 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLIP: Spoof-Aware One-Class Face Anti-Spoofing with Language Image Pretraining
Mar 25, 2025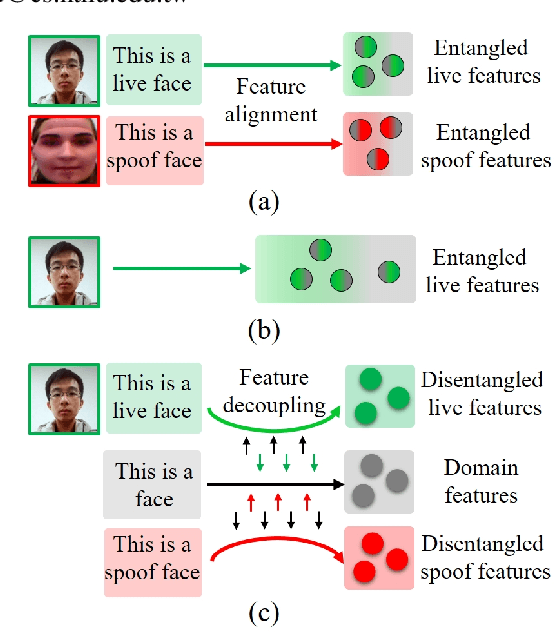

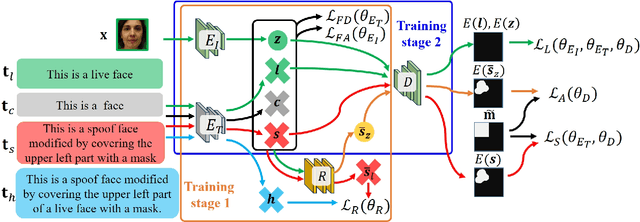

Face anti-spoofing (FAS) plays a pivotal role in ensuring the security and reliability of face recognition systems. With advancements in vision-language pretrained (VLP) models, recent two-class FAS techniques have leveraged the advantages of using VLP guidance, while this potential remains unexplored in one-class FAS methods. The one-class FAS focuses on learning intrinsic liveness features solely from live training images to differentiate between live and spoof faces. However, the lack of spoof training data can lead one-class FAS models to inadvertently incorporate domain information irrelevant to the live/spoof distinction (e.g., facial content), causing performance degradation when tested with a new application domain. To address this issue, we propose a novel framework called Spoof-aware one-class face anti-spoofing with Language Image Pretraining (SLIP). Given that live faces should ideally not be obscured by any spoof-attack-related objects (e.g., paper, or masks) and are assumed to yield zero spoof cue maps, we first propose an effective language-guided spoof cue map estimation to enhance one-class FAS models by simulating whether the underlying faces are covered by attack-related objects and generating corresponding nonzero spoof cue maps. Next, we introduce a novel prompt-driven liveness feature disentanglement to alleviate live/spoof-irrelative domain variations by disentangling live/spoof-relevant and domain-dependent information. Finally, we design an effective augmentation strategy by fusing latent features from live images and spoof prompts to generate spoof-like image features and thus diversify latent spoof features to facilitate the learning of one-class FAS. Our extensive experiments and ablation studies support that SLIP consistently outperforms previous one-class FAS methods.
EigenGS Representation: From Eigenspace to Gaussian Image Space
Mar 10, 2025Principal Component Analysis (PCA), a classical dimensionality reduction technique, and 2D Gaussian representation, an adaptation of 3D Gaussian Splatting for image representation, offer distinct approaches to modeling visual data. We present EigenGS, a novel method that bridges these paradigms through an efficient transformation pipeline connecting eigenspace and image-space Gaussian representations. Our approach enables instant initialization of Gaussian parameters for new images without requiring per-image optimization from scratch, dramatically accelerating convergence. EigenGS introduces a frequency-aware learning mechanism that encourages Gaussians to adapt to different scales, effectively modeling varied spatial frequencies and preventing artifacts in high-resolution reconstruction. Extensive experiments demonstrate that EigenGS not only achieves superior reconstruction quality compared to direct 2D Gaussian fitting but also reduces necessary parameter count and training time. The results highlight EigenGS's effectiveness and generalization ability across images with varying resolutions and diverse categories, making Gaussian-based image representation both high-quality and viable for real-time applications.
