 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesize Privacy-Preserving High-Resolution Images via Private Textual Intermediaries
Jun 09, 2025



Generating high fidelity, differentially private (DP) synthetic images offers a promising route to share and analyze sensitive visual data without compromising individual privacy. However, existing DP image synthesis methods struggle to produce high resolution outputs that faithfully capture the structure of the original data. In this paper, we introduce a novel method, referred to as Synthesis via Private Textual Intermediaries (SPTI), that can generate high resolution DP images with easy adoption. The key idea is to shift the challenge of DP image synthesis from the image domain to the text domain by leveraging state of the art DP text generation methods. SPTI first summarizes each private image into a concise textual description using image to text models, then applies a modified Private Evolution algorithm to generate DP text, and finally reconstructs images using text to image models. Notably, SPTI requires no model training, only inference with off the shelf models. Given a private dataset, SPTI produces synthetic images of substantially higher quality than prior DP approaches. On the LSUN Bedroom dataset, SPTI attains an FID less than or equal to 26.71 under epsilon equal to 1.0, improving over Private Evolution FID of 40.36. Similarly, on MM CelebA HQ, SPTI achieves an FID less than or equal to 33.27 at epsilon equal to 1.0, compared to 57.01 from DP fine tuning baselines. Overall, our results demonstrate that Synthesis via Private Textual Intermediaries provides a resource efficient and proprietary model compatible framework for generating high resolution DP synthetic images, greatly expanding access to private visual datasets.
Urania: Differentially Private Insights into AI Use
Jun 05, 2025We introduce $Urania$, a novel framework for generating insights about LLM chatbot interactions with rigorous differential privacy (DP) guarantees. The framework employs a private clustering mechanism and innovative keyword extraction methods, including frequency-based, TF-IDF-based, and LLM-guided approaches. By leveraging DP tools such as clustering, partition selection, and histogram-based summarization, $Urania$ provides end-to-end privacy protection. Our evaluation assesses lexical and semantic content preservation, pair similarity, and LLM-based metrics, benchmarking against a non-private Clio-inspired pipeline (Tamkin et al., 2024). Moreover, we develop a simple empirical privacy evaluation that demonstrates the enhanced robustness of our DP pipeline. The results show the framework's ability to extract meaningful conversational insights while maintaining stringent user privacy, effectively balancing data utility with privacy preservation.
Scaling Embedding Layers in Language Models
Feb 03, 2025We propose SCONE ($\textbf{S}$calable, $\textbf{C}$ontextualized, $\textbf{O}$ffloaded, $\textbf{N}$-gram $\textbf{E}$mbedding), a method for extending input embedding layers to enhance language model performance as layer size scales. To avoid increased decoding costs, SCONE retains the original vocabulary while introducing embeddings for a set of frequent $n$-grams. These embeddings provide contextualized representation for each input token and are learned with a separate model during training. During inference, they are precomputed and stored in off-accelerator memory with minimal impact on inference speed. SCONE enables two new scaling strategies: increasing the number of cached $n$-gram embeddings and scaling the model used to learn them, all while maintaining fixed inference-time FLOPS. We show that scaling both aspects allows SCONE to outperform a 1.9B parameter baseline across diverse corpora, while using only half the inference-time FLOPS.
Scaling Laws for Differentially Private Language Models
Jan 31, 2025Scaling laws have emerged as important components of large language model (LLM) training as they can predict performance gains through scale, and provide guidance on important hyper-parameter choices that would otherwise be expensive. LLMs also rely on large, high-quality training datasets, like those sourced from (sometimes sensitive) user data. Training models on this sensitive user data requires careful privacy protections like differential privacy (DP). However, the dynamics of DP training are significantly different, and consequently their scaling laws are not yet fully understood. In this work, we establish scaling laws that accurately model the intricacies of DP LLM training, providing a complete picture of the compute-privacy-utility tradeoffs and the optimal training configurations in many settings.
On Memorization of Large Language Models in Logical Reasoning
Oct 30, 2024



