 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Radiotherapy Target Delineation with 3D-Fused Context Propagation
Dec 12, 2020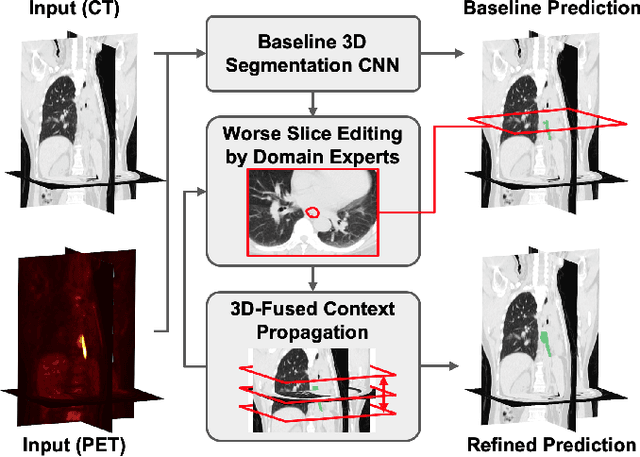
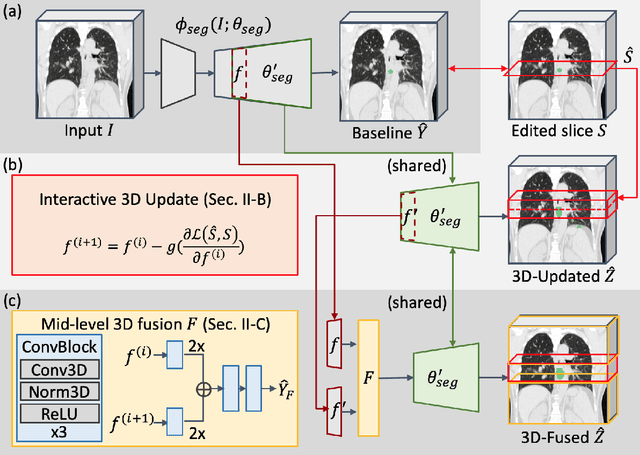

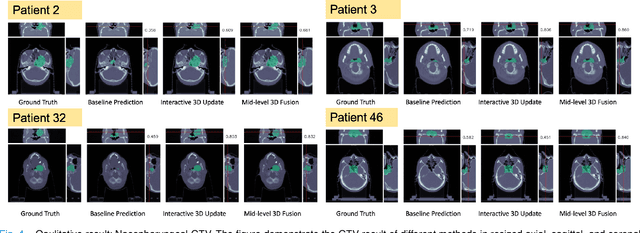
Gross tumor volume (GTV) delineation on tomography medical imaging is crucial for radiotherapy planning and cancer diagnosis. Convolutional neural networks (CNNs) has been predominated on automatic 3D medical segmentation tasks, including contouring the radiotherapy target given 3D CT volume. While CNNs may provide feasible outcome, in clinical scenario, double-check and prediction refinement by experts is still necessary because of CNNs' inconsistent performance on unexpected patient cases. To provide experts an efficient way to modify the CNN predictions without retrain the model, we propose 3D-fused context propagation, which propagates any edited slice to the whole 3D volume. By considering the high-level feature maps, the radiation oncologists would only required to edit few slices to guide the correction and refine the whole prediction volume. Specifically, we leverage the backpropagation for activation technique to convey the user editing information backwardly to the latent space and generate new prediction based on the updated and original feature. During the interaction, our proposed approach reuses the extant extracted features and does not alter the existing 3D CNN model architectures, avoiding the perturbation on other predictions. The proposed method is evaluated on two published radiotherapy target contouring datasets of nasopharyngeal and esophageal cancer. The experimental results demonstrate that our proposed method is able to further effectively improve the existing segmentation prediction from different model architectures given oncologists' interactive inputs.
