 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNERFIFY: A Multi-Agent Framework for Turning NeRF Papers into Code
Feb 28, 2026The proliferation of neural radiance field (NeRF) research requires significant efforts to reimplement papers before building upon them. We introduce NERFIFY, a multi-agent framework that reliably converts NeRF research papers into trainable Nerfstudio plugins, in contrast to generic paper-to-code methods and frontier models like GPT-5 that usually fail to produce runnable code. NERFIFY achieves domain-specific executability through six key innovations: (1) Context-free grammar (CFG): LLM synthesis is constrained by Nerfstudio formalized as a CFG, ensuring generated code satisfies architectural invariants. (2) Graph-of-Thought code synthesis: Specialized multi-file-agents generate repositories in topological dependency order, validating contracts and errors at each node. (3) Compositional citation recovery: Agents automatically retrieve and integrate components (samplers, encoders, proposal networks) from citation graphs of references. (4) Visual feedback: Artifacts are diagnosed through PSNR-minima ROI analysis, cross-view geometric validation, and VLM-guided patching to iteratively improve quality. (5) Knowledge enhancement: Beyond reproduction, methods can be improved with novel optimizations. (6) Benchmarking: An evaluation framework is designed for NeRF paper-to-code synthesis across 30 diverse papers. On papers without public implementations, NERFIFY achieves visual quality matching expert human code (+/-0.5 dB PSNR, +/-0.2 SSIM) while reducing implementation time from weeks to minutes. NERFIFY demonstrates that a domain-aware design enables code translation for complex vision papers, potentiating accelerated and democratized reproducible research. Code, data and implementations will be publicly released.
Generative Blocks World: Moving Things Around in Pictures
Jun 25, 2025We describe Generative Blocks World to interact with the scene of a generated image by manipulating simple geometric abstractions. Our method represents scenes as assemblies of convex 3D primitives, and the same scene can be represented by different numbers of primitives, allowing an editor to move either whole structures or small details. Once the scene geometry has been edited, the image is generated by a flow-based method which is conditioned on depth and a texture hint. Our texture hint takes into account the modified 3D primitives, exceeding texture-consistency provided by existing key-value caching techniques. These texture hints (a) allow accurate object and camera moves and (b) largely preserve the identity of objects depicted. Quantitative and qualitative experiments demonstrate that our approach outperforms prior works in visual fidelity, editability, and compositional generalization.
Latent Intrinsics Emerge from Training to Relight
May 31, 2024



Image relighting is the task of showing what a scene from a source image would look like if illuminated differently. Inverse graphics schemes recover an explicit representation of geometry and a set of chosen intrinsics, then relight with some form of renderer. However error control for inverse graphics is difficult, and inverse graphics methods can represent only the effects of the chosen intrinsics. This paper describes a relighting method that is entirely data-driven, where intrinsics and lighting are each represented as latent variables. Our approach produces SOTA relightings of real scenes, as measured by standard metrics. We show that albedo can be recovered from our latent intrinsics without using any example albedos, and that the albedos recovered are competitive with SOTA methods.
Improved Convex Decomposition with Ensembling and Boolean Primitives
May 29, 2024



Describing a scene in terms of primitives -- geometrically simple shapes that offer a parsimonious but accurate abstraction of structure -- is an established vision problem. This is a good model of a difficult fitting problem: different scenes require different numbers of primitives and primitives interact strongly, but any proposed solution can be evaluated at inference time. The state of the art method involves a learned regression procedure to predict a start point consisting of a fixed number of primitives, followed by a descent method to refine the geometry and remove redundant primitives. Methods are evaluated by accuracy in depth and normal prediction and in scene segmentation. This paper shows that very significant improvements in accuracy can be obtained by (a) incorporating a small number of negative primitives and (b) ensembling over a number of different regression procedures. Ensembling is by refining each predicted start point, then choosing the best by fitting loss. Extensive experiments on a standard dataset confirm that negative primitives are useful in a large fraction of images, and that our refine-then-choose strategy outperforms choose-then-refine, confirming that the fitting problem is very difficult.
Blocks2World: Controlling Realistic Scenes with Editable Primitives
Jul 13, 2023



We present Blocks2World, a novel method for 3D scene rendering and editing that leverages a two-step process: convex decomposition of images and conditioned synthesis. Our technique begins by extracting 3D parallelepipeds from various objects in a given scene using convex decomposition, thus obtaining a primitive representation of the scene. These primitives are then utilized to generate paired data through simple ray-traced depth maps. The next stage involves training a conditioned model that learns to generate images from the 2D-rendered convex primitives. This step establishes a direct mapping between the 3D model and its 2D representation, effectively learning the transition from a 3D model to an image. Once the model is fully trained, it offers remarkable control over the synthesis of novel and edited scenes. This is achieved by manipulating the primitives at test time, including translating or adding them, thereby enabling a highly customizable scene rendering process. Our method provides a fresh perspective on 3D scene rendering and editing, offering control and flexibility. It opens up new avenues for research and applications in the field, including authoring and data augmentation.
An Efficient Anomaly Detection Approach using Cube Sampling with Streaming Data
Oct 05, 2021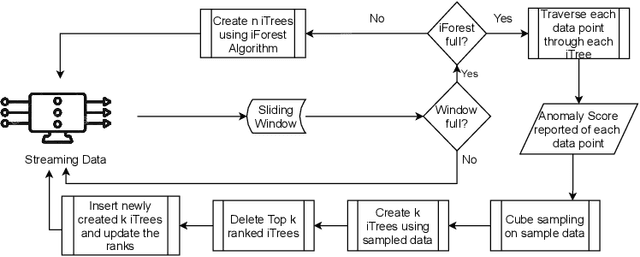

