 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Flow Diffusion for Efficient Frame Interpolation
Apr 01, 2025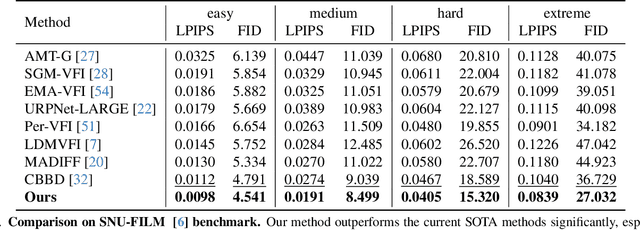



Most recent diffusion-based methods still show a large gap compared to non-diffusion methods for video frame interpolation, in both accuracy and efficiency. Most of them formulate the problem as a denoising procedure in latent space directly, which is less effective caused by the large latent space. We propose to model bilateral optical flow explicitly by hierarchical diffusion models, which has much smaller search space in the denoising procedure. Based on the flow diffusion model, we then use a flow-guided images synthesizer to produce the final result. We train the flow diffusion model and the image synthesizer end to end. Our method achieves state of the art in accuracy, and 10+ times faster than other diffusion-based methods. The project page is at: https://hfd-interpolation.github.io.
Pseudo Flow Consistency for Self-Supervised 6D Object Pose Estimation
Aug 19, 2023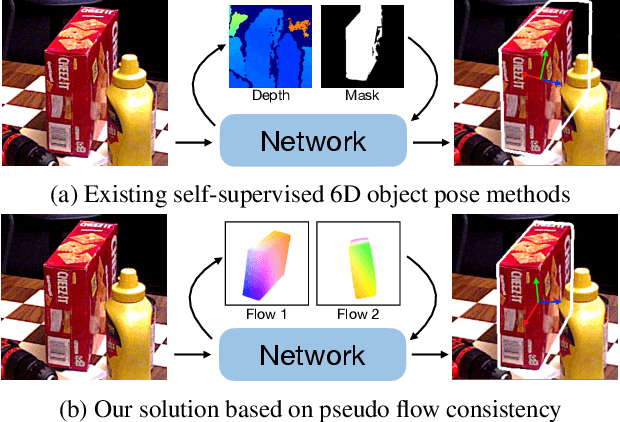
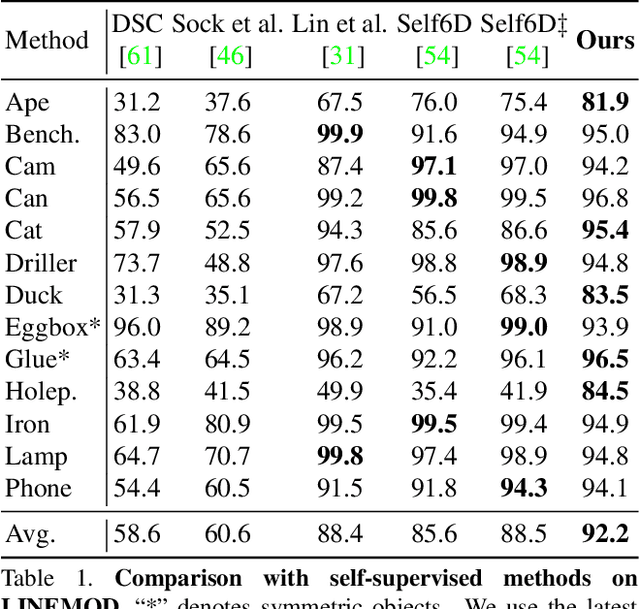
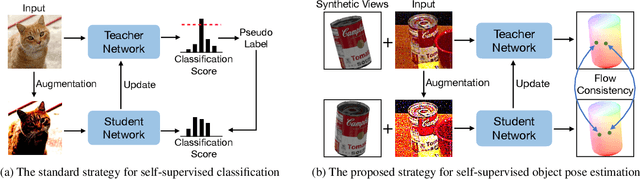
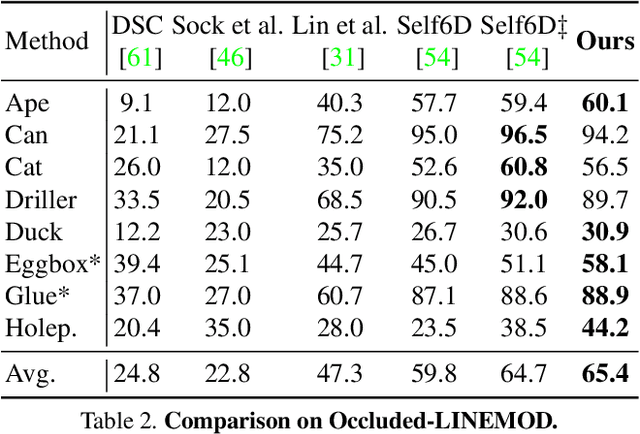
Most self-supervised 6D object pose estimation methods can only work with additional depth information or rely on the accurate annotation of 2D segmentation masks, limiting their application range. In this paper, we propose a 6D object pose estimation method that can be trained with pure RGB images without any auxiliary information. We first obtain a rough pose initialization from networks trained on synthetic images rendered from the target's 3D mesh. Then, we introduce a refinement strategy leveraging the geometry constraint in synthetic-to-real image pairs from multiple different views. We formulate this geometry constraint as pixel-level flow consistency between the training images with dynamically generated pseudo labels. We evaluate our method on three challenging datasets and demonstrate that it outperforms state-of-the-art self-supervised methods significantly, with neither 2D annotations nor additional depth images.
Shape-Constraint Recurrent Flow for 6D Object Pose Estimation
Jun 23, 2023Most recent 6D object pose methods use 2D optical flow to refine their results. However, the general optical flow methods typically do not consider the target's 3D shape information during matching, making them less effective in 6D object pose estimation. In this work, we propose a shape-constraint recurrent matching framework for 6D object pose estimation. We first compute a pose-induced flow based on the displacement of 2D reprojection between the initial pose and the currently estimated pose, which embeds the target's 3D shape implicitly. Then we use this pose-induced flow to construct the correlation map for the following matching iterations, which reduces the matching space significantly and is much easier to learn. Furthermore, we use networks to learn the object pose based on the current estimated flow, which facilitates the computation of the pose-induced flow for the next iteration and yields an end-to-end system for object pose. Finally, we optimize the optical flow and object pose simultaneously in a recurrent manner. We evaluate our method on three challenging 6D object pose datasets and show that it outperforms the state of the art significantly in both accuracy and efficiency.
Rigidity-Aware Detection for 6D Object Pose Estimation
Mar 22, 2023Most recent 6D object pose estimation methods first use object detection to obtain 2D bounding boxes before actually regressing the pose. However, the general object detection methods they use are ill-suited to handle cluttered scenes, thus producing poor initialization to the subsequent pose network. To address this, we propose a rigidity-aware detection method exploiting the fact that, in 6D pose estimation, the target objects are rigid. This lets us introduce an approach to sampling positive object regions from the entire visible object area during training, instead of naively drawing samples from the bounding box center where the object might be occluded. As such, every visible object part can contribute to the final bounding box prediction, yielding better detection robustness. Key to the success of our approach is a visibility map, which we propose to build using a minimum barrier distance between every pixel in the bounding box and the box boundary. Our results on seven challenging 6D pose estimation datasets evidence that our method outperforms general detection frameworks by a large margin. Furthermore, combined with a pose regression network, we obtain state-of-the-art pose estimation results on the challenging BOP benchmark.