DiffusionAtlas: High-Fidelity Consistent Diffusion Video Editing
Dec 05, 2023



We present a diffusion-based video editing framework, namely DiffusionAtlas, which can achieve both frame consistency and high fidelity in editing video object appearance. Despite the success in image editing, diffusion models still encounter significant hindrances when it comes to video editing due to the challenge of maintaining spatiotemporal consistency in the object's appearance across frames. On the other hand, atlas-based techniques allow propagating edits on the layered representations consistently back to frames. However, they often struggle to create editing effects that adhere correctly to the user-provided textual or visual conditions due to the limitation of editing the texture atlas on a fixed UV mapping field. Our method leverages a visual-textual diffusion model to edit objects directly on the diffusion atlases, ensuring coherent object identity across frames. We design a loss term with atlas-based constraints and build a pretrained text-driven diffusion model as pixel-wise guidance for refining shape distortions and correcting texture deviations. Qualitative and quantitative experiments show that our method outperforms state-of-the-art methods in achieving consistent high-fidelity video-object editing.
Capturing Humans in Motion: Temporal-Attentive 3D Human Pose and Shape Estimation from Monocular Video
Mar 16, 2022
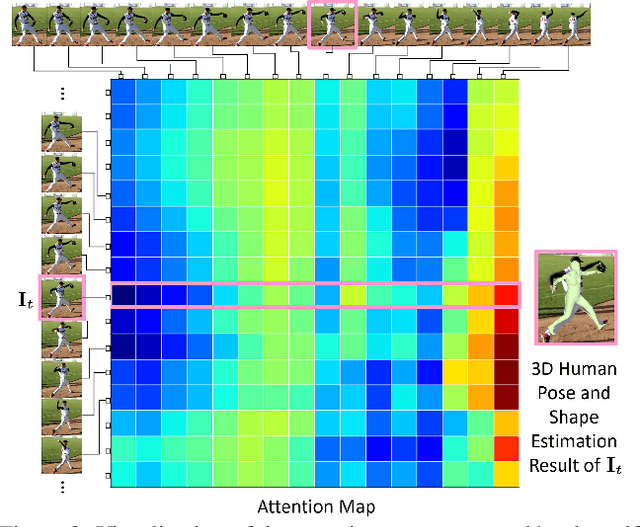
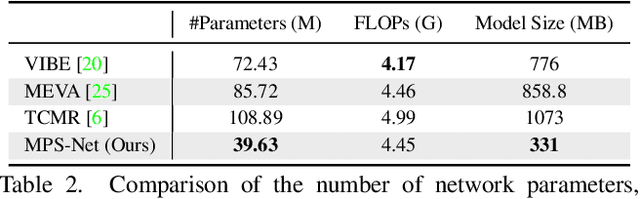
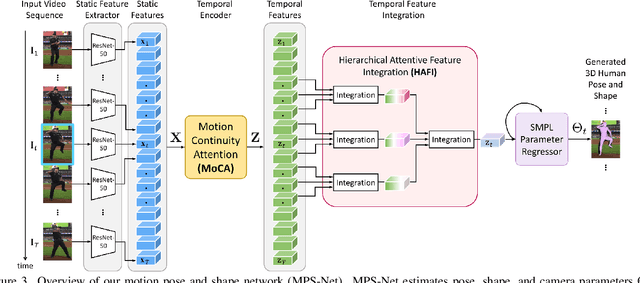
Learning to capture human motion is essential to 3D human pose and shape estimation from monocular video. However, the existing methods mainly rely on recurrent or convolutional operation to model such temporal information, which limits the ability to capture non-local context relations of human motion. To address this problem, we propose a motion pose and shape network (MPS-Net) to effectively capture humans in motion to estimate accurate and temporally coherent 3D human pose and shape from a video. Specifically, we first propose a motion continuity attention (MoCA) module that leverages visual cues observed from human motion to adaptively recalibrate the range that needs attention in the sequence to better capture the motion continuity dependencies. Then, we develop a hierarchical attentive feature integration (HAFI) module to effectively combine adjacent past and future feature representations to strengthen temporal correlation and refine the feature representation of the current frame. By coupling the MoCA and HAFI modules, the proposed MPS-Net excels in estimating 3D human pose and shape in the video. Though conceptually simple, our MPS-Net not only outperforms the state-of-the-art methods on the 3DPW, MPI-INF-3DHP, and Human3.6M benchmark datasets, but also uses fewer network parameters. The video demos can be found at https://mps-net.github.io/MPS-Net/.
