 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvRGB+L: Inverse Rendering of Complex Scenes with Unified Color and LiDAR Reflectance Modeling
Jul 23, 2025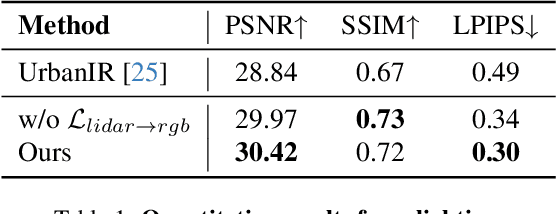

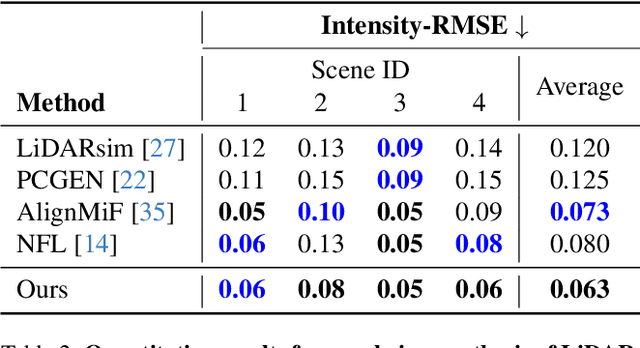
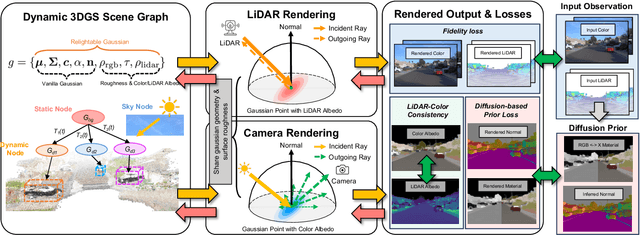
We present InvRGB+L, a novel inverse rendering model that reconstructs large, relightable, and dynamic scenes from a single RGB+LiDAR sequence. Conventional inverse graphics methods rely primarily on RGB observations and use LiDAR mainly for geometric information, often resulting in suboptimal material estimates due to visible light interference. We find that LiDAR's intensity values-captured with active illumination in a different spectral range-offer complementary cues for robust material estimation under variable lighting. Inspired by this, InvRGB+L leverages LiDAR intensity cues to overcome challenges inherent in RGB-centric inverse graphics through two key innovations: (1) a novel physics-based LiDAR shading model and (2) RGB-LiDAR material consistency losses. The model produces novel-view RGB and LiDAR renderings of urban and indoor scenes and supports relighting, night simulations, and dynamic object insertions, achieving results that surpass current state-of-the-art methods in both scene-level urban inverse rendering and LiDAR simulation.
A Snapshot of Influence: A Local Data Attribution Framework for Online Reinforcement Learning
May 25, 2025Online reinforcement learning (RL) excels in complex, safety-critical domains, yet it faces challenges such as sample inefficiency, training instability, and a lack of interpretability. Data attribution offers a principled way to trace model behavior back to individual training samples. However, in online RL, each training sample not only drives policy updates but also influences future data collection, violating the fixed dataset assumption in existing attribution methods. In this paper, we initiate the study of data attribution for online RL, focusing on the widely used Proximal Policy Optimization (PPO) algorithm. We start by establishing a local attribution framework, interpreting model checkpoints with respect to the records in the recent training buffer. We design two target functions, capturing agent action and cumulative return respectively, and measure each record's contribution through gradient similarity between its training loss and these targets. We demonstrate the power of this framework through three concrete applications: diagnosis of learning, temporal analysis of behavior formation, and targeted intervention during training. Leveraging this framework, we further propose an algorithm, iterative influence-based filtering (IIF), for online RL training that iteratively performs experience filtering to refine policy updates. Across standard RL benchmarks (classic control, navigation, locomotion) to RLHF for large language models, IIF reduces sample complexity, speeds up training, and achieves higher returns. Overall, these results advance interpretability, efficiency, and effectiveness of online RL.
How Do I Do That? Synthesizing 3D Hand Motion and Contacts for Everyday Interactions
Apr 16, 2025



