 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACDG-VTON: Accurate and Contained Diffusion Generation for Virtual Try-On
Mar 20, 2024



Virtual Try-on (VTON) involves generating images of a person wearing selected garments. Diffusion-based methods, in particular, can create high-quality images, but they struggle to maintain the identities of the input garments. We identified this problem stems from the specifics in the training formulation for diffusion. To address this, we propose a unique training scheme that limits the scope in which diffusion is trained. We use a control image that perfectly aligns with the target image during training. In turn, this accurately preserves garment details during inference. We demonstrate our method not only effectively conserves garment details but also allows for layering, styling, and shoe try-on. Our method runs multi-garment try-on in a single inference cycle and can support high-quality zoomed-in generations without training in higher resolutions. Finally, we show our method surpasses prior methods in accuracy and quality.
Preserving Image Properties Through Initializations in Diffusion Models
Jan 04, 2024Retail photography imposes specific requirements on images. For instance, images may need uniform background colors, consistent model poses, centered products, and consistent lighting. Minor deviations from these standards impact a site's aesthetic appeal, making the images unsuitable for use. We show that Stable Diffusion methods, as currently applied, do not respect these requirements. The usual practice of training the denoiser with a very noisy image and starting inference with a sample of pure noise leads to inconsistent generated images during inference. This inconsistency occurs because it is easy to tell the difference between samples of the training and inference distributions. As a result, a network trained with centered retail product images with uniform backgrounds generates images with erratic backgrounds. The problem is easily fixed by initializing inference with samples from an approximation of noisy images. However, in using such an approximation, the joint distribution of text and noisy image at inference time still slightly differs from that at training time. This discrepancy is corrected by training the network with samples from the approximate noisy image distribution. Extensive experiments on real application data show significant qualitative and quantitative improvements in performance from adopting these procedures. Finally, our procedure can interact well with other control-based methods to further enhance the controllability of diffusion-based methods.
DiffusionAtlas: High-Fidelity Consistent Diffusion Video Editing
Dec 05, 2023



We present a diffusion-based video editing framework, namely DiffusionAtlas, which can achieve both frame consistency and high fidelity in editing video object appearance. Despite the success in image editing, diffusion models still encounter significant hindrances when it comes to video editing due to the challenge of maintaining spatiotemporal consistency in the object's appearance across frames. On the other hand, atlas-based techniques allow propagating edits on the layered representations consistently back to frames. However, they often struggle to create editing effects that adhere correctly to the user-provided textual or visual conditions due to the limitation of editing the texture atlas on a fixed UV mapping field. Our method leverages a visual-textual diffusion model to edit objects directly on the diffusion atlases, ensuring coherent object identity across frames. We design a loss term with atlas-based constraints and build a pretrained text-driven diffusion model as pixel-wise guidance for refining shape distortions and correcting texture deviations. Qualitative and quantitative experiments show that our method outperforms state-of-the-art methods in achieving consistent high-fidelity video-object editing.
Wearing the Same Outfit in Different Ways -- A Controllable Virtual Try-on Method
Nov 29, 2022
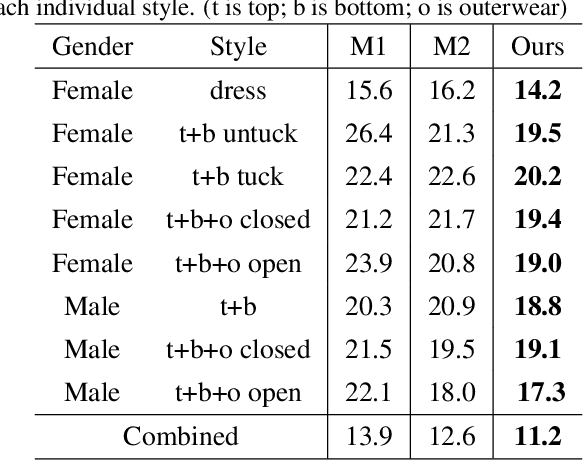


An outfit visualization method generates an image of a person wearing real garments from images of those garments. Current methods can produce images that look realistic and preserve garment identity, captured in details such as collar, cuffs, texture, hem, and sleeve length. However, no current method can both control how the garment is worn -- including tuck or untuck, opened or closed, high or low on the waist, etc.. -- and generate realistic images that accurately preserve the properties of the original garment. We describe an outfit visualization method that controls drape while preserving garment identity. Our system allows instance independent editing of garment drape, which means a user can construct an edit (e.g. tucking a shirt in a specific way) that can be applied to all shirts in a garment collection. Garment detail is preserved by relying on a warping procedure to place the garment on the body and a generator then supplies fine shading detail. To achieve instance independent control, we use control points with garment category-level semantics to guide the warp. The method produces state-of-the-art quality images, while allowing creative ways to style garments, including allowing tops to be tucked or untucked; jackets to be worn open or closed; skirts to be worn higher or lower on the waist; and so on. The method allows interactive control to correct errors in individual renderings too. Because the edits are instance independent, they can be applied to large pools of garments automatically and can be conditioned on garment metadata (e.g. all cropped jackets are worn closed or all bomber jackets are worn closed).