Pose Adaptive Dual Mixup for Few-Shot Single-View 3D Reconstruction
Dec 23, 2021
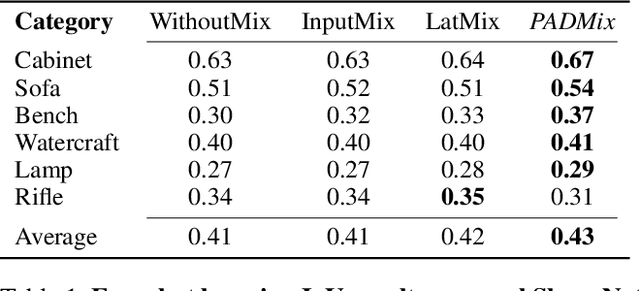

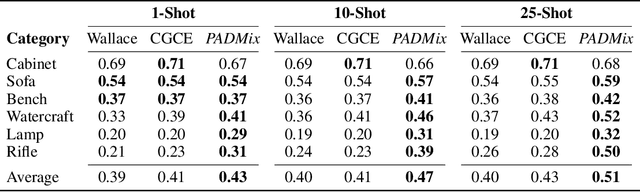
We present a pose adaptive few-shot learning procedure and a two-stage data interpolation regularization, termed Pose Adaptive Dual Mixup (PADMix), for single-image 3D reconstruction. While augmentations via interpolating feature-label pairs are effective in classification tasks, they fall short in shape predictions potentially due to inconsistencies between interpolated products of two images and volumes when rendering viewpoints are unknown. PADMix targets this issue with two sets of mixup procedures performed sequentially. We first perform an input mixup which, combined with a pose adaptive learning procedure, is helpful in learning 2D feature extraction and pose adaptive latent encoding. The stagewise training allows us to build upon the pose invariant representations to perform a follow-up latent mixup under one-to-one correspondences between features and ground-truth volumes. PADMix significantly outperforms previous literature on few-shot settings over the ShapeNet dataset and sets new benchmarks on the more challenging real-world Pix3D dataset.
Decoupled Contrastive Learning
Oct 23, 2021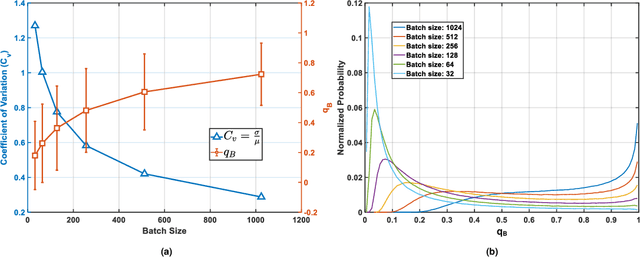
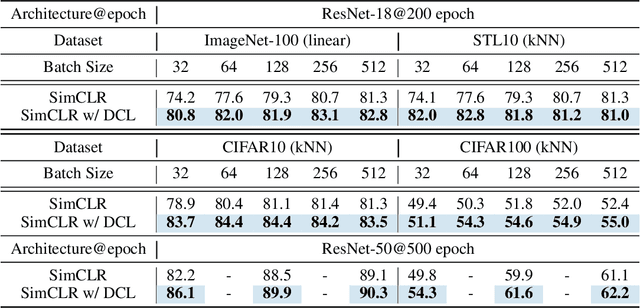
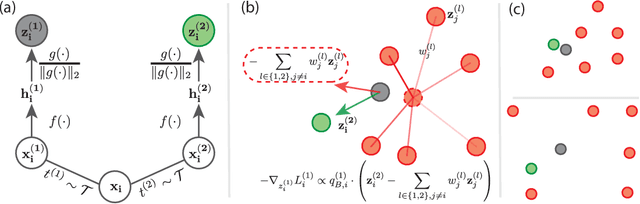

Contrastive learning (CL) is one of the most successful paradigms for self-supervised learning (SSL). In a principled way, it considers two augmented "views" of the same image as positive to be pulled closer, and all other images negative to be pushed further apart. However, behind the impressive success of CL-based techniques, their formulation often relies on heavy-computation settings, including large sample batches, extensive training epochs, etc. We are thus motivated to tackle these issues and aim at establishing a simple, efficient, and yet competitive baseline of contrastive learning. Specifically, we identify, from theoretical and empirical studies, a noticeable negative-positive-coupling (NPC) effect in the widely used cross-entropy (InfoNCE) loss, leading to unsuitable learning efficiency with respect to the batch size. Indeed the phenomenon tends to be neglected in that optimizing infoNCE loss with a small-size batch is effective in solving easier SSL tasks. By properly addressing the NPC effect, we reach a decoupled contrastive learning (DCL) objective function, significantly improving SSL efficiency. DCL can achieve competitive performance, requiring neither large batches in SimCLR, momentum encoding in MoCo, or large epochs. We demonstrate the usefulness of DCL in various benchmarks, while manifesting its robustness being much less sensitive to suboptimal hyperparameters. Notably, our approach achieves $66.9\%$ ImageNet top-1 accuracy using batch size 256 within 200 epochs pre-training, outperforming its baseline SimCLR by $5.1\%$. With further optimized hyperparameters, DCL can improve the accuracy to $68.2\%$. We believe DCL provides a valuable baseline for future contrastive learning-based SSL studies.