We tackle the novel problem of predicting 3D hand motion and contact maps (or Interaction Trajectories) given a single RGB view, action text, and a 3D contact point on the object as input. Our approach consists of (1) Interaction Codebook: a VQVAE model to learn a latent codebook of hand poses and contact points, effectively tokenizing interaction trajectories, (2) Interaction Predictor: a transformer-decoder module to predict the interaction trajectory from test time inputs by using an indexer module to retrieve a latent affordance from the learned codebook. To train our model, we develop a data engine that extracts 3D hand poses and contact trajectories from the diverse HoloAssist dataset. We evaluate our model on a benchmark that is 2.5-10X larger than existing works, in terms of diversity of objects and interactions observed, and test for generalization of the model across object categories, action categories, tasks, and scenes. Experimental results show the effectiveness of our approach over transformer & diffusion baselines across all settings.
Empirical Privacy Variance
Mar 16, 2025We propose the notion of empirical privacy variance and study it in the context of differentially private fine-tuning of language models. Specifically, we show that models calibrated to the same $(\varepsilon, \delta)$-DP guarantee using DP-SGD with different hyperparameter configurations can exhibit significant variations in empirical privacy, which we quantify through the lens of memorization. We investigate the generality of this phenomenon across multiple dimensions and discuss why it is surprising and relevant. Through regression analysis, we examine how individual and composite hyperparameters influence empirical privacy. The results reveal a no-free-lunch trade-off: existing practices of hyperparameter tuning in DP-SGD, which focus on optimizing utility under a fixed privacy budget, often come at the expense of empirical privacy. To address this, we propose refined heuristics for hyperparameter selection that explicitly account for empirical privacy, showing that they are both precise and practically useful. Finally, we take preliminary steps to understand empirical privacy variance. We propose two hypotheses, identify limitations in existing techniques like privacy auditing, and outline open questions for future research.
Improved Convex Decomposition with Ensembling and Boolean Primitives
May 29, 2024



Describing a scene in terms of primitives -- geometrically simple shapes that offer a parsimonious but accurate abstraction of structure -- is an established vision problem. This is a good model of a difficult fitting problem: different scenes require different numbers of primitives and primitives interact strongly, but any proposed solution can be evaluated at inference time. The state of the art method involves a learned regression procedure to predict a start point consisting of a fixed number of primitives, followed by a descent method to refine the geometry and remove redundant primitives. Methods are evaluated by accuracy in depth and normal prediction and in scene segmentation. This paper shows that very significant improvements in accuracy can be obtained by (a) incorporating a small number of negative primitives and (b) ensembling over a number of different regression procedures. Ensembling is by refining each predicted start point, then choosing the best by fitting loss. Extensive experiments on a standard dataset confirm that negative primitives are useful in a large fraction of images, and that our refine-then-choose strategy outperforms choose-then-refine, confirming that the fitting problem is very difficult.
Denoising Monte Carlo Renders With Diffusion Models
Mar 30, 2024Physically-based renderings contain Monte-Carlo noise, with variance that increases as the number of rays per pixel decreases. This noise, while zero-mean for good modern renderers, can have heavy tails (most notably, for scenes containing specular or refractive objects). Learned methods for restoring low fidelity renders are highly developed, because suppressing render noise means one can save compute and use fast renders with few rays per pixel. We demonstrate that a diffusion model can denoise low fidelity renders successfully. Furthermore, our method can be conditioned on a variety of natural render information, and this conditioning helps performance. Quantitative experiments show that our method is competitive with SOTA across a range of sampling rates, but current metrics slightly favor competitor methods. Qualitative examination of the reconstructions suggests that the metrics themselves may not be reliable. The image prior applied by a diffusion method strongly favors reconstructions that are "like" real images -- so have straight shadow boundaries, curved specularities, no "fireflies" and the like -- and metrics do not account for this. We show numerous examples where methods preferred by current metrics produce qualitatively weaker reconstructions than ours.
ACDG-VTON: Accurate and Contained Diffusion Generation for Virtual Try-On
Mar 20, 2024



