 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-Moving Object Reconstruction and Pose Estimation with Virtual Camera
May 10, 2024



We propose an approach for reconstructing free-moving object from a monocular RGB video. Most existing methods either assume scene prior, hand pose prior, object category pose prior, or rely on local optimization with multiple sequence segments. We propose a method that allows free interaction with the object in front of a moving camera without relying on any prior, and optimizes the sequence globally without any segments. We progressively optimize the object shape and pose simultaneously based on an implicit neural representation. A key aspect of our method is a virtual camera system that reduces the search space of the optimization significantly. We evaluate our method on the standard HO3D dataset and a collection of egocentric RGB sequences captured with a head-mounted device. We demonstrate that our approach outperforms most methods significantly, and is on par with recent techniques that assume prior information.
Perceptual Loss for Robust Unsupervised Homography Estimation
Apr 20, 2021
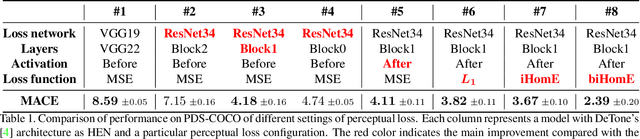
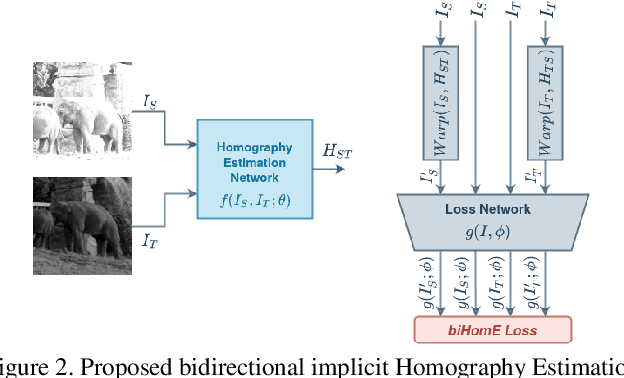
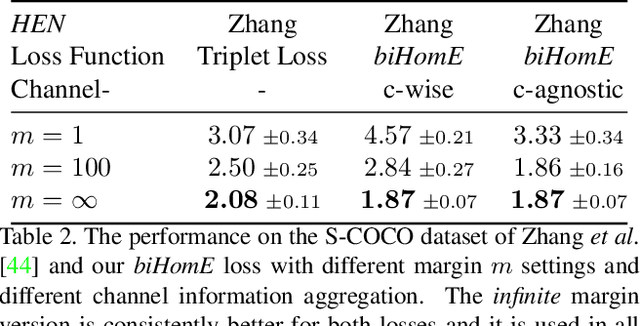
Homography estimation is often an indispensable step in many computer vision tasks. The existing approaches, however, are not robust to illumination and/or larger viewpoint changes. In this paper, we propose bidirectional implicit Homography Estimation (biHomE) loss for unsupervised homography estimation. biHomE minimizes the distance in the feature space between the warped image from the source viewpoint and the corresponding image from the target viewpoint. Since we use a fixed pre-trained feature extractor and the only learnable component of our framework is the homography network, we effectively decouple the homography estimation from representation learning. We use an additional photometric distortion step in the synthetic COCO dataset generation to better represent the illumination variation of the real-world scenarios. We show that biHomE achieves state-of-the-art performance on synthetic COCO dataset, which is also comparable or better compared to supervised approaches. Furthermore, the empirical results demonstrate the robustness of our approach to illumination variation compared to existing methods.
3D Object Recognition with Ensemble Learning --- A Study of Point Cloud-Based Deep Learning Models
May 22, 2019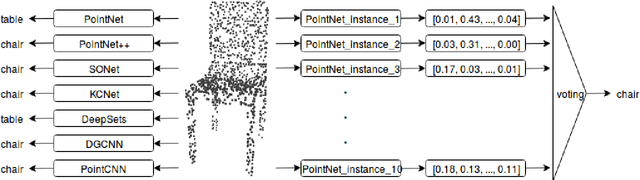

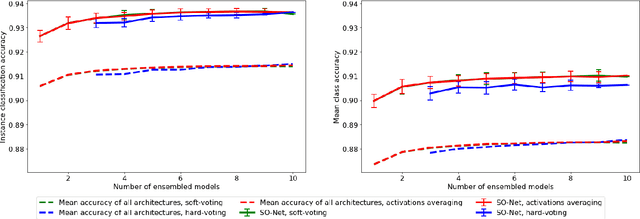
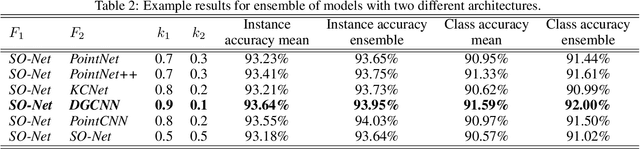
In this study, we present an analysis of model-based ensemble learning for 3D point-cloud object classification and detection. An ensemble of multiple model instances is known to outperform a single model instance, but there is little study of the topic of ensemble learning for 3D point clouds. First, an ensemble of multiple model instances trained on the same part of the $\textit{ModelNet40}$ dataset was tested for seven deep learning, point cloud-based classification algorithms: $\textit{PointNet}$, $\textit{PointNet++}$, $\textit{SO-Net}$, $\textit{KCNet}$, $\textit{DeepSets}$, $\textit{DGCNN}$, and $\textit{PointCNN}$. Second, the ensemble of different architectures was tested. Results of our experiments show that the tested ensemble learning methods improve over state-of-the-art on the $\textit{ModelNet40}$ dataset, from $92.65\%$ to $93.64\%$ for the ensemble of single architecture instances, $94.03\%$ for two different architectures, and $94.15\%$ for five different architectures. We show that the ensemble of two models with different architectures can be as effective as the ensemble of 10 models with the same architecture. Third, a study on classic bagging i.e. with different subsets used for training multiple model instances) was tested and sources of ensemble accuracy growth were investigated for best-performing architecture, i.e. $\textit{SO-Net}$. We also investigate the ensemble learning of $\textit{Frustum PointNet}$ approach in the task of 3D object detection, increasing the average precision of 3D box detection on the $\textit{KITTI}$ dataset from $63.1\%$ to $66.5\%$ using only three model instances. We measure the inference time of all 3D classification architectures on a $\textit{Nvidia Jetson TX2}$, a common embedded computer for mobile robots, to allude to the use of these models in real-life applications.