Learning Gaussian Instance Segmentation in Point Clouds
Jul 20, 2020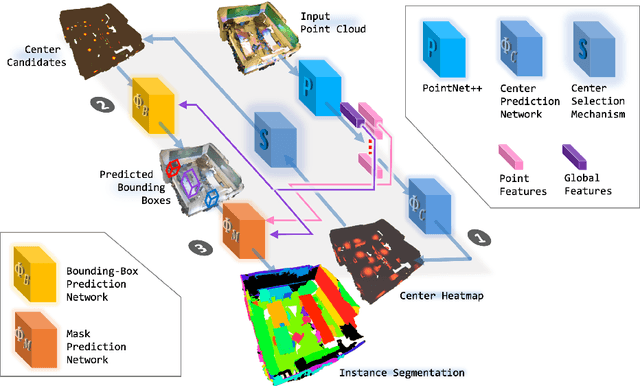
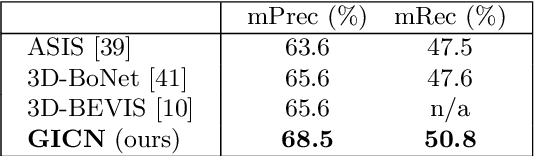
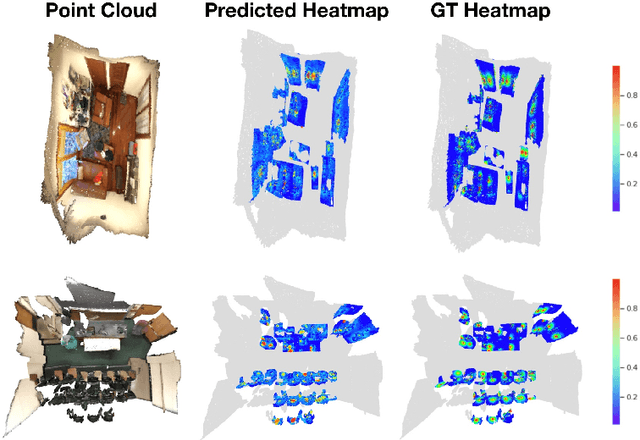
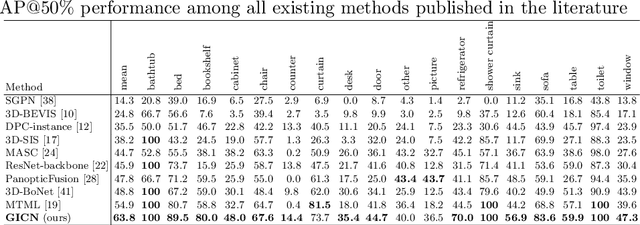
This paper presents a novel method for instance segmentation of 3D point clouds. The proposed method is called Gaussian Instance Center Network (GICN), which can approximate the distributions of instance centers scattered in the whole scene as Gaussian center heatmaps. Based on the predicted heatmaps, a small number of center candidates can be easily selected for the subsequent predictions with efficiency, including i) predicting the instance size of each center to decide a range for extracting features, ii) generating bounding boxes for centers, and iii) producing the final instance masks. GICN is a single-stage, anchor-free, and end-to-end architecture that is easy to train and efficient to perform inference. Benefited from the center-dictated mechanism with adaptive instance size selection, our method achieves state-of-the-art performance in the task of 3D instance segmentation on ScanNet and S3DIS datasets.