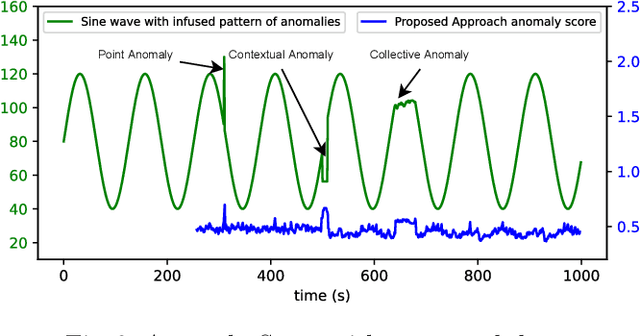
Anomaly detection is critical in various fields, including intrusion detection, health monitoring, fault diagnosis, and sensor network event detection. The isolation forest (or iForest) approach is a well-known technique for detecting anomalies. It is, however, ineffective when dealing with dynamic streaming data, which is becoming increasingly prevalent in a wide variety of application areas these days. In this work, we extend our previous work by proposed an efficient iForest based approach for anomaly detection using cube sampling that is effective on streaming data. Cube sampling is used in the initial stage to choose nearly balanced samples, significantly reducing storage requirements while preserving efficiency. Following that, the streaming nature of data is addressed by a sliding window technique that generates consecutive chunks of data for systematic processing. The novelty of this paper is in applying Cube sampling in iForest and calculating inclusion probability. The proposed approach is equally successful at detecting anomalies as existing state-of-the-art approaches, requiring significantly less storage and time complexity. We undertake empirical evaluations of the proposed approach using standard datasets and demonstrate that it outperforms traditional approaches in terms of Area Under the ROC Curve (AUC-ROC) and can handle high-dimensional streaming data.
An Energy Efficient Health Monitoring Approach with Wireless Body Area Networks
Sep 27, 2021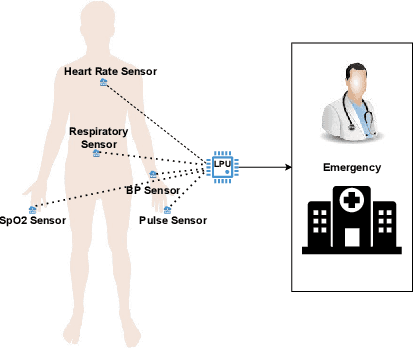

