 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCube Sampled K-Prototype Clustering for Featured Data
Paper and Code
Aug 23, 2021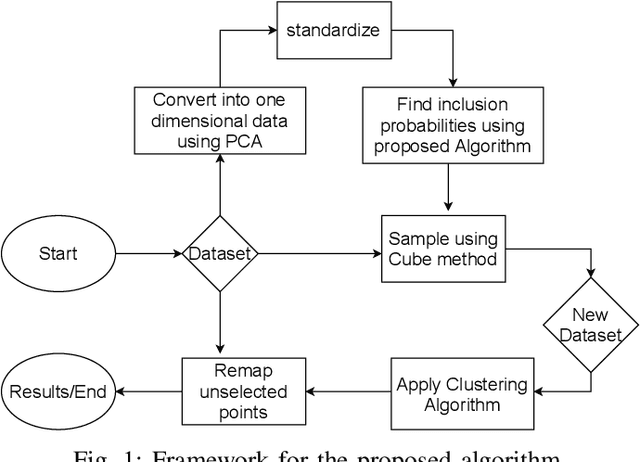
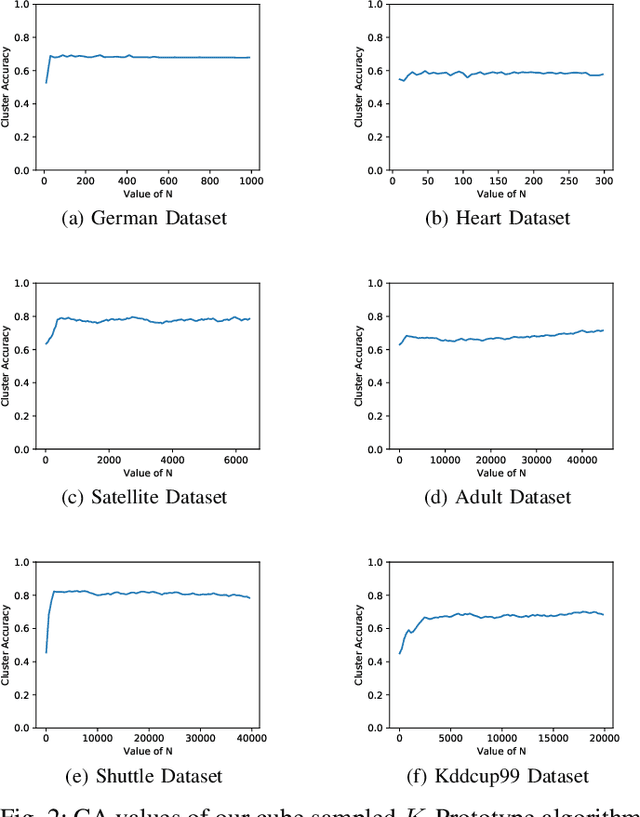
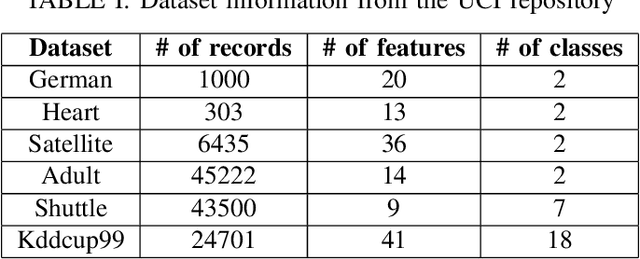
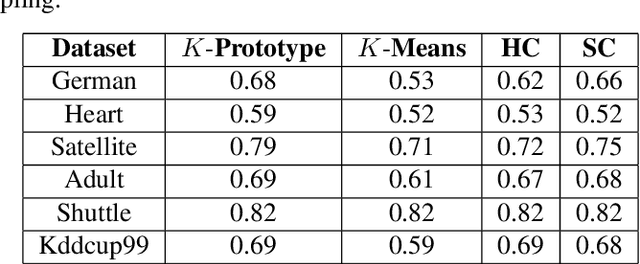
Clustering large amount of data is becoming increasingly important in the current times. Due to the large sizes of data, clustering algorithm often take too much time. Sampling this data before clustering is commonly used to reduce this time. In this work, we propose a probabilistic sampling technique called cube sampling along with K-Prototype clustering. Cube sampling is used because of its accurate sample selection. K-Prototype is most frequently used clustering algorithm when the data is numerical as well as categorical (very common in today's time). The novelty of this work is in obtaining the crucial inclusion probabilities for cube sampling using Principal Component Analysis (PCA). Experiments on multiple datasets from the UCI repository demonstrate that cube sampled K-Prototype algorithm gives the best clustering accuracy among similarly sampled other popular clustering algorithms (K-Means, Hierarchical Clustering (HC), Spectral Clustering (SC)). When compared with unsampled K-Prototype, K-Means, HC and SC, it still has the best accuracy with the added advantage of reduced computational complexity (due to reduced data size).