 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Feature Disentanglement and Augmentation Network for One-class Face Anti-spoofing
Mar 29, 2025Face anti-spoofing (FAS) techniques aim to enhance the security of facial identity authentication by distinguishing authentic live faces from deceptive attempts. While two-class FAS methods risk overfitting to training attacks to achieve better performance, one-class FAS approaches handle unseen attacks well but are less robust to domain information entangled within the liveness features. To address this, we propose an Unsupervised Feature Disentanglement and Augmentation Network (\textbf{UFDANet}), a one-class FAS technique that enhances generalizability by augmenting face images via disentangled features. The \textbf{UFDANet} employs a novel unsupervised feature disentangling method to separate the liveness and domain features, facilitating discriminative feature learning. It integrates an out-of-distribution liveness feature augmentation scheme to synthesize new liveness features of unseen spoof classes, which deviate from the live class, thus enhancing the representability and discriminability of liveness features. Additionally, \textbf{UFDANet} incorporates a domain feature augmentation routine to synthesize unseen domain features, thereby achieving better generalizability. Extensive experiments demonstrate that the proposed \textbf{UFDANet} outperforms previous one-class FAS methods and achieves comparable performance to state-of-the-art two-class FAS methods.
Enhancing Learnable Descriptive Convolutional Vision Transformer for Face Anti-Spoofing
Mar 29, 2025



Face anti-spoofing (FAS) heavily relies on identifying live/spoof discriminative features to counter face presentation attacks. Recently, we proposed LDCformer to successfully incorporate the Learnable Descriptive Convolution (LDC) into ViT, to model long-range dependency of locally descriptive features for FAS. In this paper, we propose three novel training strategies to effectively enhance the training of LDCformer to largely boost its feature characterization capability. The first strategy, dual-attention supervision, is developed to learn fine-grained liveness features guided by regional live/spoof attentions. The second strategy, self-challenging supervision, is