Self-similarity Student for Partial Label Histopathology Image Segmentation
Jul 19, 2020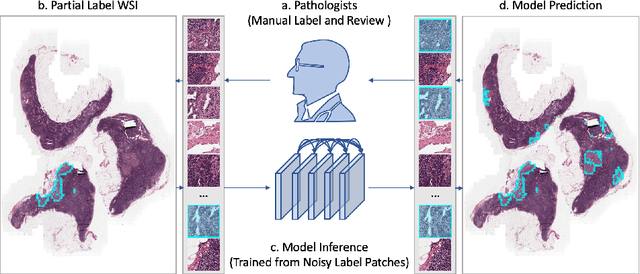
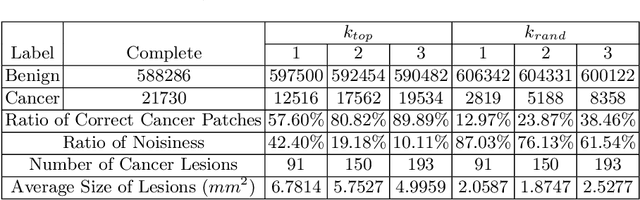
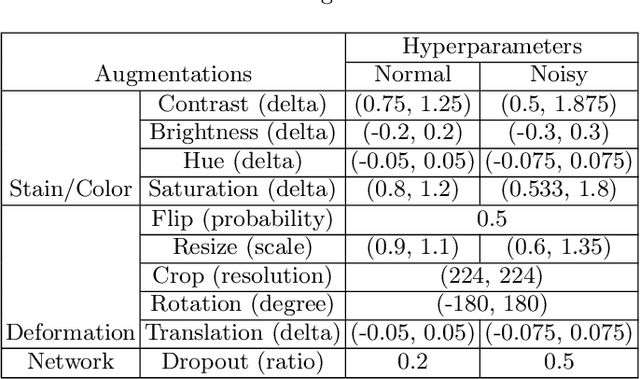
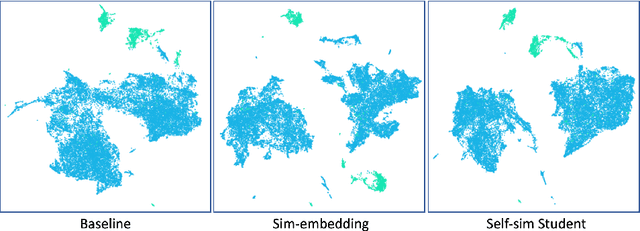
Delineation of cancerous regions in gigapixel whole slide images (WSIs) is a crucial diagnostic procedure in digital pathology. This process is time-consuming because of the large search space in the gigapixel WSIs, causing chances of omission and misinterpretation at indistinct tumor lesions. To tackle this, the development of an automated cancerous region segmentation method is imperative. We frame this issue as a modeling problem with partial label WSIs, where some cancerous regions may be misclassified as benign and vice versa, producing patches with noisy labels. To learn from these patches, we propose Self-similarity Student, combining teacher-student model paradigm with similarity learning. Specifically, for each patch, we first sample its similar and dissimilar patches according to spatial distance. A teacher-student model is then introduced, featuring the exponential moving average on both student model weights and teacher predictions ensemble. While our student model takes patches, teacher model takes all their corresponding similar and dissimilar patches for learning robust representation against noisy label patches. Following this similarity learning, our similarity ensemble merges similar patches' ensembled predictions as the pseudo-label of a given patch to counteract its noisy label. On the CAMELYON16 dataset, our method substantially outperforms state-of-the-art noise-aware learning methods by 5$\%$ and the supervised-trained baseline by 10$\%$ in various degrees of noise. Moreover, our method is superior to the baseline on our TVGH TURP dataset with 2$\%$ improvement, demonstrating the generalizability to more clinical histopathology segmentation tasks.