Self-similarity Student for Partial Label Histopathology Image Segmentation
Jul 19, 2020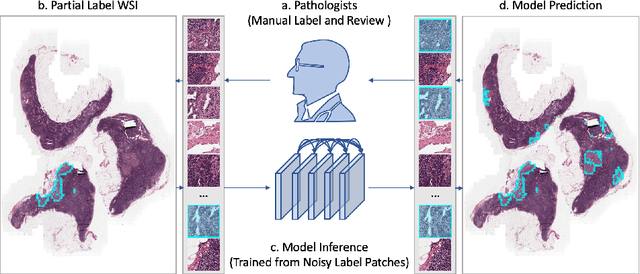
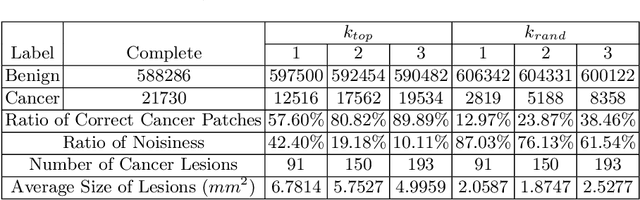
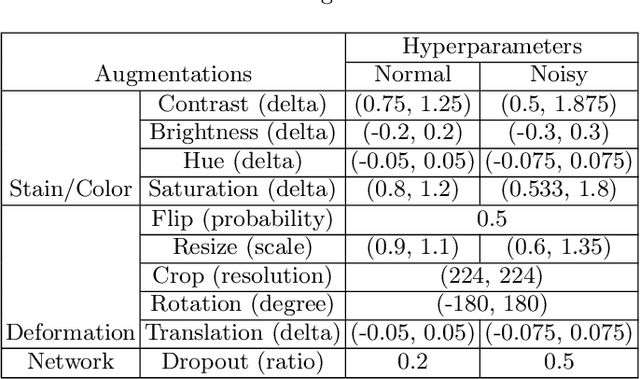
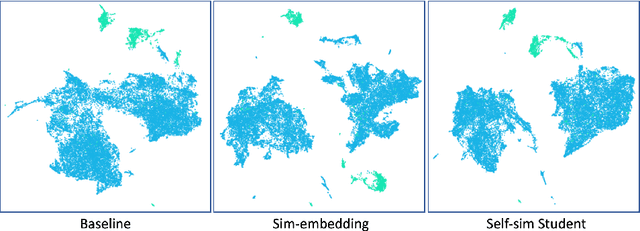
Delineation of cancerous regions in gigapixel whole slide images (WSIs) is a crucial diagnostic procedure in digital pathology. This process is time-consuming because of the large search space in the gigapixel WSIs, causing chances of omission and misinterpretation at indistinct tumor lesions. To tackle this, the development of an automated cancerous region segmentation method is imperative. We frame this issue as a modeling problem with partial label WSIs, where some cancerous regions may be misclassified as benign and vice versa, producing patches with noisy labels. To learn from these patches, we propose Self-similarity Student, combining teacher-student model paradigm with similarity learning. Specifically, for each patch, we first sample its similar and dissimilar patches according to spatial distance. A teacher-student model is then introduced, featuring the exponential moving average on both student model weights and teacher predictions ensemble. While our student model takes patches, teacher model takes all their corresponding similar and dissimilar patches for learning robust representation against noisy label patches. Following this similarity learning, our similarity ensemble merges similar patches' ensembled predictions as the pseudo-label of a given patch to counteract its noisy label. On the CAMELYON16 dataset, our method substantially outperforms state-of-the-art noise-aware learning methods by 5$\%$ and the supervised-trained baseline by 10$\%$ in various degrees of noise. Moreover, our method is superior to the baseline on our TVGH TURP dataset with 2$\%$ improvement, demonstrating the generalizability to more clinical histopathology segmentation tasks.
