 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatterhorn: Efficient Analog Sparse Spiking Transformer Architecture with Masked Time-To-First-Spike Encoding
Jan 30, 2026Spiking neural networks (SNNs) have emerged as a promising candidate for energy-efficient LLM inference. However, current energy evaluations for SNNs primarily focus on counting accumulate operations, and fail to account for real-world hardware costs such as data movement, which can consume nearly 80% of the total energy. In this paper, we propose Matterhorn, a spiking transformer that integrates a novel masked time-to-first-spike (M-TTFS) encoding method to reduce spike movement and a memristive synapse unit (MSU) to eliminate weight access overhead. M-TTFS employs a masking strategy that reassigns the zero-energy silent state (a spike train of all 0s) to the most frequent membrane potential rather than the lowest. This aligns the coding scheme with the data distribution, minimizing spike movement energy without information loss. We further propose a `dead zone' strategy that maximizes sparsity by mapping all values within a given range to the silent state. At the hardware level, the MSU utilizes compute-in-memory (CIM) technology to perform analog integration directly within memory, effectively removing weight access costs. On the GLUE benchmark, Matterhorn establishes a new state-of-the-art, surpassing existing SNNs by 1.42% in average accuracy while delivering a 2.31 times improvement in energy efficiency.
SpikySpace: A Spiking State Space Model for Energy-Efficient Time Series Forecasting
Jan 02, 2026Time-series forecasting often operates under tight power and latency budgets in fields like traffic management, industrial condition monitoring, and on-device sensing. These applications frequently require near real-time responses and low energy consumption on edge devices. Spiking neural networks (SNNs) offer event-driven computation and ultra-low power by exploiting temporal sparsity and multiplication-free computation. Yet existing SNN-based time-series forecasters often inherit complex transformer blocks, thereby losing much of the efficiency benefit. To solve the problem, we propose SpikySpace, a spiking state-space model (SSM) that reduces the quadratic cost in the attention block to linear time via selective scanning. Further, we replace dense SSM updates with sparse spike trains and execute selective scans only on spike events, thereby avoiding dense multiplications while preserving the SSM's structured memory. Because complex operations such as exponentials and divisions are costly on neuromorphic chips, we introduce simplified approximations of SiLU and Softplus to enable a neuromorphic-friendly model architecture. In matched settings, SpikySpace reduces estimated energy consumption by 98.73% and 96.24% compared to two state-of-the-art transformer based approaches, namely iTransformer and iSpikformer, respectively. In standard time series forecasting datasets, SpikySpace delivers competitive accuracy while substantially reducing energy cost and memory traffic. As the first full spiking state-space model, SpikySpace bridges neuromorphic efficiency with modern sequence modeling, marking a practical and scalable path toward efficient time series forecasting systems.
Collaborative Editable Model
Jun 17, 2025Vertical-domain large language models (LLMs) play a crucial role in specialized scenarios such as finance, healthcare, and law; however, their training often relies on large-scale annotated data and substantial computational resources, impeding rapid development and continuous iteration. To address these challenges, we introduce the Collaborative Editable Model (CoEM), which constructs a candidate knowledge pool from user-contributed domain snippets, leverages interactive user-model dialogues combined with user ratings and attribution analysis to pinpoint high-value knowledge fragments, and injects these fragments via in-context prompts for lightweight domain adaptation. With high-value knowledge, the LLM can generate more accurate and domain-specific content. In a financial information scenario, we collect 15k feedback from about 120 users and validate CoEM with user ratings to assess the quality of generated insights, demonstrating significant improvements in domain-specific generation while avoiding the time and compute overhead of traditional fine-tuning workflows.
Integrating Deep Learning and Synthetic Biology: A Co-Design Approach for Enhancing Gene Expression via N-terminal Coding Sequences
Feb 20, 2024N-terminal coding sequence (NCS) influences gene expression by impacting the translation initiation rate. The NCS optimization problem is to find an NCS that maximizes gene expression. The problem is important in genetic engineering. However, current methods for NCS optimization such as rational design and statistics-guided approaches are labor-intensive yield only relatively small improvements. This paper introduces a deep learning/synthetic biology co-designed few-shot training workflow for NCS optimization. Our method utilizes k-nearest encoding followed by word2vec to encode the NCS, then performs feature extraction using attention mechanisms, before constructing a time-series network for predicting gene expression intensity, and finally a direct search algorithm identifies the optimal NCS with limited training data. We took green fluorescent protein (GFP) expressed by Bacillus subtilis as a reporting protein of NCSs, and employed the fluorescence enhancement factor as the metric of NCS optimization. Within just six iterative experiments, our model generated an NCS (MLD62) that increased average GFP expression by 5.41-fold, outperforming the state-of-the-art NCS designs. Extending our findings beyond GFP, we showed that our engineered NCS (MLD62) can effectively boost the production of N-acetylneuraminic acid by enhancing the expression of the crucial rate-limiting GNA1 gene, demonstrating its practical utility. We have open-sourced our NCS expression database and experimental procedures for public use.