Large language models (LLMs) achieve good performance on challenging reasoning benchmarks, yet could also make basic reasoning mistakes. This contrasting behavior is puzzling when it comes to understanding the mechanisms behind LLMs' reasoning capabilities. One hypothesis is that the increasingly high and nearly saturated performance on common reasoning benchmarks could be due to the memorization of similar problems. In this paper, we systematically investigate this hypothesis with a quantitative measurement of memorization in reasoning tasks, using a dynamically generated logical reasoning benchmark based on Knights and Knaves (K&K) puzzles. We found that LLMs could interpolate the training puzzles (achieving near-perfect accuracy) after fine-tuning, yet fail when those puzzles are slightly perturbed, suggesting that the models heavily rely on memorization to solve those training puzzles. On the other hand, we show that while fine-tuning leads to heavy memorization, it also consistently improves generalization performance. In-depth analyses with perturbation tests, cross difficulty-level transferability, probing model internals, and fine-tuning with wrong answers suggest that the LLMs learn to reason on K&K puzzles despite training data memorization. This phenomenon indicates that LLMs exhibit a complex interplay between memorization and genuine reasoning abilities. Finally, our analysis with per-sample memorization score sheds light on how LLMs switch between reasoning and memorization in solving logical puzzles. Our code and data are available at https://memkklogic.github.io.
Differentially Private Synthetic Data via Foundation Model APIs 2: Text
Mar 04, 2024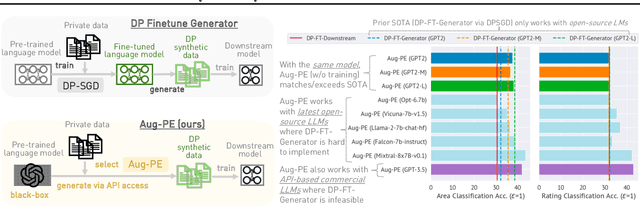
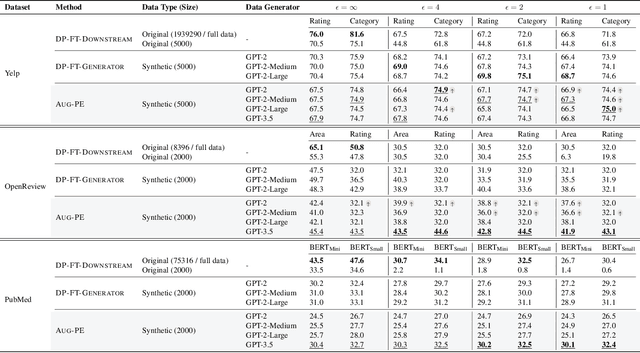
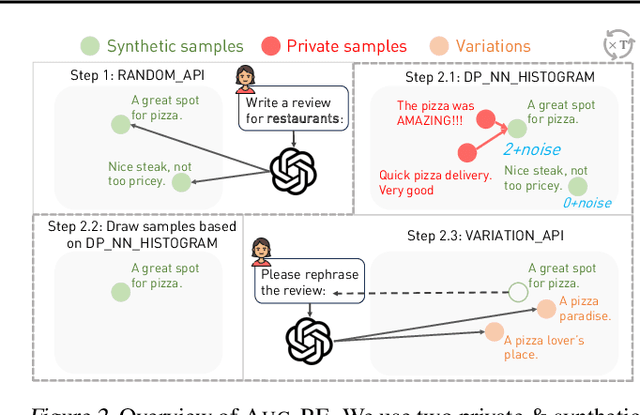
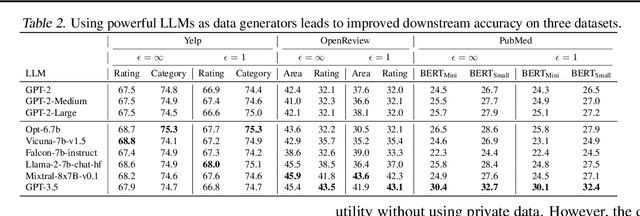
Text data has become extremely valuable due to the emergence of machine learning algorithms that learn from it. A lot of high-quality text data generated in the real world is private and therefore cannot be shared or used freely due to privacy concerns. Generating synthetic replicas of private text data with a formal privacy guarantee, i.e., differential privacy (DP), offers a promising and scalable solution. However, existing methods necessitate DP finetuning of large language models (LLMs) on private data to generate DP synthetic data. This approach is not viable for proprietary LLMs (e.g., GPT-3.5) and also demands considerable computational resources for open-source LLMs. Lin et al. (2024) recently introduced the Private Evolution (PE) algorithm to generate DP synthetic images with only API access to diffusion models. In this work, we propose an augmented PE algorithm, named Aug-PE, that applies to the complex setting of text. We use API access to an LLM and generate DP synthetic text without any model training. We conduct comprehensive experiments on three benchmark datasets. Our results demonstrate that Aug-PE produces DP synthetic text that yields competitive utility with the SOTA DP finetuning baselines. This underscores the feasibility of relying solely on API access of LLMs to produce high-quality DP synthetic texts, thereby facilitating more accessible routes to privacy-preserving LLM applications. Our code and data are available at https://github.com/AI-secure/aug-pe.
Privacy-Preserving Instructions for Aligning Large Language Models
Feb 21, 2024



