 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPGL-Swarm: Integrated Multimodal Risk Stratification and Hereditary Syndrome Detection in Pheochromocytoma and Paraganglioma
Mar 23, 2026Pheochromocytomas and paragangliomas (PPGLs) are rare neuroendocrine tumors, of which 15-25% develop metastatic disease with 5-year survival rates reported as low as 34%. PPGL may indicate hereditary syndromes requiring stricter, syndrome-specific treatment and surveillance, but clinicians often fail to recognize these associations in routine care. Clinical practice uses GAPP score for PPGL grading, but several limitations remain for PPGL diagnosis: (1) GAPP scoring demands a high workload for clinician because it requires the manual evaluation of six independent components; (2) key components such as cellularity and Ki-67 are often evaluated with subjective criteria; (3) several clinically relevant metastatic risk factors are not captured by GAPP, such as SDHB mutations, which have been associated with reported metastatic rates of 35-75%. Agent-driven diagnostic systems appear promising, but most lack traceable reasoning for decision-making and do not incorporate domain-specific knowledge such as PPGL genotype information. To address these limitations, we present PPGL-Swarm, an agentic PPGL diagnostic system that generates a comprehensive report, including automated GAPP scoring (with quantified cellularity and Ki-67), genotype risk alerts, and multimodal report with integrated evidence. The system provides an auditable reasoning trail by decomposing diagnosis into micro-tasks, each assigned to a specialized agent. The gene and table agents use knowledge enhancement to better interpret genotype and laboratory findings, and during training we use reinforcement learning to refine tool selection and task assignment.
Automatic Funny Scene Extraction from Long-form Cinematic Videos
Feb 17, 2026Automatically extracting engaging and high-quality humorous scenes from cinematic titles is pivotal for creating captivating video previews and snackable content, boosting user engagement on streaming platforms. Long-form cinematic titles, with their extended duration and complex narratives, challenge scene localization, while humor's reliance on diverse modalities and its nuanced style add further complexity. This paper introduces an end-to-end system for automatically identifying and ranking humorous scenes from long-form cinematic titles, featuring shot detection, multimodal scene localization, and humor tagging optimized for cinematic content. Key innovations include a novel scene segmentation approach combining visual and textual cues, improved shot representations via guided triplet mining, and a multimodal humor tagging framework leveraging both audio and text. Our system achieves an 18.3% AP improvement over state-of-the-art scene detection on the OVSD dataset and an F1 score of 0.834 for detecting humor in long text. Extensive evaluations across five cinematic titles demonstrate 87% of clips extracted by our pipeline are intended to be funny, while 98% of scenes are accurately localized. With successful generalization to trailers, these results showcase the pipeline's potential to enhance content creation workflows, improve user engagement, and streamline snackable content generation for diverse cinematic media formats.
The Effect of Depth on the Expressivity of Deep Linear State-Space Models
Jun 24, 2025Deep state-space models (SSMs) have gained increasing popularity in sequence modelling. While there are numerous theoretical investigations of shallow SSMs, how the depth of the SSM affects its expressiveness remains a crucial problem. In this paper, we systematically investigate the role of depth and width in deep linear SSMs, aiming to characterize how they influence the expressive capacity of the architecture. First, we rigorously prove that in the absence of parameter constraints, increasing depth and increasing width are generally equivalent, provided that the parameter count remains within the same order of magnitude. However, under the assumption that the parameter norms are constrained, the effects of depth and width differ significantly. We show that a shallow linear SSM with large parameter norms can be represented by a deep linear SSM with smaller norms using a constructive method. In particular, this demonstrates that deep SSMs are more capable of representing targets with large norms than shallow SSMs under norm constraints. Finally, we derive upper bounds on the minimal depth required for a deep linear SSM to represent a given shallow linear SSM under constrained parameter norms. We also validate our theoretical results with numerical experiments
Numerical Investigation of Sequence Modeling Theory using Controllable Memory Functions
Jun 06, 2025The evolution of sequence modeling architectures, from recurrent neural networks and convolutional models to Transformers and structured state-space models, reflects ongoing efforts to address the diverse temporal dependencies inherent in sequential data. Despite this progress, systematically characterizing the strengths and limitations of these architectures remains a fundamental challenge.In this work, we propose a synthetic benchmarking framework to evaluate how effectively different sequence models capture distinct temporal structures. The core of this approach is to generate synthetic targets, each characterized by a memory function and a parameter that determines the strength of temporal dependence. This setup allows us to produce a continuum of tasks that vary in temporal complexity, enabling fine-grained analysis of model behavior concerning specific memory properties. We focus on four representative memory functions, each corresponding to a distinct class of temporal structures.Experiments on several sequence modeling architectures confirm existing theoretical insights and reveal new findings.These results demonstrate the effectiveness of the proposed method in advancing theoretical understandingand highlight the importance of using controllable targets with clearly defined structures for evaluating sequence modeling architectures.
