 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Blocks World: Moving Things Around in Pictures
Jun 25, 2025We describe Generative Blocks World to interact with the scene of a generated image by manipulating simple geometric abstractions. Our method represents scenes as assemblies of convex 3D primitives, and the same scene can be represented by different numbers of primitives, allowing an editor to move either whole structures or small details. Once the scene geometry has been edited, the image is generated by a flow-based method which is conditioned on depth and a texture hint. Our texture hint takes into account the modified 3D primitives, exceeding texture-consistency provided by existing key-value caching techniques. These texture hints (a) allow accurate object and camera moves and (b) largely preserve the identity of objects depicted. Quantitative and qualitative experiments demonstrate that our approach outperforms prior works in visual fidelity, editability, and compositional generalization.
Improved Convex Decomposition with Ensembling and Boolean Primitives
May 29, 2024



Describing a scene in terms of primitives -- geometrically simple shapes that offer a parsimonious but accurate abstraction of structure -- is an established vision problem. This is a good model of a difficult fitting problem: different scenes require different numbers of primitives and primitives interact strongly, but any proposed solution can be evaluated at inference time. The state of the art method involves a learned regression procedure to predict a start point consisting of a fixed number of primitives, followed by a descent method to refine the geometry and remove redundant primitives. Methods are evaluated by accuracy in depth and normal prediction and in scene segmentation. This paper shows that very significant improvements in accuracy can be obtained by (a) incorporating a small number of negative primitives and (b) ensembling over a number of different regression procedures. Ensembling is by refining each predicted start point, then choosing the best by fitting loss. Extensive experiments on a standard dataset confirm that negative primitives are useful in a large fraction of images, and that our refine-then-choose strategy outperforms choose-then-refine, confirming that the fitting problem is very difficult.
Denoising Monte Carlo Renders With Diffusion Models
Mar 30, 2024Physically-based renderings contain Monte-Carlo noise, with variance that increases as the number of rays per pixel decreases. This noise, while zero-mean for good modern renderers, can have heavy tails (most notably, for scenes containing specular or refractive objects). Learned methods for restoring low fidelity renders are highly developed, because suppressing render noise means one can save compute and use fast renders with few rays per pixel. We demonstrate that a diffusion model can denoise low fidelity renders successfully. Furthermore, our method can be conditioned on a variety of natural render information, and this conditioning helps performance. Quantitative experiments show that our method is competitive with SOTA across a range of sampling rates, but current metrics slightly favor competitor methods. Qualitative examination of the reconstructions suggests that the metrics themselves may not be reliable. The image prior applied by a diffusion method strongly favors reconstructions that are "like" real images -- so have straight shadow boundaries, curved specularities, no "fireflies" and the like -- and metrics do not account for this. We show numerous examples where methods preferred by current metrics produce qualitatively weaker reconstructions than ours.
Blocks2World: Controlling Realistic Scenes with Editable Primitives
Jul 13, 2023



We present Blocks2World, a novel method for 3D scene rendering and editing that leverages a two-step process: convex decomposition of images and conditioned synthesis. Our technique begins by extracting 3D parallelepipeds from various objects in a given scene using convex decomposition, thus obtaining a primitive representation of the scene. These primitives are then utilized to generate paired data through simple ray-traced depth maps. The next stage involves training a conditioned model that learns to generate images from the 2D-rendered convex primitives. This step establishes a direct mapping between the 3D model and its 2D representation, effectively learning the transition from a 3D model to an image. Once the model is fully trained, it offers remarkable control over the synthesis of novel and edited scenes. This is achieved by manipulating the primitives at test time, including translating or adding them, thereby enabling a highly customizable scene rendering process. Our method provides a fresh perspective on 3D scene rendering and editing, offering control and flexibility. It opens up new avenues for research and applications in the field, including authoring and data augmentation.
Applying a Color Palette with Local Control using Diffusion Models
Jul 13, 2023We demonstrate two novel editing procedures in the context of fantasy card art. Palette transfer applies a specified reference palette to a given card. For fantasy art, the desired change in palette can be very large, leading to huge changes in the "look" of the art. We demonstrate that a pipeline of vector quantization; matching; and "vector dequantization" (using a diffusion model) produces successful extreme palette transfers. Segment control allows an artist to move one or more image segments, and to optionally specify the desired color of the result. The combination of these two types of edit yields valuable workflows, including: move a segment, then recolor; recolor, then force some segments to take a prescribed color. We demonstrate our methods on the challenging Yu-Gi-Oh card art dataset.
Convex Decomposition of Indoor Scenes
Jul 13, 2023



We describe a method to parse a complex, cluttered indoor scene into primitives which offer a parsimonious abstraction of scene structure. Our primitives are simple convexes. Our method uses a learned regression procedure to parse a scene into a fixed number of convexes from RGBD input, and can optionally accept segmentations to improve the decomposition. The result is then polished with a descent method which adjusts the convexes to produce a very good fit, and greedily removes superfluous primitives. Because the entire scene is parsed, we can evaluate using traditional depth, normal, and segmentation error metrics. Our evaluation procedure demonstrates that the error from our primitive representation is comparable to that of predicting depth from a single image.
Controlled GAN-Based Creature Synthesis via a Challenging Game Art Dataset -- Addressing the Noise-Latent Trade-Off
Aug 19, 2021

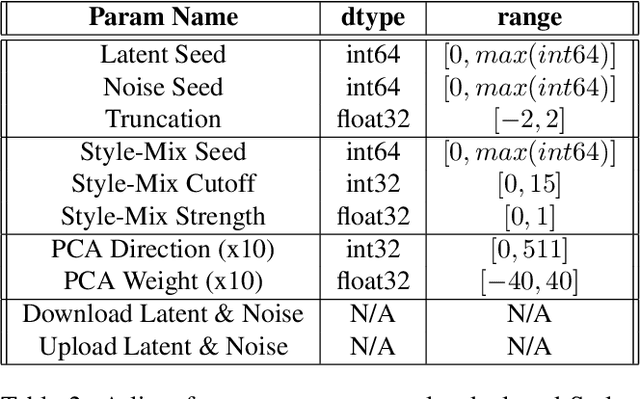

The state-of-the-art StyleGAN2 network supports powerful methods to create and edit art, including generating random images, finding images "like" some query, and modifying content or style. Further, recent advancements enable training with small datasets. We apply these methods to synthesize card art, by training on a novel Yu-Gi-Oh dataset. While noise inputs to StyleGAN2 are essential for good synthesis, we find that, for small datasets, coarse-scale noise interferes with latent variables because both control long-scale image effects. We observe over-aggressive variation in art with changes in noise and weak content control via latent variable edits. Here, we demonstrate that training a modified StyleGAN2, where coarse-scale noise is suppressed, removes these unwanted effects. We obtain a superior FID; changes in noise result in local exploration of style; and identity control is markedly improved. These results and analysis lead towards a GAN-assisted art synthesis tool for digital artists of all skill levels, which can be used in film, games, or any creative industry for artistic ideation.