 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Token Compression for Efficient Video Understanding through Reinforcement Learning
Mar 27, 2026Multimodal Large Language Models have demonstrated remarkable capabilities in video understanding, yet face prohibitive computational costs and performance degradation from ''context rot'' due to massive visual token redundancy. Existing compression strategies typically rely on heuristics or fixed transformations that are often decoupled from the downstream task objectives, limiting their adaptability and effectiveness. To address this, we propose SCORE (Surprise-augmented token COmpression via REinforcement learning), a unified framework that learns an adaptive token compression policy. SCORE introduces a lightweight policy network conditioned on a surprise-augmented state representation that incorporates inter-frame residuals to explicitly capture temporal dynamics and motion saliency. We optimize this policy using a group-wise reinforcement learning scheme with a split-advantage estimator, stabilized by a two-stage curriculum transferring from static pseudo-videos to real dynamic videos. Extensive experiments on diverse video understanding benchmarks demonstrate that SCORE significantly outperforms state-of-the-art baselines. Notably, SCORE achieves a 16x prefill speedup while preserving 99.5% of original performance at a 10% retention ratio, offering a scalable solution for efficient long-form video understanding.
DiG: Differential Grounding for Enhancing Fine-Grained Perception in Multimodal Large Language Model
Dec 14, 2025Multimodal Large Language Models have achieved impressive performance on a variety of vision-language tasks, yet their fine-grained visual perception and precise spatial reasoning remain limited. In this work, we introduce DiG (Differential Grounding), a novel proxy task framework where MLLMs learn fine-grained perception by identifying and localizing all differences between similar image pairs without prior knowledge of their number. To support scalable training, we develop an automated 3D rendering-based data generation pipeline that produces high-quality paired images with fully controllable discrepancies. To address the sparsity of difference signals, we further employ curriculum learning that progressively increases complexity from single to multiple differences, enabling stable optimization. Extensive experiments demonstrate that DiG significantly improves model performance across a variety of visual perception benchmarks and that the learned fine-grained perception skills transfer effectively to standard downstream tasks, including RefCOCO, RefCOCO+, RefCOCOg, and general multimodal perception benchmarks. Our results highlight differential grounding as a scalable and robust approach for advancing fine-grained visual reasoning in MLLMs.
Numerical Investigation of Sequence Modeling Theory using Controllable Memory Functions
Jun 06, 2025The evolution of sequence modeling architectures, from recurrent neural networks and convolutional models to Transformers and structured state-space models, reflects ongoing efforts to address the diverse temporal dependencies inherent in sequential data. Despite this progress, systematically characterizing the strengths and limitations of these architectures remains a fundamental challenge.In this work, we propose a synthetic benchmarking framework to evaluate how effectively different sequence models capture distinct temporal structures. The core of this approach is to generate synthetic targets, each characterized by a memory function and a parameter that determines the strength of temporal dependence. This setup allows us to produce a continuum of tasks that vary in temporal complexity, enabling fine-grained analysis of model behavior concerning specific memory properties. We focus on four representative memory functions, each corresponding to a distinct class of temporal structures.Experiments on several sequence modeling architectures confirm existing theoretical insights and reveal new findings.These results demonstrate the effectiveness of the proposed method in advancing theoretical understandingand highlight the importance of using controllable targets with clearly defined structures for evaluating sequence modeling architectures.
LongSSM: On the Length Extension of State-space Models in Language Modelling
Jun 04, 2024In this paper, we investigate the length-extension of state-space models (SSMs) in language modeling. Length extension involves training models on short sequences and testing them on longer ones. We show that state-space models trained with zero hidden states initialization have difficulty doing length extension. We explain this difficulty by pointing out the length extension is equivalent to polynomial extrapolation. Based on the theory, we propose a simple yet effective method - changing the hidden states initialization scheme - to improve the length extension. Moreover, our method shows that using long training sequence length is beneficial but not necessary to length extension. Changing the hidden state initialization enables the efficient training of long-memory model with a smaller training context length.
Integrating Deep Learning and Synthetic Biology: A Co-Design Approach for Enhancing Gene Expression via N-terminal Coding Sequences
Feb 20, 2024N-terminal coding sequence (NCS) influences gene expression by impacting the translation initiation rate. The NCS optimization problem is to find an NCS that maximizes gene expression. The problem is important in genetic engineering. However, current methods for NCS optimization such as rational design and statistics-guided approaches are labor-intensive yield only relatively small improvements. This paper introduces a deep learning/synthetic biology co-designed few-shot training workflow for NCS optimization. Our method utilizes k-nearest encoding followed by word2vec to encode the NCS, then performs feature extraction using attention mechanisms, before constructing a time-series network for predicting gene expression intensity, and finally a direct search algorithm identifies the optimal NCS with limited training data. We took green fluorescent protein (GFP) expressed by Bacillus subtilis as a reporting protein of NCSs, and employed the fluorescence enhancement factor as the metric of NCS optimization. Within just six iterative experiments, our model generated an NCS (MLD62) that increased average GFP expression by 5.41-fold, outperforming the state-of-the-art NCS designs. Extending our findings beyond GFP, we showed that our engineered NCS (MLD62) can effectively boost the production of N-acetylneuraminic acid by enhancing the expression of the crucial rate-limiting GNA1 gene, demonstrating its practical utility. We have open-sourced our NCS expression database and experimental procedures for public use.
StableSSM: Alleviating the Curse of Memory in State-space Models through Stable Reparameterization
Nov 24, 2023

