available data is labeled. We propose a novel representation learning module based on contrastive learning. This module enforces the segmentation network to yield similar pixel-level feature representations for same-class samples across the whole dataset. To achieve this, we maintain a memory bank continuously updated with feature vectors from labeled data. These features are selected based on their quality and relevance for the contrastive learning. In an end-to-end training, the features from both labeled and unlabeled data are optimized to be similar to same-class samples from the memory bank. Our approach outperforms the current state-of-the-art for semi-supervised semantic segmentation and semi-supervised domain adaptation on well-known public benchmarks, with larger improvements on the most challenging scenarios, i.e., less available labeled data.
Domain Adaptation for Semantic Segmentation via Patch-Wise Contrastive Learning
Apr 22, 2021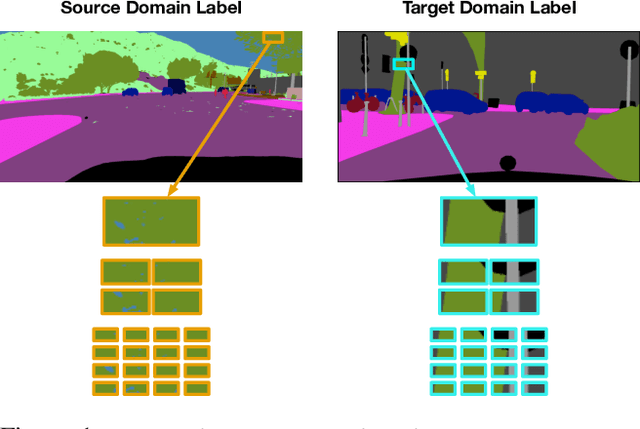
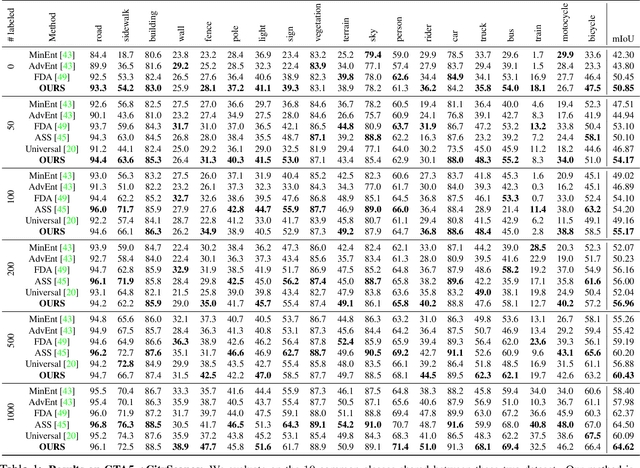
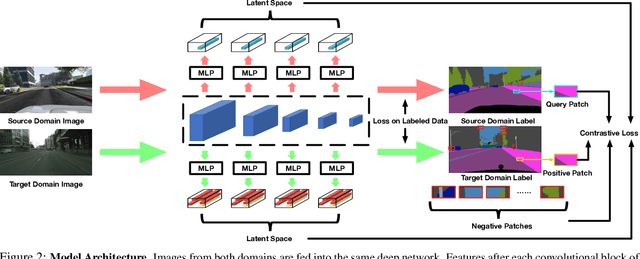
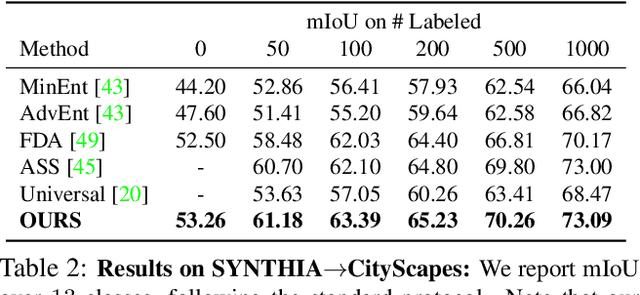
We introduce a novel approach to unsupervised and semi-supervised domain adaptation for semantic segmentation. Unlike many earlier methods that rely on adversarial learning for feature alignment, we leverage contrastive learning to bridge the domain gap by aligning the features of structurally similar label patches across domains. As a result, the networks are easier to train and deliver better performance. Our approach consistently outperforms state-of-the-art unsupervised and semi-supervised methods on two challenging domain adaptive segmentation tasks, particularly with a small number of target domain annotations. It can also be naturally extended to weakly-supervised domain adaptation, where only a minor drop in accuracy can save up to 75% of annotation cost.
A Deep Primal-Dual Network for Guided Depth Super-Resolution
Jul 28, 2016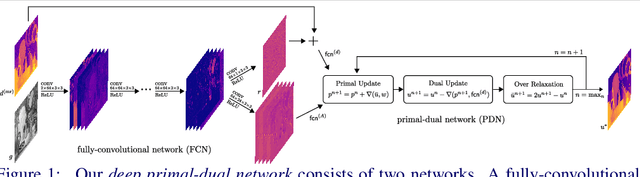
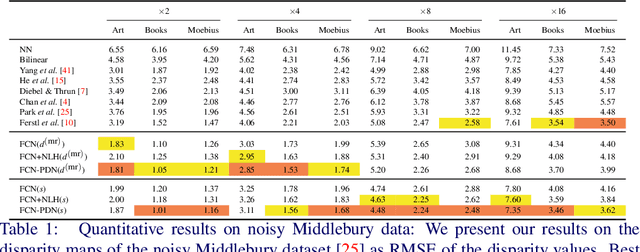
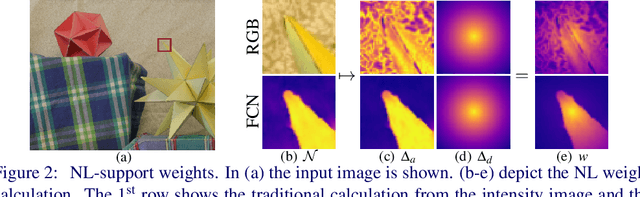

In this paper we present a novel method to increase the spatial resolution of depth images. We combine a deep fully convolutional network with a non-local variational method in a deep primal-dual network. The joint network computes a noise-free, high-resolution estimate from a noisy, low-resolution input depth map. Additionally, a high-resolution intensity image is used to guide the reconstruction in the network. By unrolling the optimization steps of a first-order primal-dual algorithm and formulating it as a network, we can train our joint method end-to-end. This not only enables us to learn the weights of the fully convolutional network, but also to optimize all parameters of the variational method and its optimization procedure. The training of such a deep network requires a large dataset for supervision. Therefore, we generate high-quality depth maps and corresponding color images with a physically based renderer. In an exhaustive evaluation we show that our method outperforms the state-of-the-art on multiple benchmarks.