A Cascaded Learning Strategy for Robust COVID-19 Pneumonia Chest X-Ray Screening
Apr 30, 2020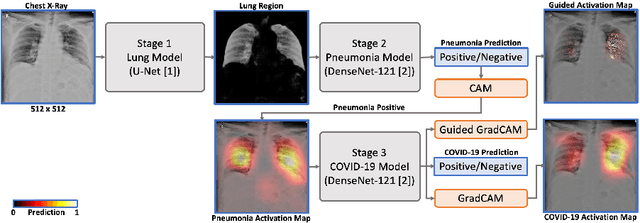
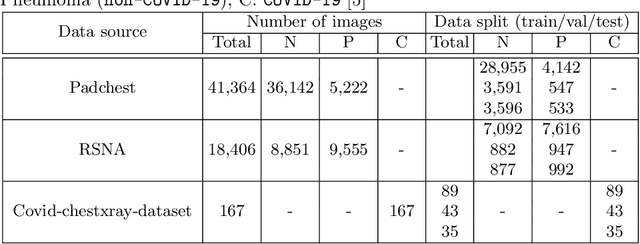
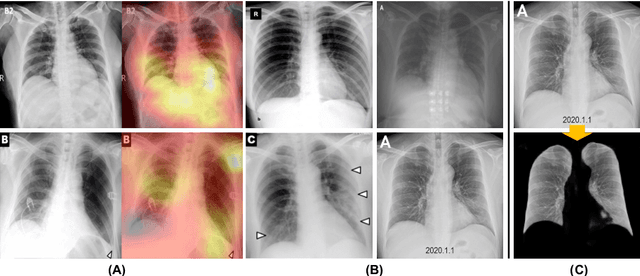
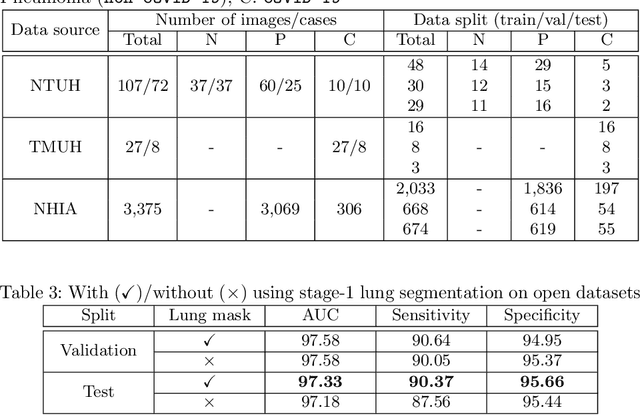
We introduce a comprehensive screening platform for the COVID-19 (a.k.a., SARS-CoV-2) pneumonia. The proposed AI-based system works on chest x-ray (CXR) images to predict whether a patient is infected with the COVID-19 disease. Although the recent international joint effort on making the availability of all sorts of open data, the public collection of CXR images is still relatively small for reliably training a deep neural network (DNN) to carry out COVID-19 prediction. To better address such inefficiency, we design a cascaded learning strategy to improve both the sensitivity and the specificity of the resulting DNN classification model. Our approach leverages a large CXR image dataset of non-COVID-19 pneumonia to generalize the original well-trained classification model via a cascaded learning scheme. The resulting screening system is shown to achieve good classification performance on the expanded dataset, including those newly added COVID-19 CXR images.
One-Shot Object Detection with Co-Attention and Co-Excitation
Nov 28, 2019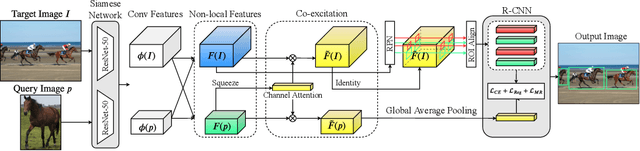

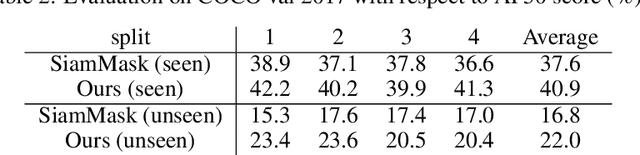
This paper aims to tackle the challenging problem of one-shot object detection. Given a query image patch whose class label is not included in the training data, the goal of the task is to detect all instances of the same class in a target image. To this end, we develop a novel {\em co-attention and co-excitation} (CoAE) framework that makes contributions in three key technical aspects. First, we propose to use the non-local operation to explore the co-attention embodied in each query-target pair and yield region proposals accounting for the one-shot situation. Second, we formulate a squeeze-and-co-excitation scheme that can adaptively emphasize correlated feature channels to help uncover relevant proposals and eventually the target objects. Third, we design a margin-based ranking loss for implicitly learning a metric to predict the similarity of a region proposal to the underlying query, no matter its class label is seen or unseen in training. The resulting model is therefore a two-stage detector that yields a strong baseline on both VOC and MS-COCO under one-shot setting of detecting objects from both seen and never-seen classes. Codes are available at https://github.com/timy90022/One-Shot-Object-Detection.