A Cascaded Learning Strategy for Robust COVID-19 Pneumonia Chest X-Ray Screening
Apr 30, 2020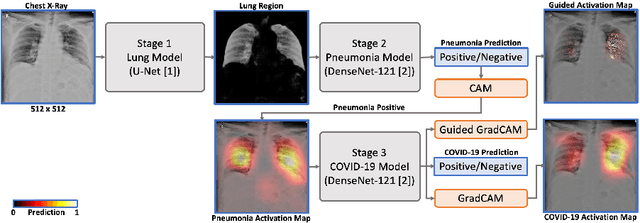
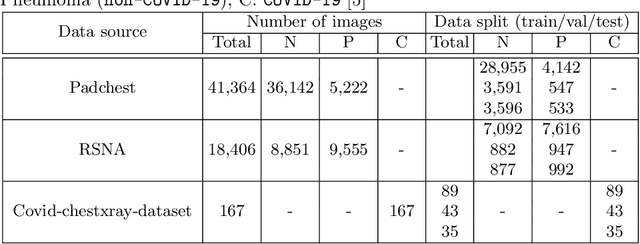
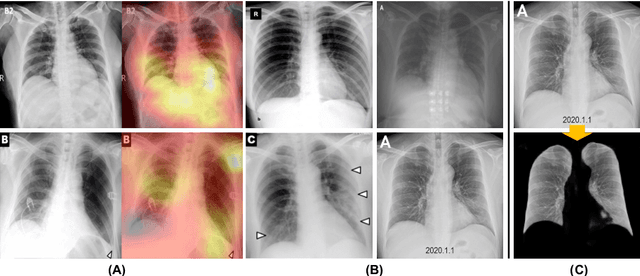
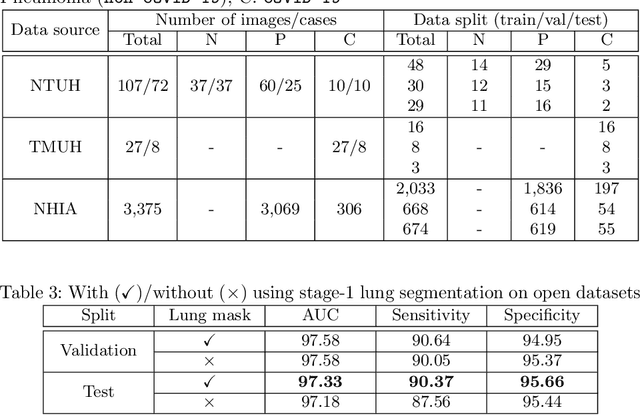
We introduce a comprehensive screening platform for the COVID-19 (a.k.a., SARS-CoV-2) pneumonia. The proposed AI-based system works on chest x-ray (CXR) images to predict whether a patient is infected with the COVID-19 disease. Although the recent international joint effort on making the availability of all sorts of open data, the public collection of CXR images is still relatively small for reliably training a deep neural network (DNN) to carry out COVID-19 prediction. To better address such inefficiency, we design a cascaded learning strategy to improve both the sensitivity and the specificity of the resulting DNN classification model. Our approach leverages a large CXR image dataset of non-COVID-19 pneumonia to generalize the original well-trained classification model via a cascaded learning scheme. The resulting screening system is shown to achieve good classification performance on the expanded dataset, including those newly added COVID-19 CXR images.
Radiotherapy Target Contouring with Convolutional Gated Graph Neural Network
Apr 05, 2019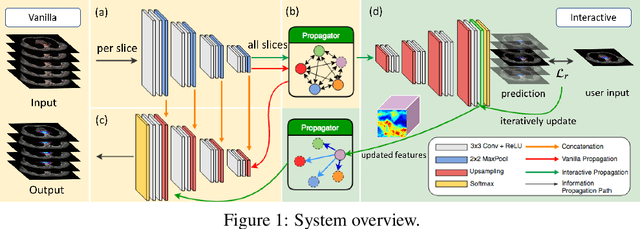
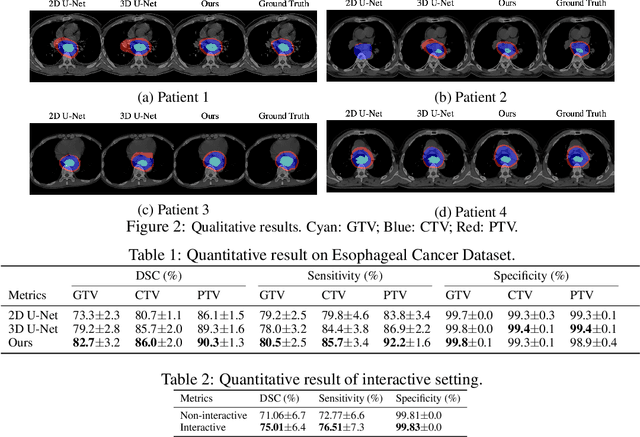
Tomography medical imaging is essential in the clinical workflow of modern cancer radiotherapy. Radiation oncologists identify cancerous tissues, applying delineation on treatment regions throughout all image slices. This kind of task is often formulated as a volumetric segmentation task by means of 3D convolutional networks with considerable computational cost. Instead, inspired by the treating methodology of considering meaningful information across slices, we used Gated Graph Neural Network to frame this problem more efficiently. More specifically, we propose convolutional recurrent Gated Graph Propagator (GGP) to propagate high-level information through image slices, with learnable adjacency weighted matrix. Furthermore, as physicians often investigate a few specific slices to refine their decision, we model this slice-wise interaction procedure to further improve our segmentation result. This can be set by editing any slice effortlessly as updating predictions of other slices using GGP. To evaluate our method, we collect an Esophageal Cancer Radiotherapy