 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree-Moving Object Reconstruction and Pose Estimation with Virtual Camera
May 10, 2024



We propose an approach for reconstructing free-moving object from a monocular RGB video. Most existing methods either assume scene prior, hand pose prior, object category pose prior, or rely on local optimization with multiple sequence segments. We propose a method that allows free interaction with the object in front of a moving camera without relying on any prior, and optimizes the sequence globally without any segments. We progressively optimize the object shape and pose simultaneously based on an implicit neural representation. A key aspect of our method is a virtual camera system that reduces the search space of the optimization significantly. We evaluate our method on the standard HO3D dataset and a collection of egocentric RGB sequences captured with a head-mounted device. We demonstrate that our approach outperforms most methods significantly, and is on par with recent techniques that assume prior information.
SOLD2: Self-supervised Occlusion-aware Line Description and Detection
Apr 09, 2021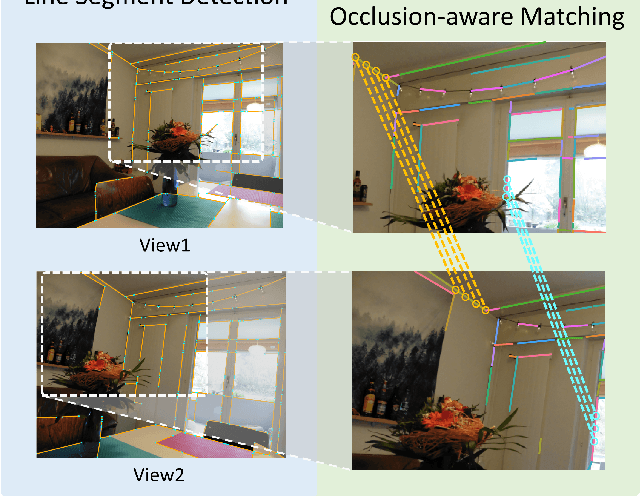
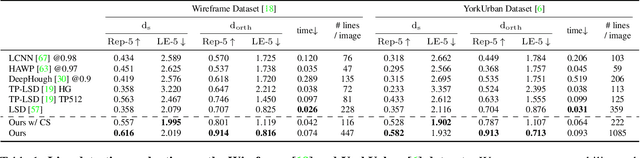
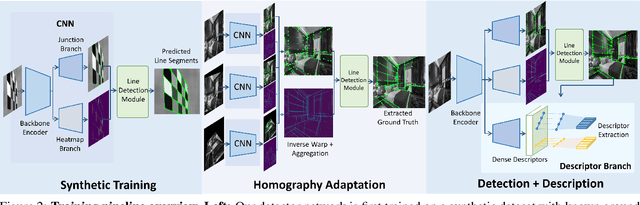
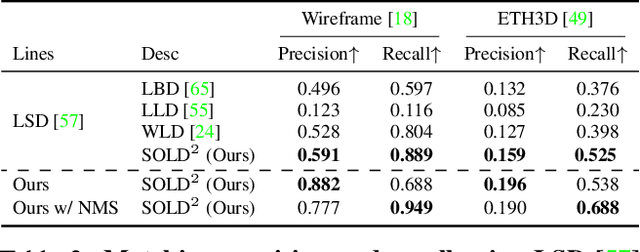
Compared to feature point detection and description, detecting and matching line segments offer additional challenges. Yet, line features represent a promising complement to points for multi-view tasks. Lines are indeed well-defined by the image gradient, frequently appear even in poorly textured areas and offer robust structural cues. We thus hereby introduce the first joint detection and description of line segments in a single deep network. Thanks to a self-supervised training, our method does not require any annotated line labels and can therefore generalize to any dataset. Our detector offers repeatable and accurate localization of line segments in images, departing from the wireframe parsing approach. Leveraging the recent progresses in descriptor learning, our proposed line descriptor is highly discriminative, while remaining robust to viewpoint changes and occlusions. We evaluate our approach against previous line detection and description methods on several multi-view datasets created with homographic warps as well as real-world viewpoint changes. Our full pipeline yields higher repeatability, localization accuracy and matching metrics, and thus represents a first step to bridge the gap with learned feature points methods. Code and trained weights are available at https://github.com/cvg/SOLD2.