HyperSNN: A new efficient and robust deep learning model for resource constrained control applications
Aug 17, 2023



In light of the increasing adoption of edge computing in areas such as intelligent furniture, robotics, and smart homes, this paper introduces HyperSNN, an innovative method for control tasks that uses spiking neural networks (SNNs) in combination with hyperdimensional computing. HyperSNN substitutes expensive 32-bit floating point multiplications with 8-bit integer additions, resulting in reduced energy consumption while enhancing robustness and potentially improving accuracy. Our model was tested on AI Gym benchmarks, including Cartpole, Acrobot, MountainCar, and Lunar Lander. HyperSNN achieves control accuracies that are on par with conventional machine learning methods but with only 1.36% to 9.96% of the energy expenditure. Furthermore, our experiments showed increased robustness when using HyperSNN. We believe that HyperSNN is especially suitable for interactive, mobile, and wearable devices, promoting energy-efficient and robust system design. Furthermore, it paves the way for the practical implementation of complex algorithms like model predictive control (MPC) in real-world industrial scenarios.
Efficient Hyperdimensional Computing
Jan 26, 2023Hyperdimensional computing (HDC) uses binary vectors of high dimensions to perform classification. Due to its simplicity and massive parallelism, HDC can be highly energy-efficient and well-suited for resource-constrained platforms. However, in trading off orthogonality with efficiency, hypervectors may use tens of thousands of dimensions. In this paper, we will examine the necessity for such high dimensions. In particular, we give a detailed theoretical analysis of the relationship among dimensions of hypervectors, accuracy, and orthogonality. The main conclusion of this study is that a much lower dimension, typically less than 100, can also achieve similar or even higher detecting accuracy compared with other state-of-the-art HDC models. Based on this insight, we propose a suite of novel techniques to build HDC models that use binary hypervectors of dimensions that are orders of magnitude smaller than those found in the state-of-the-art HDC models, yet yield equivalent or even improved accuracy and efficiency. For image classification, we achieved an HDC accuracy of 96.88\% with a dimension of only 32 on the MNIST dataset. We further explore our methods on more complex datasets like CIFAR-10 and show the limits of HDC computing.
BertNet: Harvesting Knowledge Graphs from Pretrained Language Models
Jun 28, 2022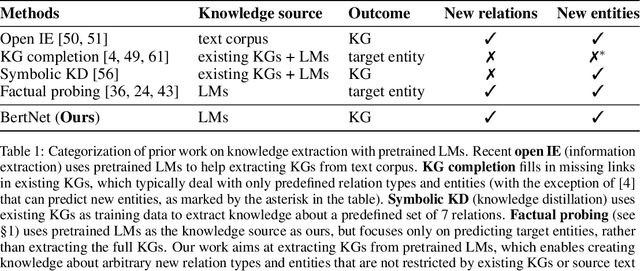
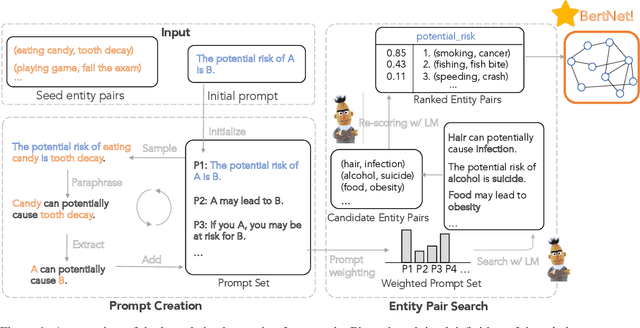
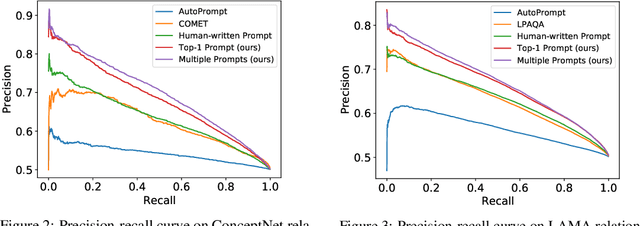

Symbolic knowledge graphs (KGs) have been constructed either by expensive human crowdsourcing or with domain-specific complex information extraction pipelines. The emerging large pretrained language models (LMs), such as Bert, have shown to implicitly encode massive knowledge which can be queried with properly designed prompts. However, compared to the explicit KGs, the implict knowledge in the black-box LMs is often difficult to access or edit and lacks explainability. In this work, we aim at harvesting symbolic KGs from the LMs, a new framework for automatic KG construction empowered by the neural LMs' flexibility and scalability. Compared to prior works that often rely on large human annotated data or existing massive KGs, our approach requires only the minimal definition of relations as inputs, and hence is suitable for extracting knowledge of rich new relations not available before.The approach automatically generates diverse prompts, and performs efficient knowledge search within a given LM for consistent and extensive outputs. The harvested knowledge with our approach is substantially more accurate than with previous methods, as shown in both automatic and human evaluation. As a result, we derive from diverse LMs a family of new KGs (e.g., BertNet and RoBERTaNet) that contain a richer set of commonsense relations, including complex ones (e.g., "A is capable of but not good at B"), than the human-annotated KGs (e.g., ConceptNet). Besides, the resulting KGs also serve as a vehicle to interpret the respective source LMs, leading to new insights into the varying knowledge capability of different LMs.