Target Treatment Contouring dataset of 81 patients which includes tomography images with radiotherapy target. On this dataset, our convolutional graph network produces state-of-the-art results and outperforms the baselines. With the addition of interactive setting, performance is improved even further. Our method has the potential to be easily applied to diverse kinds of medical tasks with volumetric images. Incorporating both the ability to make a feasible prediction and to consider the human interactive input, the proposed method is suitable for clinical scenarios.
Self-Supervised Learning of Depth and Camera Motion from 360° Videos
Nov 13, 2018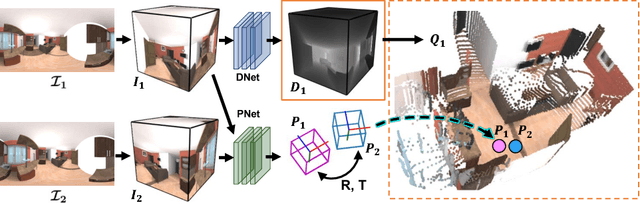
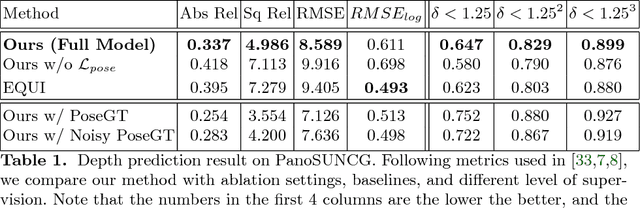
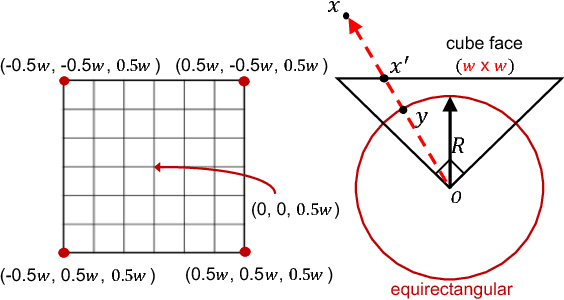
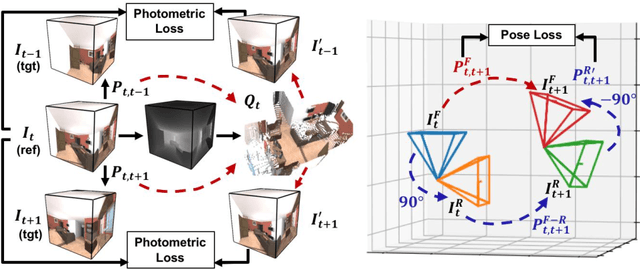
As 360{\deg} cameras become prevalent in many autonomous systems (e.g., self-driving cars and drones), efficient 360{\deg} perception becomes more and more important. We propose a novel self-supervised learning approach for predicting the omnidirectional depth and camera motion from a 360{\deg} video. In particular, starting from the SfMLearner, which is designed for cameras with normal field-of-view, we introduce three key features to process 360{\deg} images efficiently. Firstly, we convert each image from equirectangular projection to cubic projection in order to avoid image distortion. In each network layer, we use Cube Padding (CP), which pads intermediate features from adjacent faces, to avoid image boundaries. Secondly, we propose a novel "spherical" photometric consistency constraint on the whole viewing sphere. In this way, no pixel will be projected outside the image boundary which typically happens in images with normal field-of-view. Finally, rather than naively estimating six independent camera motions (i.e., naively applying SfM-Learner to each face on a cube), we propose a novel camera pose consistency loss to ensure the estimated camera motions reaching consensus. To train and evaluate our approach, we collect a new PanoSUNCG dataset containing a large amount of 360{\deg} videos with groundtruth depth and camera motion. Our approach achieves state-of-the-art depth prediction and camera motion estimation on PanoSUNCG with faster inference speed comparing to equirectangular. In real-world indoor videos, our approach can also achieve qualitatively reasonable depth prediction by acquiring model pre-trained on PanoSUNCG.
