 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrania: Differentially Private Insights into AI Use
Jun 05, 2025We introduce $Urania$, a novel framework for generating insights about LLM chatbot interactions with rigorous differential privacy (DP) guarantees. The framework employs a private clustering mechanism and innovative keyword extraction methods, including frequency-based, TF-IDF-based, and LLM-guided approaches. By leveraging DP tools such as clustering, partition selection, and histogram-based summarization, $Urania$ provides end-to-end privacy protection. Our evaluation assesses lexical and semantic content preservation, pair similarity, and LLM-based metrics, benchmarking against a non-private Clio-inspired pipeline (Tamkin et al., 2024). Moreover, we develop a simple empirical privacy evaluation that demonstrates the enhanced robustness of our DP pipeline. The results show the framework's ability to extract meaningful conversational insights while maintaining stringent user privacy, effectively balancing data utility with privacy preservation.
Quantifying Cross-Modality Memorization in Vision-Language Models
Jun 05, 2025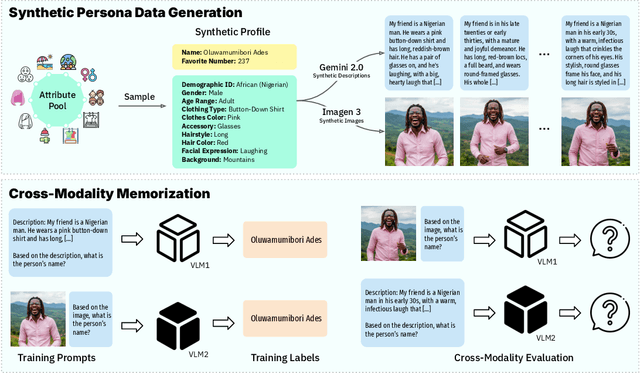
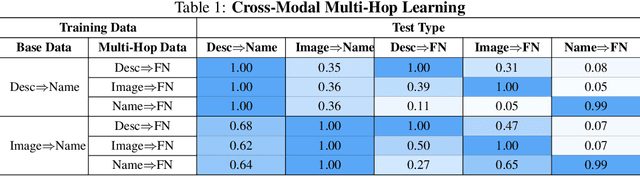
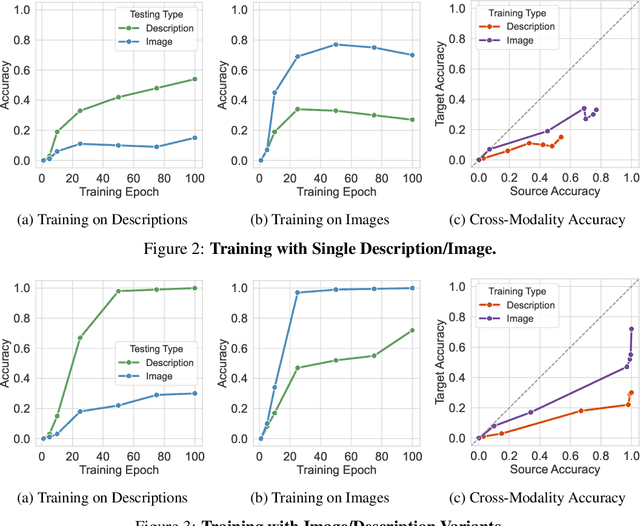
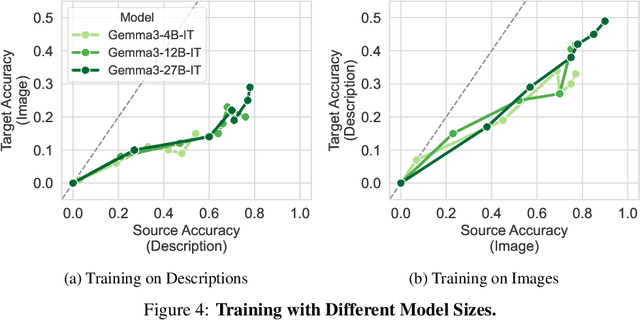
Understanding what and how neural networks memorize during training is crucial, both from the perspective of unintentional memorization of potentially sensitive information and from the standpoint of effective knowledge acquisition for real-world, knowledge-intensive tasks. While previous studies primarily investigate memorization within a single modality, such as text memorization in large language models or image memorization in diffusion models, unified multimodal models are becoming increasingly prevalent in practical applications. In this work, we focus on the unique characteristics of cross-modality memorization and conduct a systematic study centered on vision-language models. To facilitate controlled experiments, we first introduce a synthetic persona dataset comprising diverse synthetic person images and textual descriptions. We quantify factual knowledge memorization and cross-modal transferability by training models on a single modality and evaluating their performance in the other. Our results reveal that facts learned in one modality transfer to the other, but a significant gap exists between recalling information in the source and target modalities. Furthermore, we observe that this gap exists across various scenarios, including more capable models, machine unlearning, and the multi-hop case. At the end, we propose a baseline method to mitigate this challenge. We hope our study can inspire future research on developing more robust multimodal learning techniques to enhance cross-modal transferability.