Depth Estimation from Monocular Images and Sparse Radar Data
Sep 30, 2020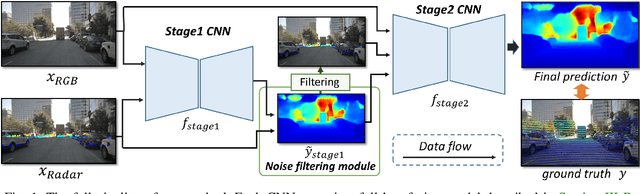
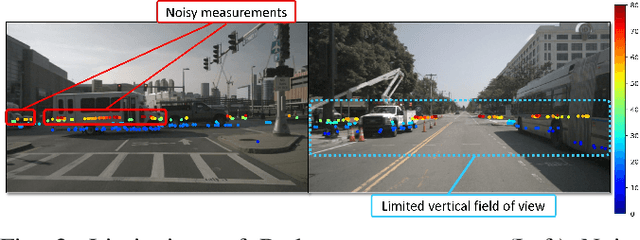
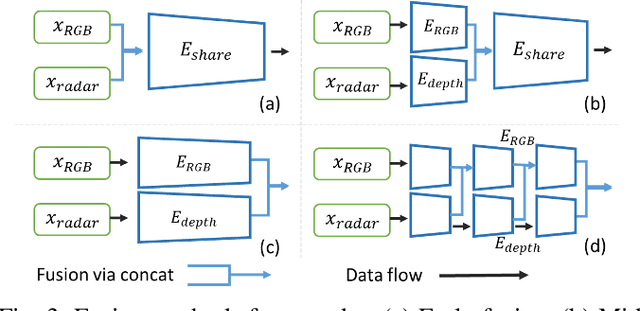

In this paper, we explore the possibility of achieving a more accurate depth estimation by fusing monocular images and Radar points using a deep neural network. We give a comprehensive study of the fusion between RGB images and Radar measurements from different aspects and proposed a working solution based on the observations. We find that the noise existing in Radar measurements is one of the main key reasons that prevents one from applying the existing fusion methods developed for LiDAR data and images to the new fusion problem between Radar data and images. The experiments are conducted on the nuScenes dataset, which is one of the first datasets which features Camera, Radar, and LiDAR recordings in diverse scenes and weather conditions. Extensive experiments demonstrate that our method outperforms existing fusion methods. We also provide detailed ablation studies to show the effectiveness of each component in our method.
Self-Supervised Learning of Depth and Camera Motion from 360° Videos
Nov 13, 2018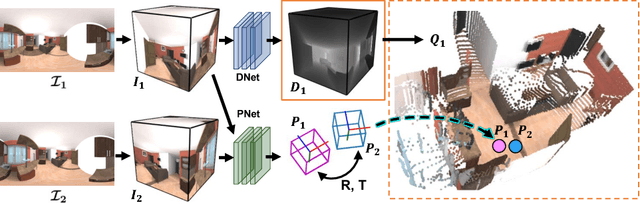
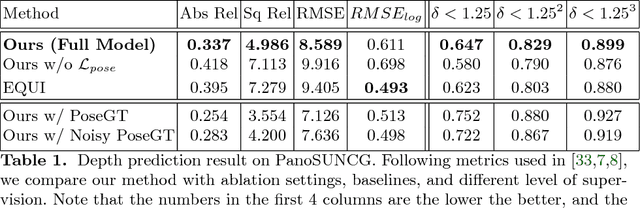
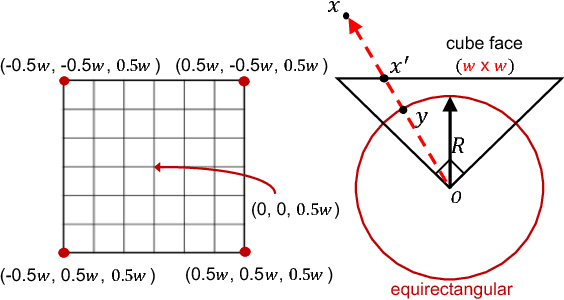
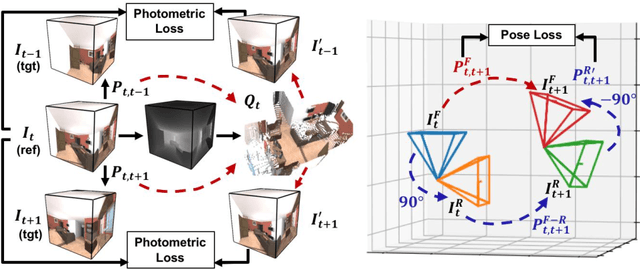
As 360{\deg} cameras become prevalent in many autonomous systems (e.g., self-driving cars and drones), efficient 360{\deg} perception becomes more and more important. We propose a novel self-supervised learning approach for predicting the omnidirectional depth and camera motion from a 360{\deg} video. In particular, starting from the SfMLearner, which is designed for cameras with normal field-of-view, we introduce three key features to process 360{\deg} images efficiently. Firstly, we convert each image from equirectangular projection to cubic projection in order to avoid image distortion. In each network layer, we use Cube Padding (CP), which pads intermediate features from adjacent faces, to avoid image boundaries. Secondly, we propose a novel "spherical" photometric consistency constraint on the whole viewing sphere. In this way, no pixel will be projected outside the image boundary which typically happens in images with normal field-of-view. Finally, rather than naively estimating six independent camera motions (i.e., naively applying SfM-Learner to each face on a cube), we propose a novel camera pose consistency loss to ensure the estimated camera motions reaching consensus. To train and evaluate our approach, we collect a new PanoSUNCG dataset containing a large amount of 360{\deg} videos with groundtruth depth and camera motion. Our approach achieves state-of-the-art depth prediction and camera motion estimation on PanoSUNCG with faster inference speed comparing to equirectangular. In real-world indoor videos, our approach can also achieve qualitatively reasonable depth prediction by acquiring model pre-trained on PanoSUNCG.