Cube Padding for Weakly-Supervised Saliency Prediction in 360° Videos
Jun 04, 2018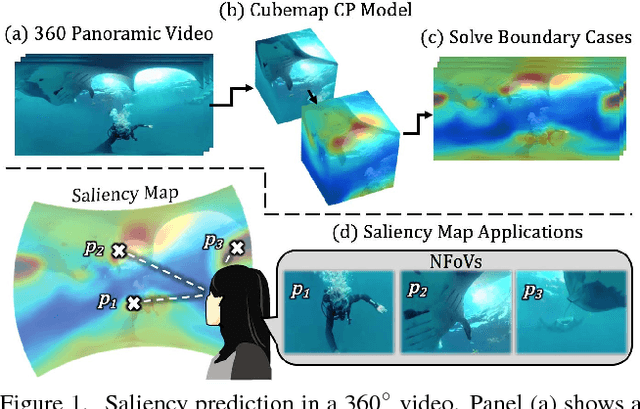
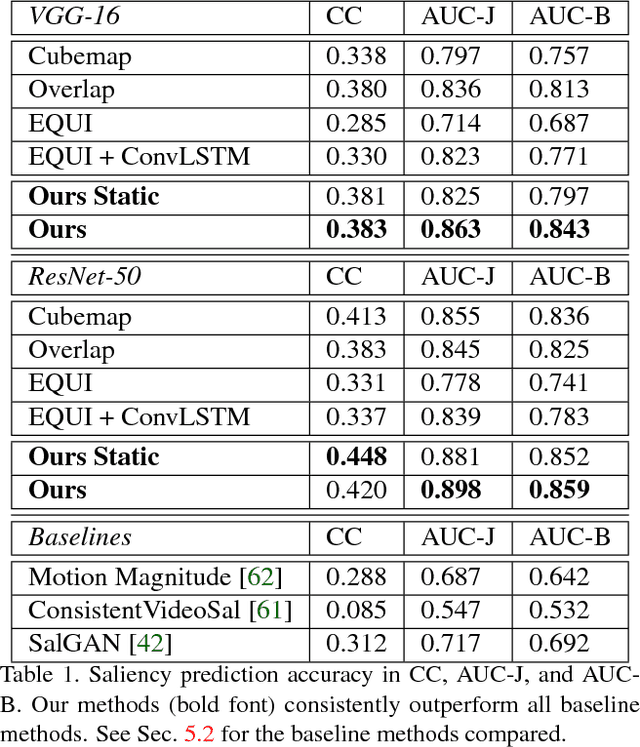
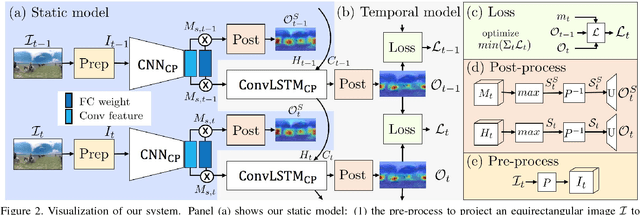
Automatic saliency prediction in 360{\deg} videos is critical for viewpoint guidance applications (e.g., Facebook 360 Guide). We propose a spatial-temporal network which is (1) weakly-supervised trained and (2) tailor-made for 360{\deg} viewing sphere. Note that most existing methods are less scalable since they rely on annotated saliency map for training. Most importantly, they convert 360{\deg} sphere to 2D images (e.g., a single equirectangular image or multiple separate Normal Field-of-View (NFoV) images) which introduces distortion and image boundaries. In contrast, we propose a simple and effective Cube Padding (CP) technique as follows. Firstly, we render the 360{\deg} view on six faces of a cube using perspective projection. Thus, it introduces very little distortion. Then, we concatenate all six faces while utilizing the connectivity between faces on the cube for image padding (i.e., Cube Padding) in convolution, pooling, convolutional LSTM layers. In this way, CP introduces no image boundary while being applicable to almost all Convolutional Neural Network (CNN) structures. To evaluate our method, we propose Wild-360, a new 360{\deg} video saliency dataset, containing challenging videos with saliency heatmap annotations. In experiments, our method outperforms baseline methods in both speed and quality.