Empirical Privacy Variance
Mar 16, 2025We propose the notion of empirical privacy variance and study it in the context of differentially private fine-tuning of language models. Specifically, we show that models calibrated to the same $(\varepsilon, \delta)$-DP guarantee using DP-SGD with different hyperparameter configurations can exhibit significant variations in empirical privacy, which we quantify through the lens of memorization. We investigate the generality of this phenomenon across multiple dimensions and discuss why it is surprising and relevant. Through regression analysis, we examine how individual and composite hyperparameters influence empirical privacy. The results reveal a no-free-lunch trade-off: existing practices of hyperparameter tuning in DP-SGD, which focus on optimizing utility under a fixed privacy budget, often come at the expense of empirical privacy. To address this, we propose refined heuristics for hyperparameter selection that explicitly account for empirical privacy, showing that they are both precise and practically useful. Finally, we take preliminary steps to understand empirical privacy variance. We propose two hypotheses, identify limitations in existing techniques like privacy auditing, and outline open questions for future research.
MATH-Perturb: Benchmarking LLMs' Math Reasoning Abilities against Hard Perturbations
Feb 10, 2025



Large language models have demonstrated impressive performance on challenging mathematical reasoning tasks, which has triggered the discussion of whether the performance is achieved by true reasoning capability or memorization. To investigate this question, prior work has constructed mathematical benchmarks when questions undergo simple perturbations -- modifications that still preserve the underlying reasoning patterns of the solutions. However, no work has explored hard perturbations, which fundamentally change the nature of the problem so that the original solution steps do not apply. To bridge the gap, we construct MATH-P-Simple and MATH-P-Hard via simple perturbation and hard perturbation, respectively. Each consists of 279 perturbed math problems derived from level-5 (hardest) problems in the MATH dataset (Hendrycksmath et. al., 2021). We observe significant performance drops on MATH-P-Hard across various models, including o1-mini (-16.49%) and gemini-2.0-flash-thinking (-12.9%). We also raise concerns about a novel form of memorization where models blindly apply learned problem-solving skills without assessing their applicability to modified contexts. This issue is amplified when using original problems for in-context learning. We call for research efforts to address this challenge, which is critical for developing more robust and reliable reasoning models.
Scaling Embedding Layers in Language Models
Feb 03, 2025We propose SCONE ($\textbf{S}$calable, $\textbf{C}$ontextualized, $\textbf{O}$ffloaded, $\textbf{N}$-gram $\textbf{E}$mbedding), a method for extending input embedding layers to enhance language model performance as layer size scales. To avoid increased decoding costs, SCONE retains the original vocabulary while introducing embeddings for a set of frequent $n$-grams. These embeddings provide contextualized representation for each input token and are learned with a separate model during training. During inference, they are precomputed and stored in off-accelerator memory with minimal impact on inference speed. SCONE enables two new scaling strategies: increasing the number of cached $n$-gram embeddings and scaling the model used to learn them, all while maintaining fixed inference-time FLOPS. We show that scaling both aspects allows SCONE to outperform a 1.9B parameter baseline across diverse corpora, while using only half the inference-time FLOPS.
Scaling Laws for Differentially Private Language Models
Jan 31, 2025Scaling laws have emerged as important components of large language model (LLM) training as they can predict performance gains through scale, and provide guidance on important hyper-parameter choices that would otherwise be expensive. LLMs also rely on large, high-quality training datasets, like those sourced from (sometimes sensitive) user data. Training models on this sensitive user data requires careful privacy protections like differential privacy (DP). However, the dynamics of DP training are significantly different, and consequently their scaling laws are not yet fully understood. In this work, we establish scaling laws that accurately model the intricacies of DP LLM training, providing a complete picture of the compute-privacy-utility tradeoffs and the optimal training configurations in many settings.
