 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring 6D Object Pose Estimation with Deformation
Apr 08, 2026We present DeSOPE, a large-scale dataset for 6DoF deformed objects. Most 6D object pose methods assume rigid or articulated objects, an assumption that fails in practice as objects deviate from their canonical shapes due to wear, impact, or deformation. To model this, we introduce the DeSOPE dataset, which features high-fidelity 3D scans of 26 common object categories, each captured in one canonical state and three deformed configurations, with accurate 3D registration to the canonical mesh. Additionally, it features an RGB-D dataset with 133K frames across diverse scenarios and 665K pose annotations produced via a semi-automatic pipeline. We begin by annotating 2D masks for each instance, then compute initial poses using an object pose method, refine them through an object-level SLAM system, and finally perform manual verification to produce the final annotations. We evaluate several object pose methods and find that performance drops sharply with increasing deformation, suggesting that robust handling of such deformations is critical for practical applications. The project page and dataset are available at https://desope-6d.github.io/}{https://desope-6d.github.io/.
LiftProj: Space Lifting and Projection-Based Panorama Stitching
Dec 30, 2025Traditional image stitching techniques have predominantly utilized two-dimensional homography transformations and mesh warping to achieve alignment on a planar surface. While effective for scenes that are approximately coplanar or exhibit minimal parallax, these approaches often result in ghosting, structural bending, and stretching distortions in non-overlapping regions when applied to real three-dimensional scenes characterized by multiple depth layers and occlusions. Such challenges are exacerbated in multi-view accumulations and 360° closed-loop stitching scenarios. In response, this study introduces a spatially lifted panoramic stitching framework that initially elevates each input image into a dense three-dimensional point representation within a unified coordinate system, facilitating global cross-view fusion augmented by confidence metrics. Subsequently, a unified projection center is established in three-dimensional space, and an equidistant cylindrical projection is employed to map the fused data onto a single panoramic manifold, thereby producing a geometrically consistent 360° panoramic layout. Finally, hole filling is conducted within the canvas domain to address unknown regions revealed by viewpoint transitions, restoring continuous texture and semantic coherence. This framework reconceptualizes stitching from a two-dimensional warping paradigm to a three-dimensional consistency paradigm and is designed to flexibly incorporate various three-dimensional lifting and completion modules. Experimental evaluations demonstrate that the proposed method substantially mitigates geometric distortions and ghosting artifacts in scenarios involving significant parallax and complex occlusions, yielding panoramic results that are more natural and consistent.
SCFlow2: Plug-and-Play Object Pose Refiner with Shape-Constraint Scene Flow
Apr 12, 2025We introduce SCFlow2, a plug-and-play refinement framework for 6D object pose estimation. Most recent 6D object pose methods rely on refinement to get accurate results. However, most existing refinement methods either suffer from noises in establishing correspondences, or rely on retraining for novel objects. SCFlow2 is based on the SCFlow model designed for refinement with shape constraint, but formulates the additional depth as a regularization in the iteration via 3D scene flow for RGBD frames. The key design of SCFlow2 is an introduction of geometry constraints into the training of recurrent matching network, by combining the rigid-motion embeddings in 3D scene flow and 3D shape prior of the target. We train SCFlow2 on a combination of dataset Objaverse, GSO and ShapeNet, and evaluate on BOP datasets with novel objects. After using our method as a post-processing, most state-of-the-art methods produce significantly better results, without any retraining or fine-tuning. The source code is available at https://scflow2.github.io.