designed to enhance the discriminability of the features by generating challenging training data. In addition, we propose a third training strategy, transitional triplet mining strategy, through narrowing the cross-domain gap while maintaining the transitional relationship between live and spoof features, to enlarge the domain-generalization capability of LDCformer. Extensive experiments show that LDCformer under joint supervision of the three novel training strategies outperforms previous methods.
SLIP: Spoof-Aware One-Class Face Anti-Spoofing with Language Image Pretraining
Mar 25, 2025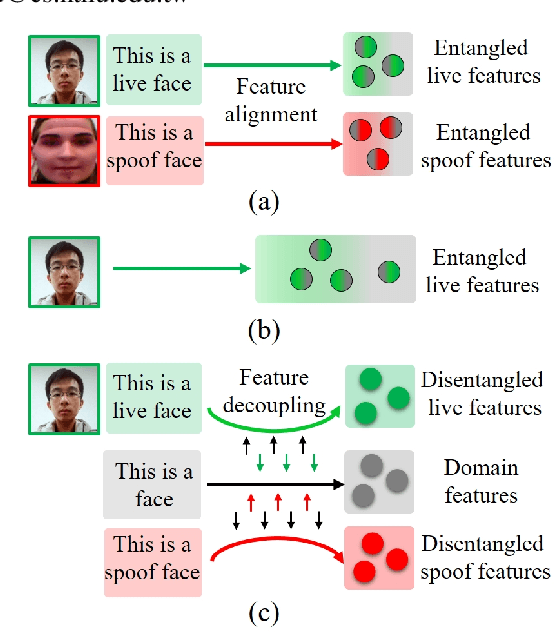

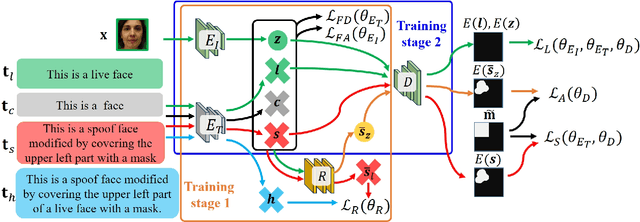

Face anti-spoofing (FAS) plays a pivotal role in ensuring the security and reliability of face recognition systems. With advancements in vision-language pretrained (VLP) models, recent two-class FAS techniques have leveraged the advantages of using VLP guidance, while this potential remains unexplored in one-class FAS methods. The one-class FAS focuses on learning intrinsic liveness features solely from live training images to differentiate between live and spoof faces. However, the lack of spoof training data can lead one-class FAS models to inadvertently incorporate domain information irrelevant to the live/spoof distinction (e.g., facial content), causing performance degradation when tested with a new application domain. To address this issue, we propose a novel framework called Spoof-aware one-class face anti-spoofing with Language Image Pretraining (SLIP). Given that live faces should ideally not be obscured by any spoof-attack-related objects (e.g., paper, or masks) and are assumed to yield zero spoof cue maps, we first propose an effective language-guided spoof cue map estimation to enhance one-class FAS models by simulating whether the underlying faces are covered by attack-related objects and generating corresponding nonzero spoof cue maps. Next, we introduce a novel prompt-driven liveness feature disentanglement to alleviate live/spoof-irrelative domain variations by disentangling live/spoof-relevant and domain-dependent information. Finally, we design an effective augmentation strategy by fusing latent features from live images and spoof prompts to generate spoof-like image features and thus diversify latent spoof features to facilitate the learning of one-class FAS. Our extensive experiments and ablation studies support that SLIP consistently outperforms previous one-class FAS methods.