Liquid Pouring Monitoring via Rich Sensory Inputs
Aug 06, 2018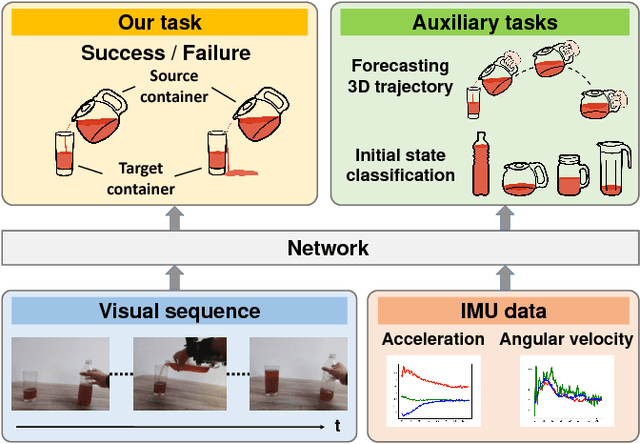
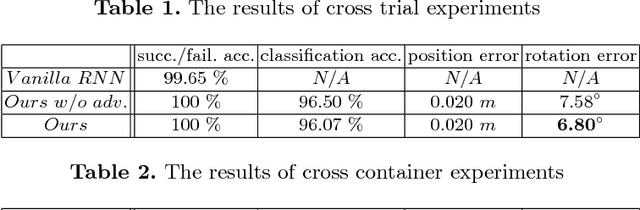
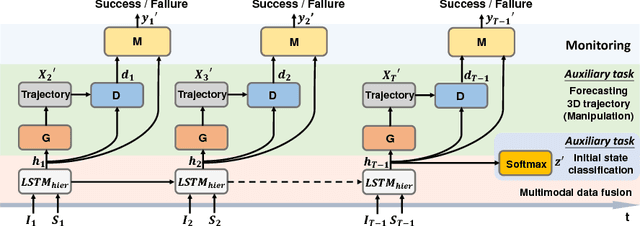
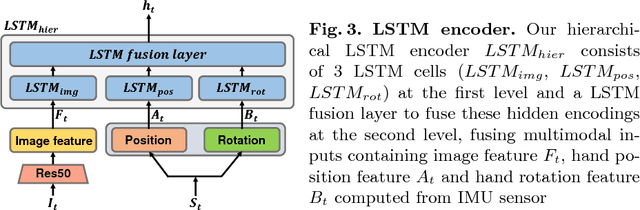
Humans have the amazing ability to perform very subtle manipulation task using a closed-loop control system with imprecise mechanics (i.e., our body parts) but rich sensory information (e.g., vision, tactile, etc.). In the closed-loop system, the ability to monitor the state of the task via rich sensory information is important but often less studied. In this work, we take liquid pouring as a concrete example and aim at learning to continuously monitor whether liquid pouring is successful (e.g., no spilling) or not via rich sensory inputs. We mimic humans' rich sensories using synchronized observation from a chest-mounted camera and a wrist-mounted IMU sensor. Given many success and failure demonstrations of liquid pouring, we train a hierarchical LSTM with late fusion for monitoring. To improve the robustness of the system, we propose two auxiliary tasks during training: inferring (1) the initial state of containers and (2) forecasting the one-step future 3D trajectory of the hand with an adversarial training procedure. These tasks encourage our method to learn representation sensitive to container states and how objects are manipulated in 3D. With these novel components, our method achieves ~8% and ~11% better monitoring accuracy than the baseline method without auxiliary tasks on unseen containers and unseen users respectively.