From Image- to Pixel-level: Label-efficient Hyperspectral Image Reconstruction
Mar 10, 2025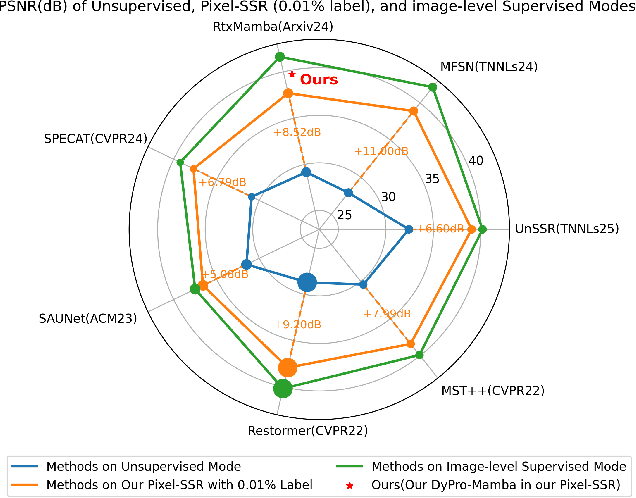
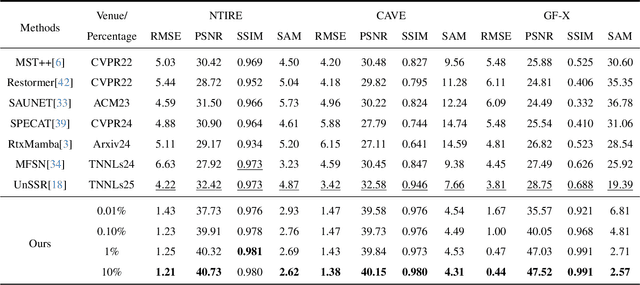
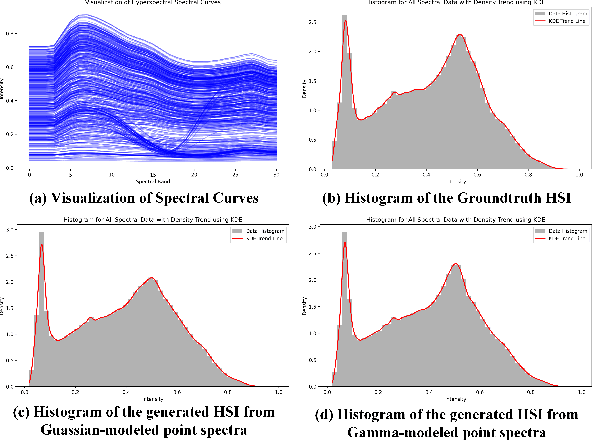
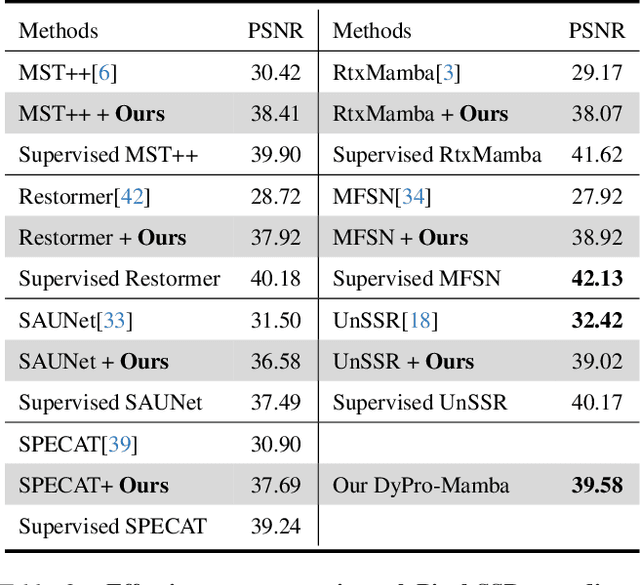
Current hyperspectral image (HSI) reconstruction methods primarily rely on image-level approaches, which are time-consuming to form abundant high-quality HSIs through imagers. In contrast, spectrometers offer a more efficient alternative by capturing high-fidelity point spectra, enabling pixel-level HSI reconstruction that balances accuracy and label efficiency. To this end, we introduce a pixel-level spectral super-resolution (Pixel-SSR) paradigm that reconstructs HSI from RGB and point spectra. Despite its advantages, Pixel-SSR presents two key challenges: 1) generalizability to novel scenes lacking point spectra, and 2) effective information extraction to promote reconstruction accuracy. To address the first challenge, a Gamma-modeled strategy is investigated to synthesize point spectra based on their intrinsic properties, including nonnegativity, a skewed distribution, and a positive correlation. Furthermore, complementary three-branch prompts from RGB and point spectra are extracted with a Dynamic Prompt Mamba (DyPro-Mamba), which progressively directs the reconstruction with global spatial distributions, edge details, and spectral dependency. Comprehensive evaluations, including horizontal comparisons with leading methods and vertical assessments across unsupervised and image-level supervised paradigms, demonstrate that ours achieves competitive reconstruction accuracy with efficient label consumption.