DD-rPPGNet: De-interfering and Descriptive Feature Learning for Unsupervised rPPG Estimation
Jul 31, 2024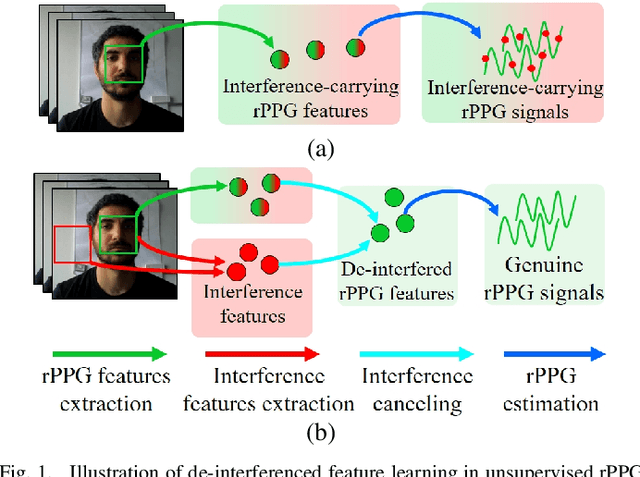
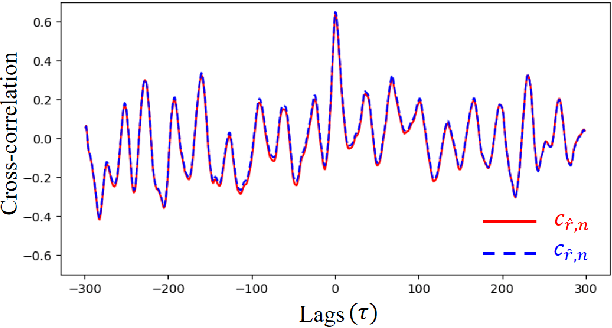
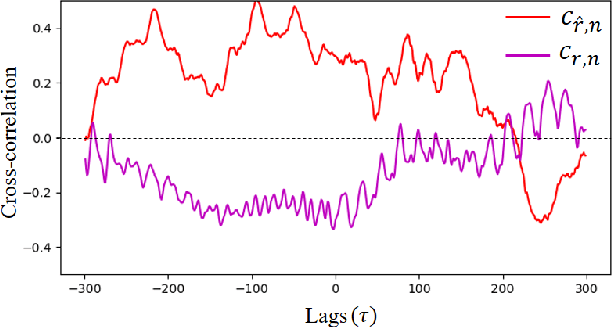
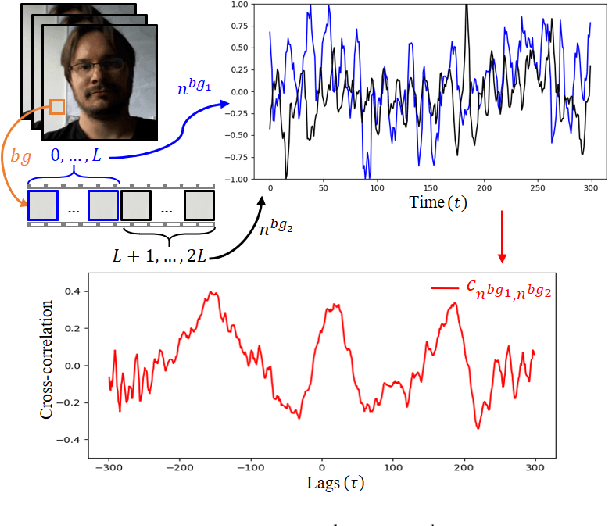
Remote Photoplethysmography (rPPG) aims to measure physiological signals and Heart Rate (HR) from facial videos. Recent unsupervised rPPG estimation methods have shown promising potential in estimating rPPG signals from facial regions without relying on ground truth rPPG signals. However, these methods seem oblivious to interference existing in rPPG signals and still result in unsatisfactory performance. In this paper, we propose a novel De-interfered and Descriptive rPPG Estimation Network (DD-rPPGNet) to eliminate the interference within rPPG features for learning genuine rPPG signals. First, we investigate the characteristics of local spatial-temporal similarities of interference and design a novel unsupervised model to estimate the interference. Next, we propose an unsupervised de-interfered method to learn genuine rPPG signals with two stages. In the first stage, we estimate the initial rPPG signals by contrastive learning from both the training data and their augmented counterparts. In the second stage, we use the estimated interference features to derive de-interfered rPPG features and encourage the rPPG signals to be distinct from the interference. In addition, we propose an effective descriptive rPPG feature learning by developing a strong 3D Learnable Descriptive Convolution (3DLDC) to capture the subtle chrominance changes for enhancing rPPG estimation. Extensive experiments conducted on five rPPG benchmark datasets demonstrate that the proposed DD-rPPGNet outperforms previous unsupervised rPPG estimation methods and achieves competitive performances with state-of-the-art supervised rPPG methods.
Fully Test-Time rPPG Estimation via Synthetic Signal-Guided Feature Learning
Jul 18, 2024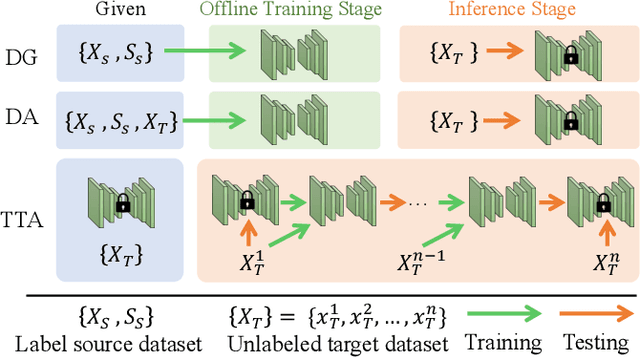
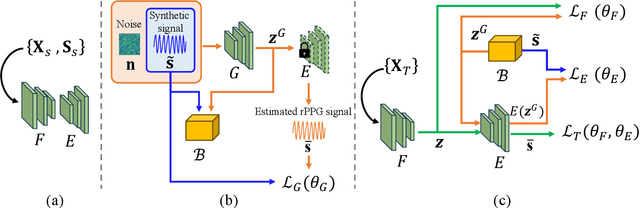
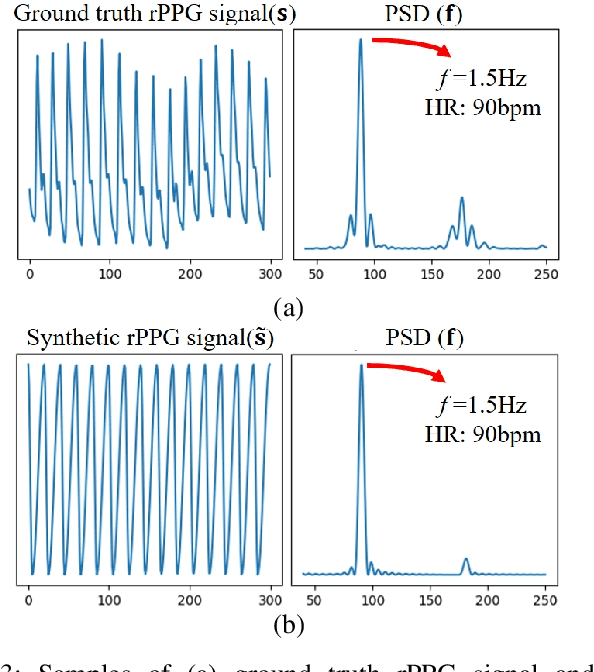