Omnidirectional CNN for Visual Place Recognition and Navigation
Mar 12, 2018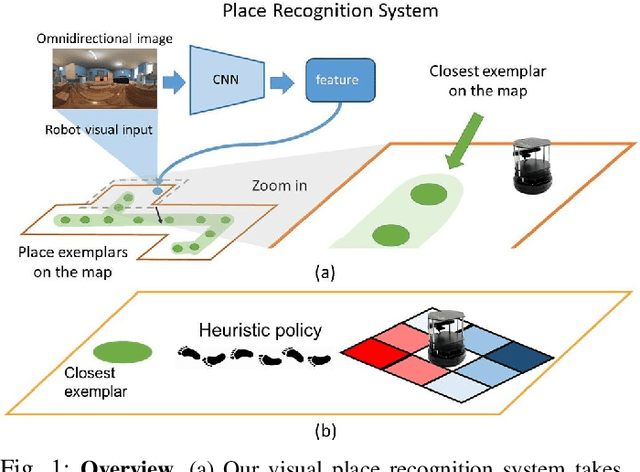
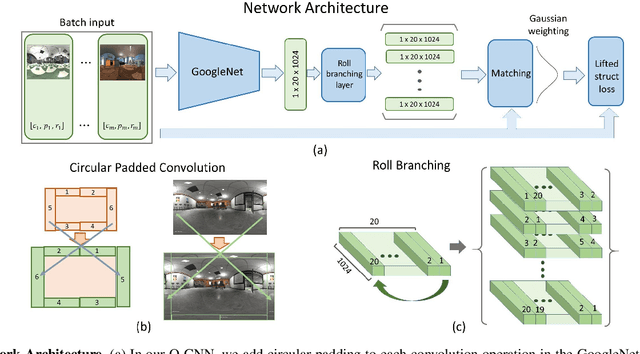
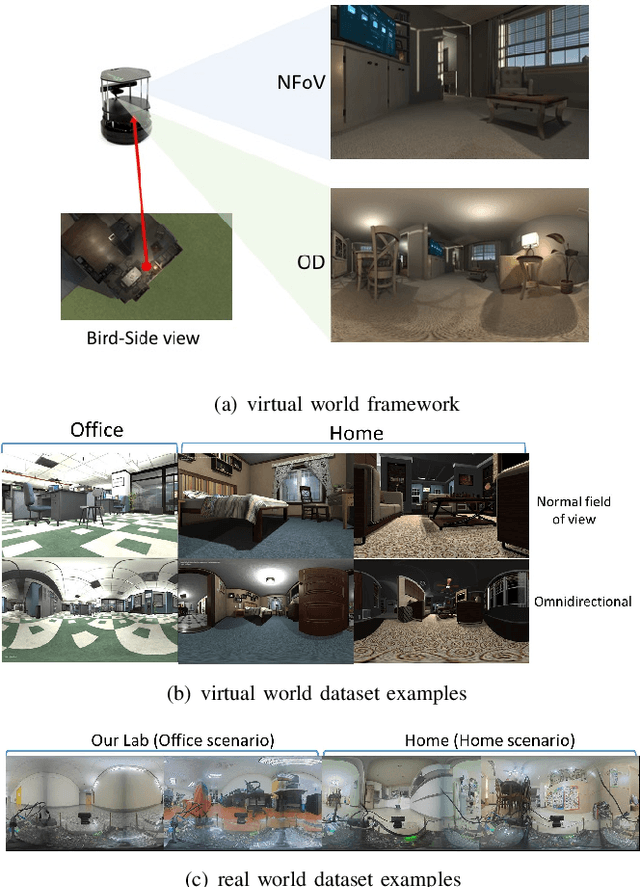
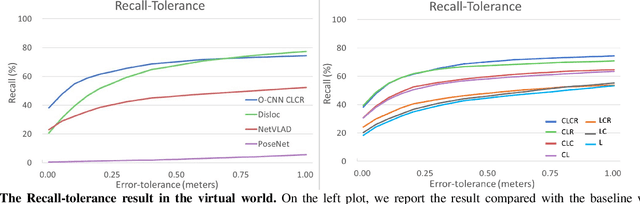
$ $Visual place recognition is challenging, especially when only a few place exemplars are given. To mitigate the challenge, we consider place recognition method using omnidirectional cameras and propose a novel Omnidirectional Convolutional Neural Network (O-CNN) to handle severe camera pose variation. Given a visual input, the task of the O-CNN is not to retrieve the matched place exemplar, but to retrieve the closest place exemplar and estimate the relative distance between the input and the closest place. With the ability to estimate relative distance, a heuristic policy is proposed to navigate a robot to the retrieved closest place. Note that the network is designed to take advantage of the omnidirectional view by incorporating circular padding and rotation invariance. To train a powerful O-CNN, we build a virtual world for training on a large scale. We also propose a continuous lifted structured feature embedding loss to learn the concept of distance efficiently. Finally, our experimental results confirm that our method achieves state-of-the-art accuracy and speed with both the virtual world and real-world datasets.