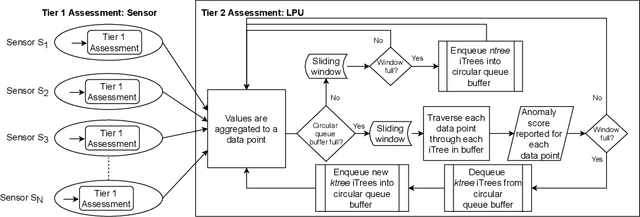

Wireless Body Area Networks (WBANs) comprise a network of sensors subcutaneously implanted or placed near the body surface and facilitate continuous monitoring of health parameters of a patient. Research endeavours involving WBAN are directed towards effective transmission of detected parameters to a Local Processing Unit (LPU, usually a mobile device) and analysis of the parameters at the LPU or a back-end cloud. An important concern in WBAN is the lightweight nature of WBAN nodes and the need to conserve their energy. This is especially true for subcutaneously implanted nodes that cannot be recharged or regularly replaced. Work in energy conservation is mostly aimed at optimising the routing of signals to minimise energy expended. In this paper, a simple yet innovative approach to energy conservation and detection of alarming health status is proposed. Energy conservation is ensured through a two-tier approach wherein the first tier eliminates `uninteresting' health parameter readings at the site of a sensing node and prevents these from being transmitted across the WBAN to the LPU. A reading is categorised as uninteresting if it deviates very slightly from its immediately preceding reading and does not provide new insight on the patient's well being. In addition to this, readings that are faulty and emanate from possible sensor malfunctions are also eliminated. These eliminations are done at the site of the sensor using algorithms that are light enough to effectively function in the extremely resource-constrained environments of the sensor nodes. We notice, through experiments, that this eliminates and thus reduces around 90% of the readings that need to be transmitted to the LPU leading to significant energy savings. Furthermore, the proper functioning of these algorithms in such constrained environments is confirmed and validated over a hardware simulation set up. The second tier of assessment includes a proposed anomaly detection model at the LPU that is capable of identifying anomalies from streaming health parameter readings and indicates an adverse medical condition. In addition to being able to handle streaming data, the model works within the resource-constrained environments of an LPU and eliminates the need of transmitting the data to a back-end cloud, ensuring further energy savings. The anomaly detection capability of the model is validated using data available from the critical care units of hospitals and is shown to be superior to other anomaly detection techniques.
Cube Sampled K-Prototype Clustering for Featured Data
Aug 23, 2021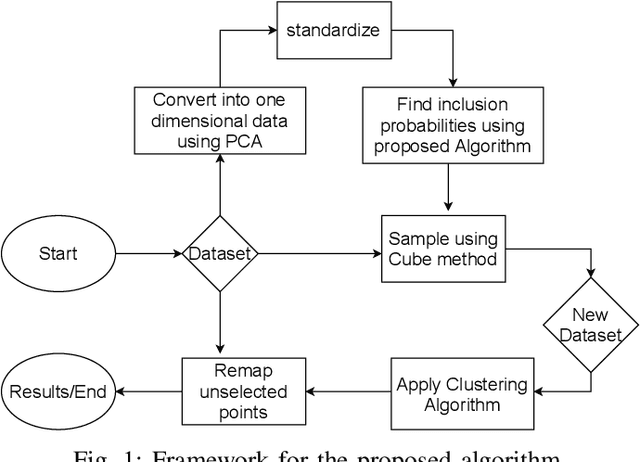
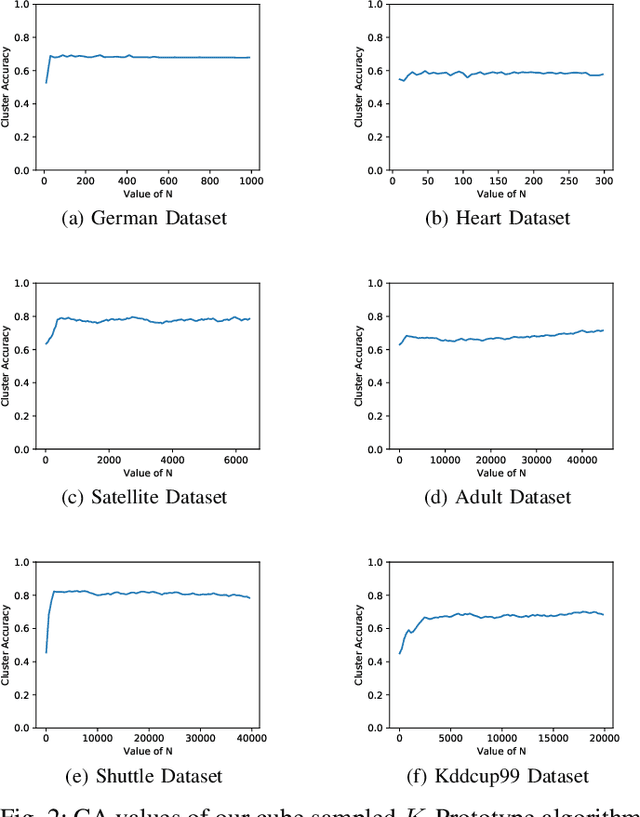
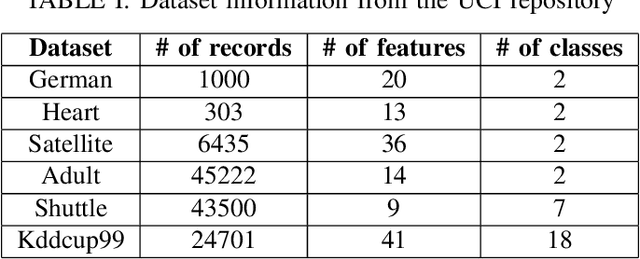
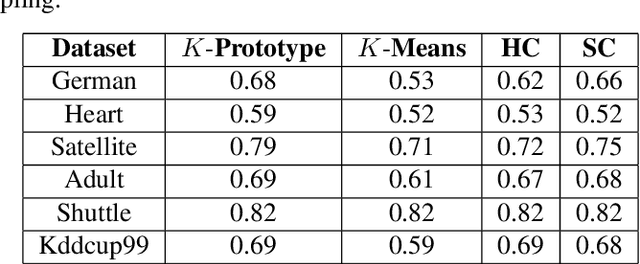
Clustering large amount of data is becoming increasingly important in the current times. Due to the large sizes of data, clustering algorithm often take too much time. Sampling this data before clustering is commonly used to reduce this time. In this work, we propose a probabilistic sampling technique called cube sampling along with K-Prototype clustering. Cube sampling is used because of its accurate sample selection. K-Prototype is most frequently used clustering algorithm when the data is numerical as well as categorical (very common in today's time). The novelty of this work is in obtaining the crucial inclusion probabilities for cube sampling using Principal Component Analysis (PCA). Experiments on multiple datasets from the UCI repository demonstrate that cube sampled K-Prototype algorithm gives the best clustering accuracy among similarly sampled other popular clustering algorithms (K-Means, Hierarchical Clustering (HC), Spectral Clustering (SC)). When compared with unsampled K-Prototype, K-Means, HC and SC, it still has the best accuracy with the added advantage of reduced computational complexity (due to reduced data size).