Exploring and Mitigating Adversarial Manipulation of Voting-Based Leaderboards
Jan 13, 2025



It is now common to evaluate Large Language Models (LLMs) by having humans manually vote to evaluate model outputs, in contrast to typical benchmarks that evaluate knowledge or skill at some particular task. Chatbot Arena, the most popular benchmark of this type, ranks models by asking users to select the better response between two randomly selected models (without revealing which model was responsible for the generations). These platforms are widely trusted as a fair and accurate measure of LLM capabilities. In this paper, we show that if bot protection and other defenses are not implemented, these voting-based benchmarks are potentially vulnerable to adversarial manipulation. Specifically, we show that an attacker can alter the leaderboard (to promote their favorite model or demote competitors) at the cost of roughly a thousand votes (verified in a simulated, offline version of Chatbot Arena). Our attack consists of two steps: first, we show how an attacker can determine which model was used to generate a given reply with more than $95\%$ accuracy; and then, the attacker can use this information to consistently vote for (or against) a target model. Working with the Chatbot Arena developers, we identify, propose, and implement mitigations to improve the robustness of Chatbot Arena against adversarial manipulation, which, based on our analysis, substantially increases the cost of such attacks. Some of these defenses were present before our collaboration, such as bot protection with Cloudflare, malicious user detection, and rate limiting. Others, including reCAPTCHA and login are being integrated to strengthen the security in Chatbot Arena.
Balls-and-Bins Sampling for DP-SGD
Dec 21, 2024We introduce the Balls-and-Bins sampling for differentially private (DP) optimization methods such as DP-SGD. While it has been common practice to use some form of shuffling in DP-SGD implementations, privacy accounting algorithms have typically assumed that Poisson subsampling is used instead. Recent work by Chua et al. (ICML 2024) however pointed out that shuffling based DP-SGD can have a much larger privacy cost in practical regimes of parameters. We show that the Balls-and-Bins sampling achieves the "best-of-both" samplers, namely, the implementation of Balls-and-Bins sampling is similar to that of Shuffling and models trained using DP-SGD with Balls-and-Bins sampling achieve utility comparable to those trained using DP-SGD with Shuffling at the same noise multiplier, and yet, Balls-and-Bins sampling enjoys similar-or-better privacy amplification as compared to Poisson subsampling in practical regimes.
Scalable DP-SGD: Shuffling vs. Poisson Subsampling
Nov 06, 2024



We provide new lower bounds on the privacy guarantee of the multi-epoch Adaptive Batch Linear Queries (ABLQ) mechanism with shuffled batch sampling, demonstrating substantial gaps when compared to Poisson subsampling; prior analysis was limited to a single epoch. Since the privacy analysis of Differentially Private Stochastic Gradient Descent (DP-SGD) is obtained by analyzing the ABLQ mechanism, this brings into serious question the common practice of implementing shuffling-based DP-SGD, but reporting privacy parameters as if Poisson subsampling was used. To understand the impact of this gap on the utility of trained machine learning models, we introduce a practical approach to implement Poisson subsampling at scale using massively parallel computation, and efficiently train models with the same. We compare the utility of models trained with Poisson-subsampling-based DP-SGD, and the optimistic estimates of utility when using shuffling, via our new lower bounds on the privacy guarantee of ABLQ with shuffling.
On Memorization of Large Language Models in Logical Reasoning
Oct 30, 2024



Large language models (LLMs) achieve good performance on challenging reasoning benchmarks, yet could also make basic reasoning mistakes. This contrasting behavior is puzzling when it comes to understanding the mechanisms behind LLMs' reasoning capabilities. One hypothesis is that the increasingly high and nearly saturated performance on common reasoning benchmarks could be due to the memorization of similar problems. In this paper, we systematically investigate this hypothesis with a quantitative measurement of memorization in reasoning tasks, using a dynamically generated logical reasoning benchmark based on Knights and Knaves (K&K) puzzles. We found that LLMs could interpolate the training puzzles (achieving near-perfect accuracy) after fine-tuning, yet fail when those puzzles are slightly perturbed, suggesting that the models heavily rely on memorization to solve those training puzzles. On the other hand, we show that while fine-tuning leads to heavy memorization, it also consistently improves generalization performance. In-depth analyses with perturbation tests, cross difficulty-level transferability, probing model internals, and fine-tuning with wrong answers suggest that the LLMs learn to reason on K&K puzzles despite training data memorization. This phenomenon indicates that LLMs exhibit a complex interplay between memorization and genuine reasoning abilities. Finally, our analysis with per-sample memorization score sheds light on how LLMs switch between reasoning and memorization in solving logical puzzles. Our code and data are available at https://memkklogic.github.io.