Service providers of large language model (LLM) applications collect user instructions in the wild and use them in further aligning LLMs with users' intentions. These instructions, which potentially contain sensitive information, are annotated by human workers in the process. This poses a new privacy risk not addressed by the typical private optimization. To this end, we propose using synthetic instructions to replace real instructions in data annotation and model fine-tuning. Formal differential privacy is guaranteed by generating those synthetic instructions using privately fine-tuned generators. Crucial in achieving the desired utility is our novel filtering algorithm that matches the distribution of the synthetic instructions to that of the real ones. In both supervised fine-tuning and reinforcement learning from human feedback, our extensive experiments demonstrate the high utility of the final set of synthetic instructions by showing comparable results to real instructions. In supervised fine-tuning, models trained with private synthetic instructions outperform leading open-source models such as Vicuna.
Selective Pre-training for Private Fine-tuning
May 23, 2023



Suppose we want to train text prediction models in email clients or word processors. The models must preserve the privacy of user data and adhere to a specific fixed size to meet memory and inference time requirements. We introduce a generic framework to solve this problem. Specifically, we are given a public dataset $D_\text{pub}$ and a private dataset $D_\text{priv}$ corresponding to a downstream task $T$. How should we pre-train a fixed-size model $M$ on $D_\text{pub}$ and fine-tune it on $D_\text{priv}$ such that performance of $M$ with respect to $T$ is maximized and $M$ satisfies differential privacy with respect to $D_\text{priv}$? We show that pre-training on a {\em subset} of dataset $D_\text{pub}$ that brings the public distribution closer to the private distribution is a crucial ingredient to maximize the transfer learning abilities of $M$ after pre-training, especially in the regimes where model sizes are relatively small. Besides performance improvements, our framework also shows that with careful pre-training and private fine-tuning, {\em smaller models} can match the performance of much larger models, highlighting the promise of differentially private training as a tool for model compression and efficiency.
Exploring the Limits of Differentially Private Deep Learning with Group-wise Clipping
Dec 03, 2022Differentially private deep learning has recently witnessed advances in computational efficiency and privacy-utility trade-off. We explore whether further improvements along the two axes are possible and provide affirmative answers leveraging two instantiations of \emph{group-wise clipping}. To reduce the compute time overhead of private learning, we show that \emph{per-layer clipping}, where the gradient of each neural network layer is clipped separately, allows clipping to be performed in conjunction with backpropagation in differentially private optimization. This results in private learning that is as memory-efficient and almost as fast per training update as non-private learning for many workflows of interest. While per-layer clipping with constant thresholds tends to underperform standard flat clipping, per-layer clipping with adaptive thresholds matches or outperforms flat clipping under given training epoch constraints, hence attaining similar or better task performance within less wall time. To explore the limits of scaling (pretrained) models in differentially private deep learning, we privately fine-tune the 175 billion-parameter GPT-3. We bypass scaling challenges associated with clipping gradients that are distributed across multiple devices with \emph{per-device clipping} that clips the gradient of each model piece separately on its host device. Privately fine-tuning GPT-3 with per-device clipping achieves a task performance at $\epsilon=1$ better than what is attainable by non-privately fine-tuning the largest GPT-2 on a summarization task.
Adversarial Noises Are Linearly Separable for (Nearly) Random Neural Networks
Jun 09, 2022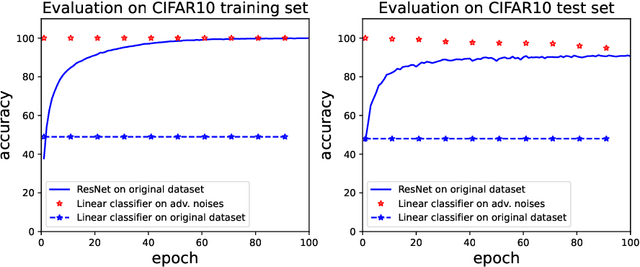

Adversarial examples, which are usually generated for specific inputs with a specific model, are ubiquitous for neural networks. In this paper we unveil a surprising property of adversarial noises when they are put together, i.e., adversarial noises crafted by one-step gradient methods are linearly separable if equipped with the corresponding labels. We theoretically prove this property for a two-layer network with randomly initialized entries and the neural tangent kernel setup where the parameters are not far from initialization. The proof idea is to show the label information can be efficiently backpropagated to the input while keeping the linear separability. Our theory and experimental evidence further show that the linear classifier trained with the adversarial noises of the training data can well classify the adversarial noises of the test data, indicating that adversarial noises actually inject a distributional perturbation to the original data distribution. Furthermore, we empirically demonstrate that the adversarial noises may become less linearly separable when the above conditions are compromised while they are still much easier to classify than original features.