Pathology Image Restoration via Mixture of Prompts
Mar 16, 2025In digital pathology, acquiring all-in-focus images is essential to high-quality imaging and high-efficient clinical workflow. Traditional scanners achieve this by scanning at multiple focal planes of varying depths and then merging them, which is relatively slow and often struggles with complex tissue defocus. Recent prevailing image restoration technique provides a means to restore high-quality pathology images from scans of single focal planes. However, existing image restoration methods are inadequate, due to intricate defocus patterns in pathology images and their domain-specific semantic complexities. In this work, we devise a two-stage restoration solution cascading a transformer and a diffusion model, to benefit from their powers in preserving image fidelity and perceptual quality, respectively. We particularly propose a novel mixture of prompts for the two-stage solution. Given initial prompt that models defocus in microscopic imaging, we design two prompts that describe the high-level image semantics from pathology foundation model and the fine-grained tissue structures via edge extraction. We demonstrate that, by feeding the prompt mixture to our method, we can restore high-quality pathology images from single-focal-plane scans, implying high potentials of the mixture of prompts to clinical usage. Code will be publicly available at https://github.com/caijd2000/MoP.
LSA: Latent Style Augmentation Towards Stain-Agnostic Cervical Cancer Screening
Mar 09, 2025The deployment of computer-aided diagnosis systems for cervical cancer screening using whole slide images (WSIs) faces critical challenges due to domain shifts caused by staining variations across different scanners and imaging environments. While existing stain augmentation methods improve patch-level robustness, they fail to scale to WSIs due to two key limitations: (1) inconsistent stain patterns when extending patch operations to gigapixel slides, and (2) prohibitive computational/storage costs from offline processing of augmented WSIs.To address this, we propose Latent Style Augmentation (LSA), a framework that performs efficient, online stain augmentation directly on WSI-level latent features. We first introduce WSAug, a WSI-level stain augmentation method ensuring consistent stain across patches within a WSI. Using offline-augmented WSIs by WSAug, we design and train Stain Transformer, which can simulate targeted style in the latent space, efficiently enhancing the robustness of the WSI-level classifier. We validate our method on a multi-scanner WSI dataset for cervical cancer diagnosis. Despite being trained on data from a single scanner, our approach achieves significant performance improvements on out-of-distribution data from other scanners. Code will be available at https://github.com/caijd2000/LSA.
MITracker: Multi-View Integration for Visual Object Tracking
Feb 27, 2025Multi-view object tracking (MVOT) offers promising solutions to challenges such as occlusion and target loss, which are common in traditional single-view tracking. However, progress has been limited by the lack of comprehensive multi-view datasets and effective cross-view integration methods. To overcome these limitations, we compiled a Multi-View object Tracking (MVTrack) dataset of 234K high-quality annotated frames featuring 27 distinct objects across various scenes. In conjunction with this dataset, we introduce a novel MVOT method, Multi-View Integration Tracker (MITracker), to efficiently integrate multi-view object features and provide stable tracking outcomes. MITracker can track any object in video frames of arbitrary length from arbitrary viewpoints. The key advancements of our method over traditional single-view approaches come from two aspects: (1) MITracker transforms 2D image features into a 3D feature volume and compresses it into a bird's eye view (BEV) plane, facilitating inter-view information fusion; (2) we propose an attention mechanism that leverages geometric information from fused 3D feature volume to refine the tracking results at each view. MITracker outperforms existing methods on the MVTrack and GMTD datasets, achieving state-of-the-art performance. The code and the new dataset will be available at https://mii-laboratory.github.io/MITracker/.