Virtual Try-on (VTON) involves generating images of a person wearing selected garments. Diffusion-based methods, in particular, can create high-quality images, but they struggle to maintain the identities of the input garments. We identified this problem stems from the specifics in the training formulation for diffusion. To address this, we propose a unique training scheme that limits the scope in which diffusion is trained. We use a control image that perfectly aligns with the target image during training. In turn, this accurately preserves garment details during inference. We demonstrate our method not only effectively conserves garment details but also allows for layering, styling, and shoe try-on. Our method runs multi-garment try-on in a single inference cycle and can support high-quality zoomed-in generations without training in higher resolutions. Finally, we show our method surpasses prior methods in accuracy and quality.
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Feb 06, 2024Automated red teaming holds substantial promise for uncovering and mitigating the risks associated with the malicious use of large language models (LLMs), yet the field lacks a standardized evaluation framework to rigorously assess new methods. To address this issue, we introduce HarmBench, a standardized evaluation framework for automated red teaming. We identify several desirable properties previously unaccounted for in red teaming evaluations and systematically design HarmBench to meet these criteria. Using HarmBench, we conduct a large-scale comparison of 18 red teaming methods and 33 target LLMs and defenses, yielding novel insights. We also introduce a highly efficient adversarial training method that greatly enhances LLM robustness across a wide range of attacks, demonstrating how HarmBench enables codevelopment of attacks and defenses. We open source HarmBench at https://github.com/centerforaisafety/HarmBench.
Preserving Image Properties Through Initializations in Diffusion Models
Jan 04, 2024Retail photography imposes specific requirements on images. For instance, images may need uniform background colors, consistent model poses, centered products, and consistent lighting. Minor deviations from these standards impact a site's aesthetic appeal, making the images unsuitable for use. We show that Stable Diffusion methods, as currently applied, do not respect these requirements. The usual practice of training the denoiser with a very noisy image and starting inference with a sample of pure noise leads to inconsistent generated images during inference. This inconsistency occurs because it is easy to tell the difference between samples of the training and inference distributions. As a result, a network trained with centered retail product images with uniform backgrounds generates images with erratic backgrounds. The problem is easily fixed by initializing inference with samples from an approximation of noisy images. However, in using such an approximation, the joint distribution of text and noisy image at inference time still slightly differs from that at training time. This discrepancy is corrected by training the network with samples from the approximate noisy image distribution. Extensive experiments on real application data show significant qualitative and quantitative improvements in performance from adopting these procedures. Finally, our procedure can interact well with other control-based methods to further enhance the controllability of diffusion-based methods.
Improving Equivariance in State-of-the-Art Supervised Depth and Normal Predictors
Sep 28, 2023



Dense depth and surface normal predictors should possess the equivariant property to cropping-and-resizing -- cropping the input image should result in cropping the same output image. However, we find that state-of-the-art depth and normal predictors, despite having strong performances, surprisingly do not respect equivariance. The problem exists even when crop-and-resize data augmentation is employed during training. To remedy this, we propose an equivariant regularization technique, consisting of an averaging procedure and a self-consistency loss, to explicitly promote cropping-and-resizing equivariance in depth and normal networks. Our approach can be applied to both CNN and Transformer architectures, does not incur extra cost during testing, and notably improves the supervised and semi-supervised learning performance of dense predictors on Taskonomy tasks. Finally, finetuning with our loss on unlabeled images improves not only equivariance but also accuracy of state-of-the-art depth and normal predictors when evaluated on NYU-v2. GitHub link: https://github.com/mikuhatsune/equivariance