 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching Toward Pareto-Optimal Device-Aware Neural Architectures
Aug 30, 2018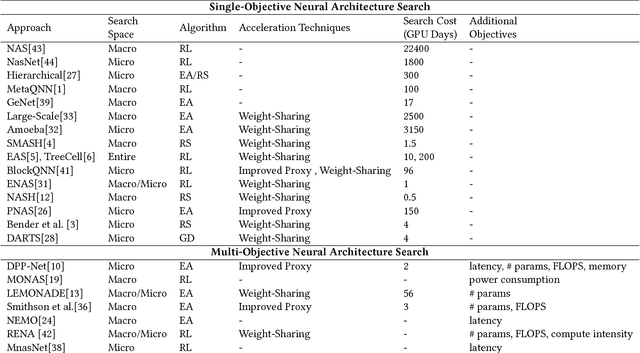
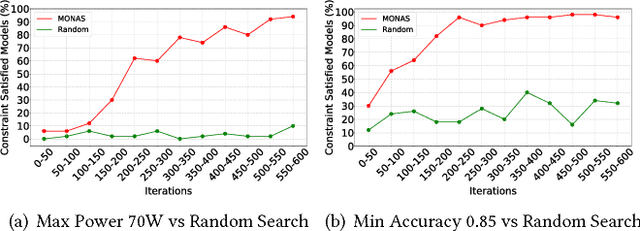
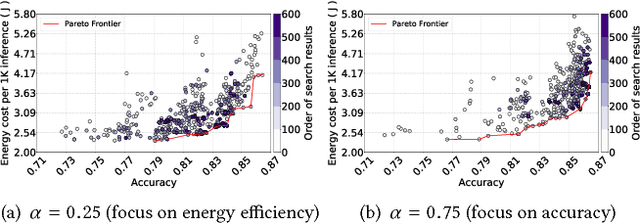
Recent breakthroughs in Neural Architectural Search (NAS) have achieved state-of-the-art performance in many tasks such as image classification and language understanding. However, most existing works only optimize for model accuracy and largely ignore other important factors imposed by the underlying hardware and devices, such as latency and energy, when making inference. In this paper, we first introduce the problem of NAS and provide a survey on recent works. Then we deep dive into two recent advancements on extending NAS into multiple-objective frameworks: MONAS and DPP-Net. Both MONAS and DPP-Net are capable of optimizing accuracy and other objectives imposed by devices, searching for neural architectures that can be best deployed on a wide spectrum of devices: from embedded systems and mobile devices to workstations. Experimental results are poised to show that architectures found by MONAS and DPP-Net achieves Pareto optimality w.r.t the given objectives for various devices.
DPP-Net: Device-aware Progressive Search for Pareto-optimal Neural Architectures
Jul 25, 2018



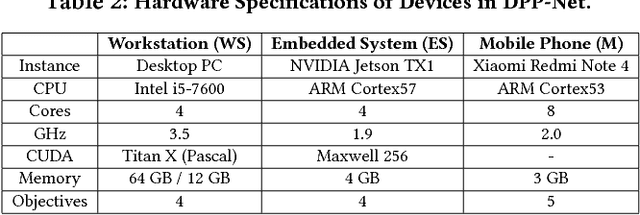
Recent breakthroughs in Neural Architectural Search (NAS) have achieved state-of-the-art performances in applications such as image classification and language modeling. However, these techniques typically ignore device-related objectives such as inference time, memory usage, and power consumption. Optimizing neural architecture for device-related objectives is immensely crucial for deploying deep networks on portable devices with limited computing resources. We propose DPP-Net: Device-aware Progressive Search for Pareto-optimal Neural Architectures, optimizing for both device-related (e.g., inference time and memory usage) and device-agnostic (e.g., accuracy and model size) objectives. DPP-Net employs a compact search space inspired by current state-of-the-art mobile CNNs, and further improves search efficiency by adopting progressive search (Liu et al. 2017). Experimental results on CIFAR-10 are poised to demonstrate the effectiveness of Pareto-optimal networks found by DPP-Net, for three different devices: (1) a workstation with Titan X GPU, (2) NVIDIA Jetson TX1 embedded system, and (3) mobile phone with ARM Cortex-A53. Compared to CondenseNet and NASNet (Mobile), DPP-Net achieves better performances: higher accuracy and shorter inference time on various devices. Additional experimental results show that models found by DPP-Net also achieve considerably-good performance on ImageNet as well.