Differentially Private Synthetic Data via Foundation Model APIs 2: Text
Mar 04, 2024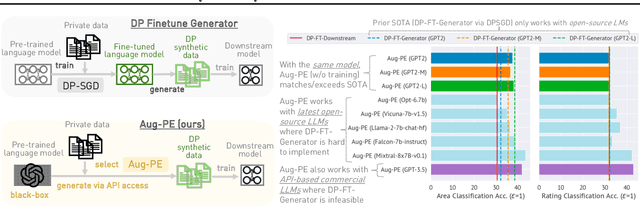
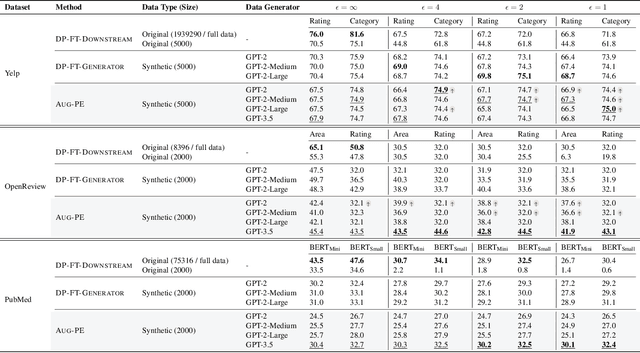
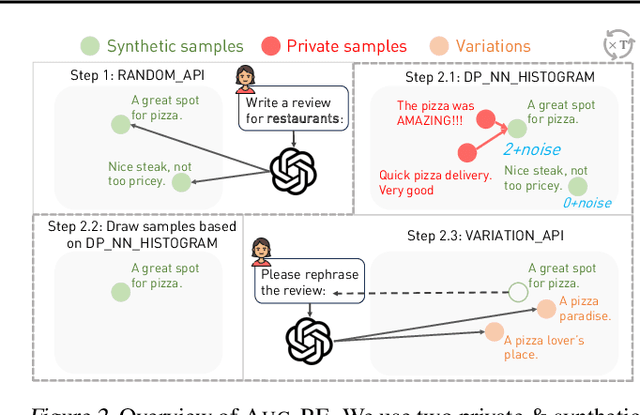
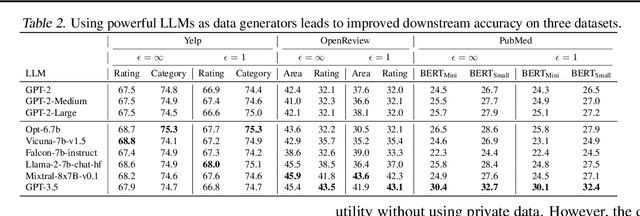
Text data has become extremely valuable due to the emergence of machine learning algorithms that learn from it. A lot of high-quality text data generated in the real world is private and therefore cannot be shared or used freely due to privacy concerns. Generating synthetic replicas of private text data with a formal privacy guarantee, i.e., differential privacy (DP), offers a promising and scalable solution. However, existing methods necessitate DP finetuning of large language models (LLMs) on private data to generate DP synthetic data. This approach is not viable for proprietary LLMs (e.g., GPT-3.5) and also demands considerable computational resources for open-source LLMs. Lin et al. (2024) recently introduced the Private Evolution (PE) algorithm to generate DP synthetic images with only API access to diffusion models. In this work, we propose an augmented PE algorithm, named Aug-PE, that applies to the complex setting of text. We use API access to an LLM and generate DP synthetic text without any model training. We conduct comprehensive experiments on three benchmark datasets. Our results demonstrate that Aug-PE produces DP synthetic text that yields competitive utility with the SOTA DP finetuning baselines. This underscores the feasibility of relying solely on API access of LLMs to produce high-quality DP synthetic texts, thereby facilitating more accessible routes to privacy-preserving LLM applications. Our code and data are available at https://github.com/AI-secure/aug-pe.
Approximation theory of transformer networks for sequence modeling
May 29, 2023The transformer is a widely applied architecture in sequence modeling applications, but the theoretical understanding of its working principles is limited. In this work, we investigate the ability of transformers to approximate sequential relationships. We first prove a universal approximation theorem for the transformer hypothesis space. From its derivation, we identify a novel notion of regularity under which we can prove an explicit approximation rate estimate. This estimate reveals key structural properties of the transformer and suggests the types of sequence relationships that the transformer is adapted to approximating. In particular, it allows us to concretely discuss the structural bias between the transformer and classical sequence modeling methods, such as recurrent neural networks. Our findings are supported by numerical experiments.
Forward and Inverse Approximation Theory for Linear Temporal Convolutional Networks
May 29, 2023We present a theoretical analysis of the approximation properties of convolutional architectures when applied to the modeling of temporal sequences. Specifically, we prove an approximation rate estimate (Jackson-type result) and an inverse approximation theorem (Bernstein-type result), which together provide a comprehensive characterization of the types of sequential relationships that can be efficiently captured by a temporal convolutional architecture. The rate estimate improves upon a previous result via the introduction of a refined complexity measure, whereas the inverse approximation theorem is new.