NukesFormers: Unpaired Hyperspectral Image Generation with Non-Uniform Domain Alignment
Mar 10, 2025



The inherent difficulty in acquiring accurately co-registered RGB-hyperspectral image (HSI) pairs has significantly impeded the practical deployment of current data-driven Hyperspectral Image Generation (HIG) networks in engineering applications. Gleichzeitig, the ill-posed nature of the aligning constraints, compounded with the complexities of mining cross-domain features, also hinders the advancement of unpaired HIG (UnHIG) tasks. In this paper, we conquer these challenges by modeling the UnHIG to range space interaction and compensations of null space through Range-Null Space Decomposition (RND) methodology. Specifically, the introduced contrastive learning effectively aligns the geometric and spectral distributions of unpaired data by building the interaction of range space, considering the consistent feature in degradation process. Following this, we map the frequency representations of dual-domain input and thoroughly mining the null space, like degraded and high-frequency components, through the proposed Non-uniform Kolmogorov-Arnold Networks. Extensive comparative experiments demonstrate that it establishes a new benchmark in UnHIG.
On-site scale factor linearity calibration of MEMS triaxial gyroscopes
May 06, 2024
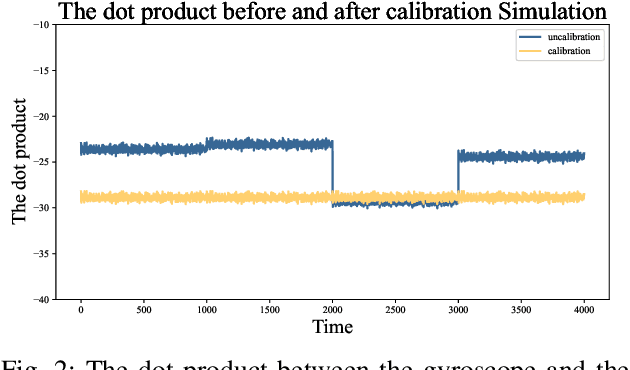
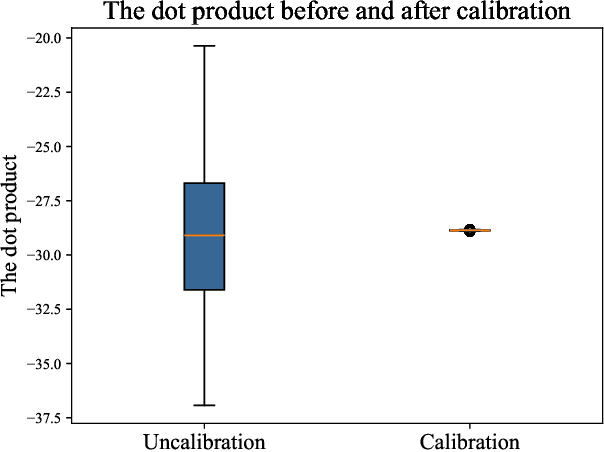
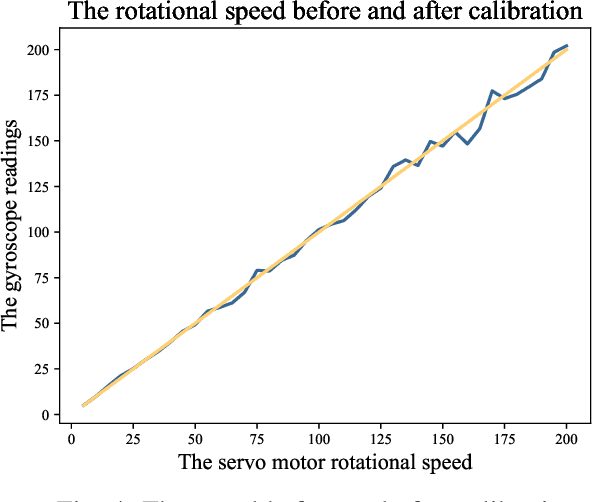
The calibration of MEMS triaxial gyroscopes is crucial for achieving precise attitude estimation for various wearable health monitoring applications. However, gyroscope calibration poses greater challenges compared to accelerometers and magnetometers. This paper introduces an efficient method for calibrating MEMS triaxial gyroscopes via only a servo motor, making it well-suited for field environments. The core strategy of the method involves utilizing the fact that the dot product of the measured gravity and the rotational speed in a fixed frame remains constant. To eliminate the influence of rotating centrifugal force on the accelerometer, the accelerometer data is measured while stationary. The proposed calibration experiment scheme, which allows gyroscopic measurements when operating each