Deep 360 Pilot: Learning a Deep Agent for Piloting through 360° Sports Video
May 04, 2017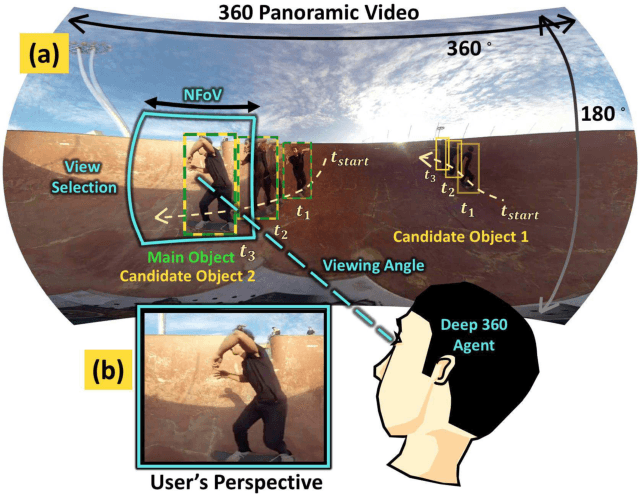

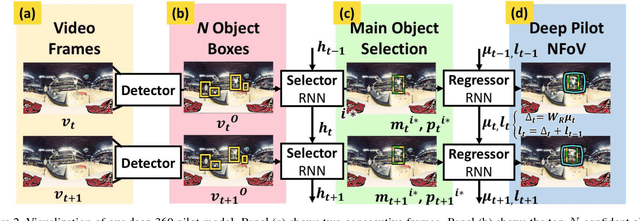
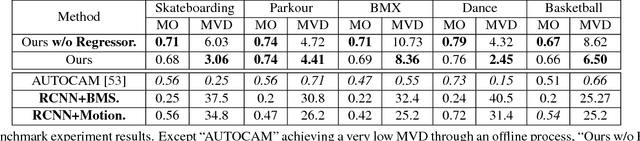
Watching a 360{\deg} sports video requires a viewer to continuously select a viewing angle, either through a sequence of mouse clicks or head movements. To relieve the viewer from this "360 piloting" task, we propose "deep 360 pilot" -- a deep learning-based agent for piloting through 360{\deg} sports videos automatically. At each frame, the agent observes a panoramic image and has the knowledge of previously selected viewing angles. The task of the agent is to shift the current viewing angle (i.e. action) to the next preferred one (i.e., goal). We propose to directly learn an online policy of the agent from data. We use the policy gradient technique to jointly train our pipeline: by minimizing (1) a regression loss measuring the distance between the selected and ground truth viewing angles, (2) a smoothness loss encouraging smooth transition in viewing angle, and (3) maximizing an expected reward of focusing on a foreground object. To evaluate our method, we build a new 360-Sports video dataset consisting of five sports domains. We train domain-specific agents and achieve the best performance on viewing angle selection accuracy and transition smoothness compared to [51] and other baselines.