Many remote photoplethysmography (rPPG) estimation models have achieved promising performance on the training domain but often fail to measure the physiological signals or heart rates (HR) on test domains. Domain generalization (DG) or domain adaptation (DA) techniques are therefore adopted in the offline training stage to adapt the model to the unobserved or observed test domain by referring to all the available source domain data. However, in rPPG estimation problems, the adapted model usually confronts challenges of estimating target data with various domain information, such as different video capturing settings, individuals of different age ranges, or of different HR distributions. In contrast, Test-Time Adaptation (TTA), by online adapting to unlabeled target data without referring to any source data, enables the model to adaptively estimate rPPG signals of various unseen domains. In this paper, we first propose a novel TTA-rPPG benchmark, which encompasses various domain information and HR distributions, to simulate the challenges encountered in rPPG estimation. Next, we propose a novel synthetic signal-guided rPPG estimation framework with a two-fold purpose. First, we design an effective spectral-based entropy minimization to enforce the rPPG model to learn new target domain information. Second, we develop a synthetic signal-guided feature learning, by synthesizing pseudo rPPG signals as pseudo ground-truths to guide a conditional generator to generate latent rPPG features. The synthesized rPPG signals and the generated rPPG features are used to guide the rPPG model to broadly cover various HR distributions. Our extensive experiments on the TTA-rPPG benchmark show that the proposed method achieves superior performance and outperforms previous DG and DA methods across most protocols of the proposed TTA-rPPG benchmark.
Generating Self-Guided Dense Annotations for Weakly Supervised Semantic Segmentation
Oct 16, 2018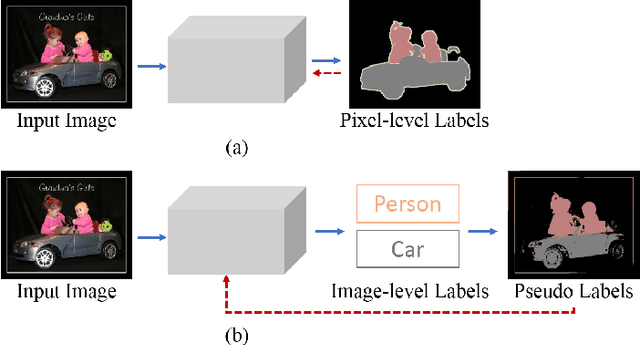
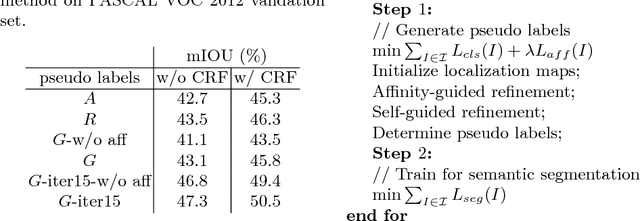
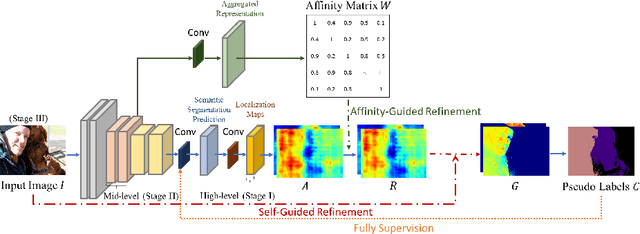
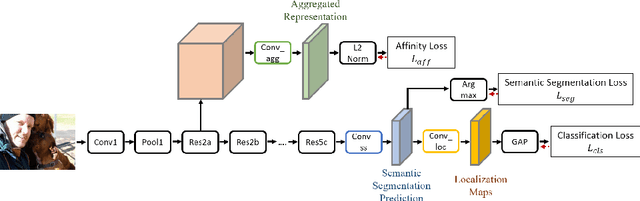