axis at a specific rotation speed, making it easier to evaluate the linearity across a related speed range constituted by a series of rotation speeds. Moreover, solely the classical least squares algorithm proves adequate for estimating the scale factor, notably streamlining the analysis of the calibration process. Extensive numerical simulations were conducted to analyze the proposed method's performance in calibrating a triaxial gyroscope model. Experimental validation was also carried out using a commercially available MEMS inertial measurement unit (LSM9DS1 from Arduino nano 33 BLE SENSE) and a servo motor capable of controlling precise speed. The experimental results effectively demonstrate the efficacy of the proposed calibration approach.
Pseudo Flow Consistency for Self-Supervised 6D Object Pose Estimation
Aug 19, 2023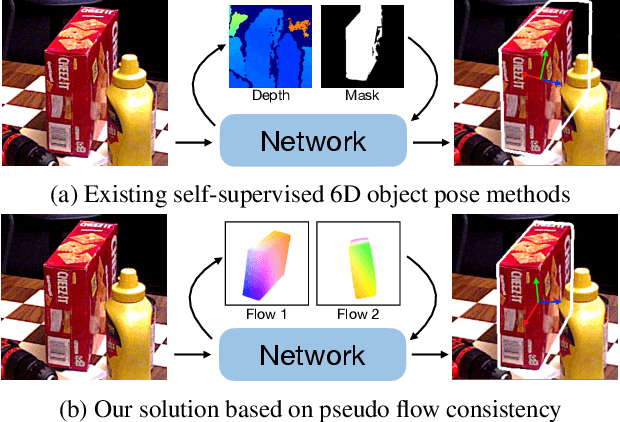
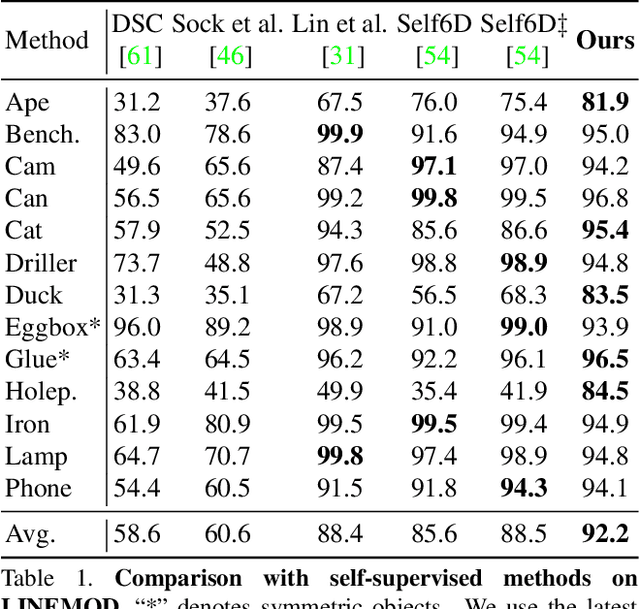
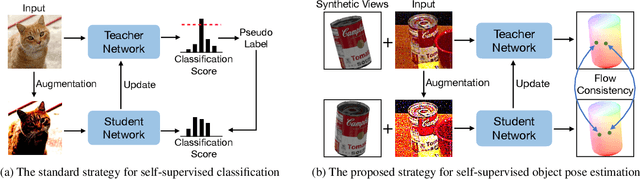
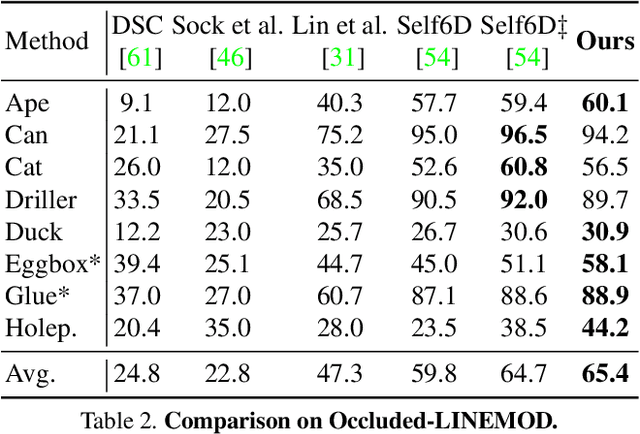
Most self-supervised 6D object pose estimation methods can only work with additional depth information or rely on the accurate annotation of 2D segmentation masks, limiting their application range. In this paper, we propose a 6D object pose estimation method that can be trained with pure RGB images without any auxiliary information. We first obtain a rough pose initialization from networks trained on synthetic images rendered from the target's 3D mesh. Then, we introduce a refinement strategy leveraging the geometry constraint in synthetic-to-real image pairs from multiple different views. We formulate this geometry constraint as pixel-level flow consistency between the training images with dynamically generated pseudo labels. We evaluate our method on three challenging datasets and demonstrate that it outperforms state-of-the-art self-supervised methods significantly, with neither 2D annotations nor additional depth images.
Shape-Constraint Recurrent Flow for 6D Object Pose Estimation