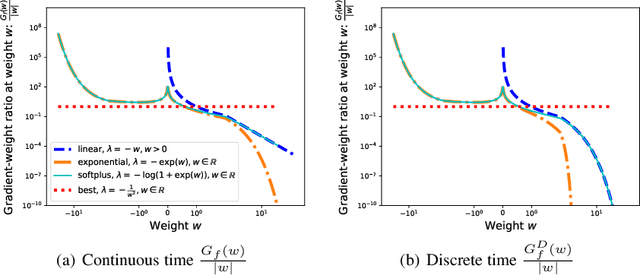

In this paper, we investigate the long-term memory learning capabilities of state-space models (SSMs) from the perspective of parameterization. We prove that state-space models without any reparameterization exhibit a memory limitation similar to that of traditional RNNs: the target relationships that can be stably approximated by state-space models must have an exponential decaying memory. Our analysis identifies this "curse of memory" as a result of the recurrent weights converging to a stability boundary, suggesting that a reparameterization technique can be effective. To this end, we introduce a class of reparameterization techniques for SSMs that effectively lift its memory limitations. Besides improving approximation capabilities, we further illustrate that a principled choice of reparameterization scheme can also enhance optimization stability. We validate our findings using synthetic datasets and language models.
State-space Models with Layer-wise Nonlinearity are Universal Approximators with Exponential Decaying Memory
Oct 01, 2023State-space models have gained popularity in sequence modelling due to their simple and efficient network structures. However, the absence of nonlinear activation along the temporal direction limits the model's capacity. In this paper, we prove that stacking state-space models with layer-wise nonlinear activation is sufficient to approximate any continuous sequence-to-sequence relationship. Our findings demonstrate that the addition of layer-wise nonlinear activation enhances the model's capacity to learn complex sequence patterns. Meanwhile, it can be seen both theoretically and empirically that the state-space models do not fundamentally resolve the exponential decaying memory issue. Theoretical results are justified by numerical verifications.
HyperSNN: A new efficient and robust deep learning model for resource constrained control applications
Aug 17, 2023



In light of the increasing adoption of edge computing in areas such as intelligent furniture, robotics, and smart homes, this paper introduces HyperSNN, an innovative method for control tasks that uses spiking neural networks (SNNs) in combination with hyperdimensional computing. HyperSNN substitutes expensive 32-bit floating point multiplications with 8-bit integer additions, resulting in reduced energy consumption while enhancing robustness and potentially improving accuracy. Our model was tested on AI Gym benchmarks, including Cartpole, Acrobot, MountainCar, and Lunar Lander. HyperSNN achieves control accuracies that are on par with conventional machine learning methods but with only 1.36% to 9.96% of the energy expenditure. Furthermore, our experiments showed increased robustness when using HyperSNN. We believe that HyperSNN is especially suitable for interactive, mobile, and wearable devices, promoting energy-efficient and robust system design. Furthermore, it paves the way for the practical implementation of complex algorithms like model predictive control (MPC) in real-world industrial scenarios.
Improve Long-term Memory Learning Through Rescaling the Error Temporally
Jul 21, 2023This paper studies the error metric selection for long-term memory learning in sequence modelling. We examine the bias towards short-term memory in commonly used errors, including mean absolute/squared error. Our findings show that all temporally positive-weighted errors are biased towards short-term memory in learning linear functionals. To reduce this bias and improve long-term memory learning, we propose the use of a temporally rescaled error. In addition to reducing the bias towards short-term memory, this approach can also alleviate the vanishing gradient issue. We conduct numerical experiments on different long-memory tasks and sequence models to validate our claims. Numerical results confirm the importance of appropriate temporally rescaled error for effective long-term memory learning. To the best of our knowledge, this is the first work that quantitatively analyzes different errors' memory bias towards short-term memory in sequence modelling.
Inverse Approximation Theory for Nonlinear Recurrent Neural Networks
May 30, 2023



We prove an inverse approximation theorem for the approximation of nonlinear sequence-to-sequence relationships using RNNs. This is a so-called Bernstein-type result in approximation theory, which deduces properties of a target function under the assumption that it can be effectively approximated by a hypothesis space. In particular, we show that nonlinear sequence relationships, viewed as functional sequences, that can be stably approximated by RNNs with hardtanh/tanh activations must have an exponential decaying memory structure -- a notion that can be made precise. This extends the previously identified curse of memory in linear RNNs into the general nonlinear setting, and quantifies the essential limitations of the RNN architecture for learning sequential relationships with long-term memory. Based on the analysis, we propose a principled reparameterization method to overcome the limitations. Our theoretical results are confirmed by numerical experiments.