 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Feature Disentanglement and Augmentation Network for One-class Face Anti-spoofing
Mar 29, 2025Face anti-spoofing (FAS) techniques aim to enhance the security of facial identity authentication by distinguishing authentic live faces from deceptive attempts. While two-class FAS methods risk overfitting to training attacks to achieve better performance, one-class FAS approaches handle unseen attacks well but are less robust to domain information entangled within the liveness features. To address this, we propose an Unsupervised Feature Disentanglement and Augmentation Network (\textbf{UFDANet}), a one-class FAS technique that enhances generalizability by augmenting face images via disentangled features. The \textbf{UFDANet} employs a novel unsupervised feature disentangling method to separate the liveness and domain features, facilitating discriminative feature learning. It integrates an out-of-distribution liveness feature augmentation scheme to synthesize new liveness features of unseen spoof classes, which deviate from the live class, thus enhancing the representability and discriminability of liveness features. Additionally, \textbf{UFDANet} incorporates a domain feature augmentation routine to synthesize unseen domain features, thereby achieving better generalizability. Extensive experiments demonstrate that the proposed \textbf{UFDANet} outperforms previous one-class FAS methods and achieves comparable performance to state-of-the-art two-class FAS methods.
Enhancing Learnable Descriptive Convolutional Vision Transformer for Face Anti-Spoofing
Mar 29, 2025



Face anti-spoofing (FAS) heavily relies on identifying live/spoof discriminative features to counter face presentation attacks. Recently, we proposed LDCformer to successfully incorporate the Learnable Descriptive Convolution (LDC) into ViT, to model long-range dependency of locally descriptive features for FAS. In this paper, we propose three novel training strategies to effectively enhance the training of LDCformer to largely boost its feature characterization capability. The first strategy, dual-attention supervision, is developed to learn fine-grained liveness features guided by regional live/spoof attentions. The second strategy, self-challenging supervision, is designed to enhance the discriminability of the features by generating challenging training data. In addition, we propose a third training strategy, transitional triplet mining strategy, through narrowing the cross-domain gap while maintaining the transitional relationship between live and spoof features, to enlarge the domain-generalization capability of LDCformer. Extensive experiments show that LDCformer under joint supervision of the three novel training strategies outperforms previous methods.
SLIP: Spoof-Aware One-Class Face Anti-Spoofing with Language Image Pretraining
Mar 25, 2025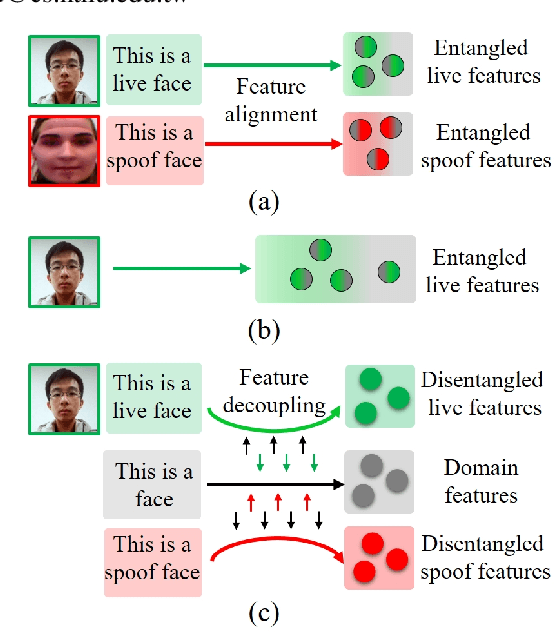

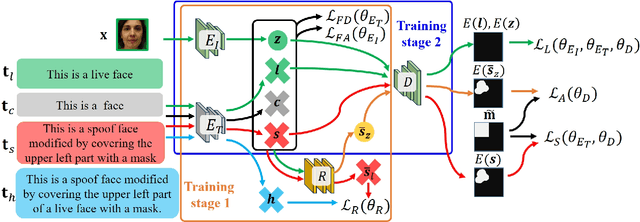

Face anti-spoofing (FAS) plays a pivotal role in ensuring the security and reliability of face recognition systems. With advancements in vision-language pretrained (VLP) models, recent two-class FAS techniques have leveraged the advantages of using VLP guidance, while this potential remains unexplored in one-class FAS methods. The one-class FAS focuses on learning intrinsic liveness features solely from live training images to differentiate between live and spoof faces. However, the lack of spoof training data can lead one-class FAS models to inadvertently incorporate domain information irrelevant to the live/spoof distinction (e.g., facial content), causing performance degradation when tested with a new application domain. To address this issue, we propose a novel framework called Spoof-aware one-class face anti-spoofing with Language Image Pretraining (SLIP). Given that live faces should ideally not be obscured by any spoof-attack-related objects (e.g., paper, or masks) and are assumed to yield zero spoof cue maps, we first propose an effective language-guided spoof cue map estimation to enhance one-class FAS models by simulating whether the underlying faces are covered by attack-related objects and generating corresponding nonzero spoof cue maps. Next, we introduce a novel prompt-driven liveness feature disentanglement to alleviate live/spoof-irrelative domain variations by disentangling live/spoof-relevant and domain-dependent information. Finally, we design an effective augmentation strategy by fusing latent features from live images and spoof prompts to generate spoof-like image features and thus diversify latent spoof features to facilitate the learning of one-class FAS. Our extensive experiments and ablation studies support that SLIP consistently outperforms previous one-class FAS methods.