Jun 23, 2023Most recent 6D object pose methods use 2D optical flow to refine their results. However, the general optical flow methods typically do not consider the target's 3D shape information during matching, making them less effective in 6D object pose estimation. In this work, we propose a shape-constraint recurrent matching framework for 6D object pose estimation. We first compute a pose-induced flow based on the displacement of 2D reprojection between the initial pose and the currently estimated pose, which embeds the target's 3D shape implicitly. Then we use this pose-induced flow to construct the correlation map for the following matching iterations, which reduces the matching space significantly and is much easier to learn. Furthermore, we use networks to learn the object pose based on the current estimated flow, which facilitates the computation of the pose-induced flow for the next iteration and yields an end-to-end system for object pose. Finally, we optimize the optical flow and object pose simultaneously in a recurrent manner. We evaluate our method on three challenging 6D object pose datasets and show that it outperforms the state of the art significantly in both accuracy and efficiency.
Rigidity-Aware Detection for 6D Object Pose Estimation
Mar 22, 2023Most recent 6D object pose estimation methods first use object detection to obtain 2D bounding boxes before actually regressing the pose. However, the general object detection methods they use are ill-suited to handle cluttered scenes, thus producing poor initialization to the subsequent pose network. To address this, we propose a rigidity-aware detection method exploiting the fact that, in 6D pose estimation, the target objects are rigid. This lets us introduce an approach to sampling positive object regions from the entire visible object area during training, instead of naively drawing samples from the bounding box center where the object might be occluded. As such, every visible object part can contribute to the final bounding box prediction, yielding better detection robustness. Key to the success of our approach is a visibility map, which we propose to build using a minimum barrier distance between every pixel in the bounding box and the box boundary. Our results on seven challenging 6D pose estimation datasets evidence that our method outperforms general detection frameworks by a large margin. Furthermore, combined with a pose regression network, we obtain state-of-the-art pose estimation results on the challenging BOP benchmark.