Cube Padding for Weakly-Supervised Saliency Prediction in 360° Videos
Jun 04, 2018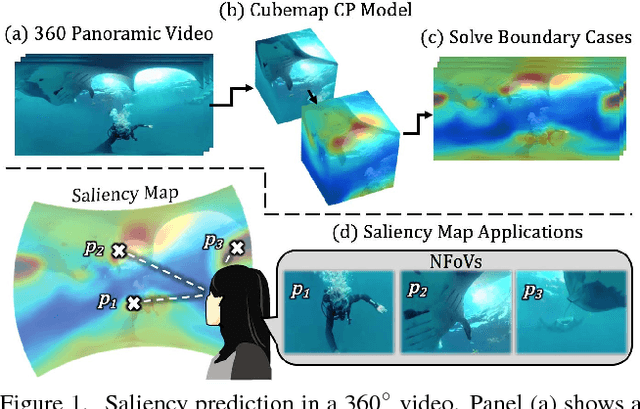
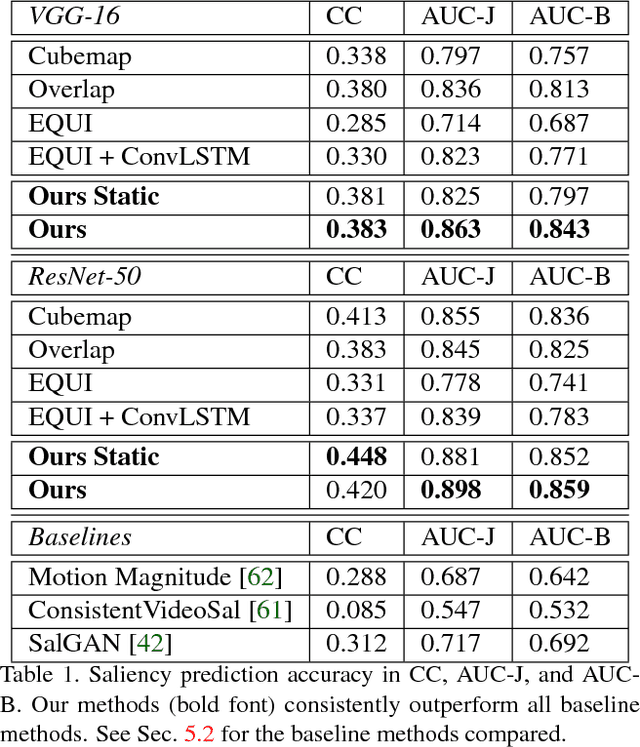
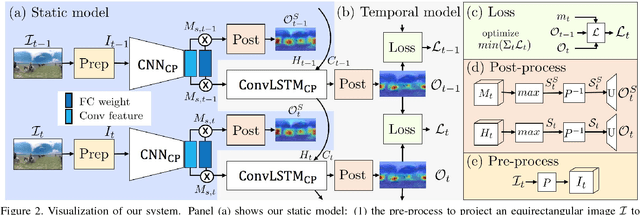
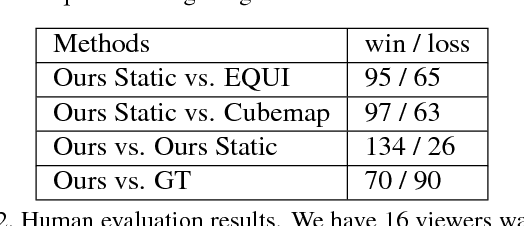
Automatic saliency prediction in 360{\deg} videos is critical for viewpoint guidance applications (e.g., Facebook 360 Guide). We propose a spatial-temporal network which is (1) weakly-supervised trained and (2) tailor-made for 360{\deg} viewing sphere. Note that most existing methods are less scalable since they rely on annotated saliency map for training. Most importantly, they convert 360{\deg} sphere to 2D images (e.g., a single equirectangular image or multiple separate Normal Field-of-View (NFoV) images) which introduces distortion and image boundaries. In contrast, we propose a simple and effective Cube Padding (CP) technique as follows. Firstly, we render the 360{\deg} view on six faces of a cube using perspective projection. Thus, it introduces very little distortion. Then, we concatenate all six faces while utilizing the connectivity between faces on the cube for image padding (i.e., Cube Padding) in convolution, pooling, convolutional LSTM layers. In this way, CP introduces no image boundary while being applicable to almost all Convolutional Neural Network (CNN) structures. To evaluate our method, we propose Wild-360, a new 360{\deg} video saliency dataset, containing challenging videos with saliency heatmap annotations. In experiments, our method outperforms baseline methods in both speed and quality.