Learning semantic segmentation models under image-level supervision is far more challenging than under fully supervised setting. Without knowing the exact pixel-label correspondence, most weakly-supervised methods rely on external models to infer pseudo pixel-level labels for training semantic segmentation models. In this paper, we aim to develop a single neural network without resorting to any external models. We propose a novel self-guided strategy to fully utilize features learned across multiple levels to progressively generate the dense pseudo labels. First, we use high-level features as class-specific localization maps to roughly locate the classes. Next, we propose an affinity-guided method to encourage each localization map to be consistent with their intermediate level features. Third, we adopt the training image itself as guidance and propose a self-guided refinement to further transfer the image's inherent structure into the maps. Finally, we derive pseudo pixel-level labels from these localization maps and use the pseudo labels as ground truth to train the semantic segmentation model. Our proposed self-guided strategy is a unified framework, which is built on a single network and alternatively updates the feature representation and refines localization maps during the training procedure. Experimental results on PASCAL VOC 2012 segmentation benchmark demonstrate that our method outperforms other weakly-supervised methods under the same setting.
Bayesian image segmentations by Potts prior and loopy belief propagation
Aug 18, 2014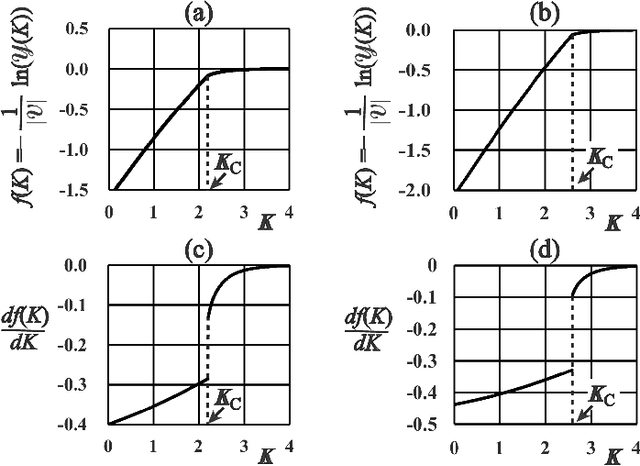
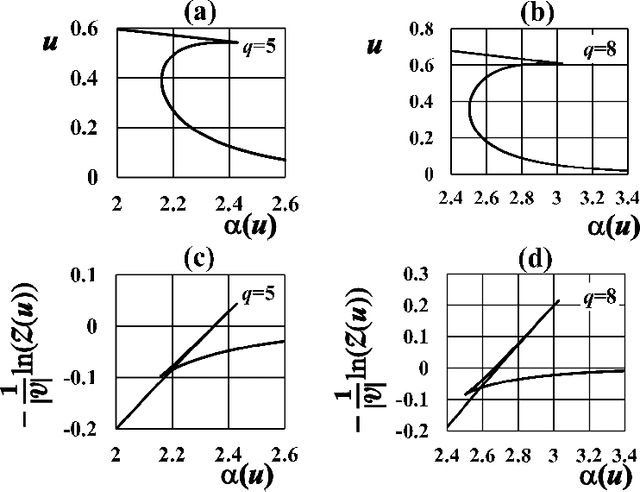


This paper presents a Bayesian image segmentation model based on Potts prior and loopy belief propagation. The proposed Bayesian model involves several terms, including the pairwise interactions of Potts models, and the average vectors and covariant matrices of Gauss distributions in color image modeling. These terms are often referred to as hyperparameters in statistical machine learning theory. In order to determine these hyperparameters, we propose a new scheme for hyperparameter estimation based on conditional maximization of entropy in the Potts prior. The algorithm is given based on loopy belief propagation. In addition, we compare our conditional maximum entropy framework with the conventional maximum likelihood framework, and also clarify how the first order phase transitions in LBP's for Potts models influence our hyperparameter estimation procedures.
* 24 pages, 9 figures