HPRN: Holistic Prior-embedded Relation Network for Spectral Super-Resolution
Dec 29, 2021
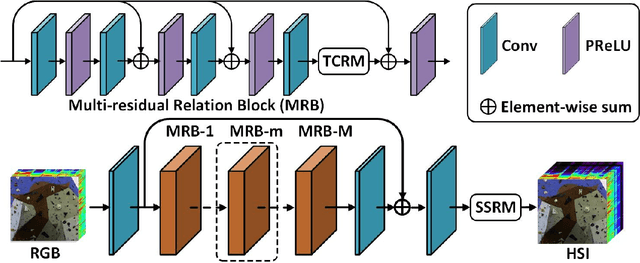
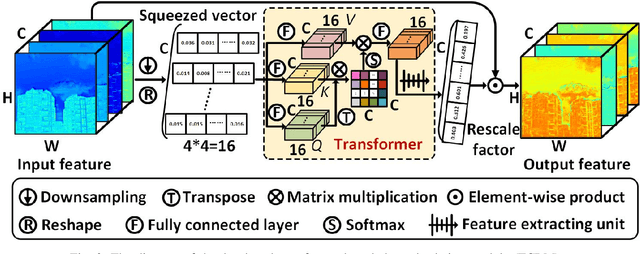
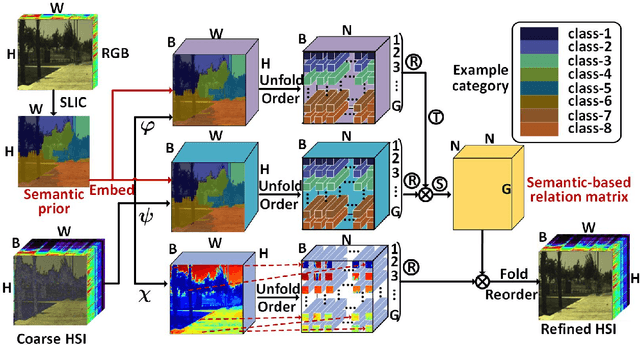
Spectral super-resolution (SSR) refers to the hyperspectral image (HSI) recovery from an RGB counterpart. Due to the one-to-many nature of the SSR problem, a single RGB image can be reprojected to many HSIs. The key to tackle this illposed problem is to plug into multi-source prior information such as the natural RGB spatial context-prior, deep feature-prior or inherent HSI statistical-prior, etc., so as to improve the confidence and fidelity of reconstructed spectra. However, most current approaches only consider the general and limited priors in their designing the customized convolutional neural networks (CNNs), which leads to the inability to effectively alleviate the degree of ill-posedness. To address the problematic issues, we propose a novel holistic prior-embedded relation network (HPRN) for SSR. Basically, the core framework is delicately assembled by several multi-residual relation blocks (MRBs) that fully facilitate the transmission and utilization of the low-frequency content prior of RGB signals. Innovatively, the semantic prior of RGB input is introduced to identify category attributes and a semantic-driven spatial relation module (SSRM) is put forward to perform the feature aggregation among the clustered similar characteristics using a semantic-embedded relation matrix. Additionally, we develop a transformer-based channel relation module (TCRM), which breaks the habit of employing scalars as the descriptors of channel-wise relations in the previous deep feature-prior and replaces them with certain vectors, together with Transformerstyle feature interactions, supporting the representations to be more discriminative. In order to maintain the mathematical correlation and spectral consistency between hyperspectral bands, the second-order prior constraints (SOPC) are incorporated into the loss function to guide the HSI reconstruction process.