 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Inference-optimal Mixture-of-Expert Large Language Models
Apr 03, 2024



Mixture-of-Expert (MoE) based large language models (LLMs), such as the recent Mixtral and DeepSeek-MoE, have shown great promise in scaling model size without suffering from the quadratic growth of training cost of dense transformers. Like dense models, training MoEs requires answering the same question: given a training budget, what is the optimal allocation on the model size and number of tokens? We study the scaling law of MoE-based LLMs regarding the relations between the model performance, model size, dataset size, and the expert degree. Echoing previous research studying MoE in different contexts, we observe the diminishing return of increasing the number of experts, but this seems to suggest we should scale the number of experts until saturation, as the training cost would remain constant, which is problematic during inference time. We propose to amend the scaling law of MoE by introducing inference efficiency as another metric besides the validation loss. We find that MoEs with a few (4/8) experts are the most serving efficient solution under the same performance, but costs 2.5-3.5x more in training. On the other hand, training a (16/32) expert MoE much smaller (70-85%) than the loss-optimal solution, but with a larger training dataset is a promising setup under a training budget.
BertNet: Harvesting Knowledge Graphs from Pretrained Language Models
Jun 28, 2022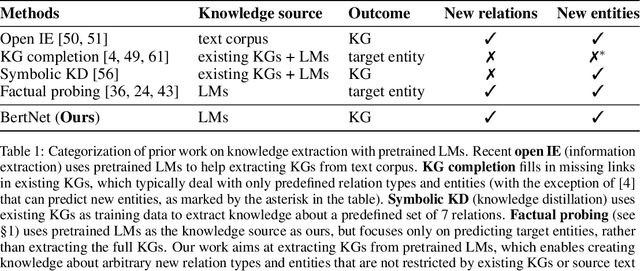
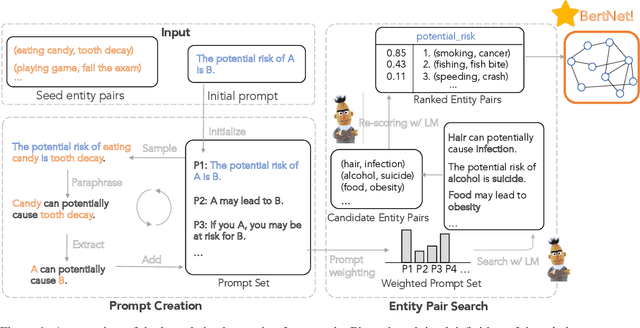
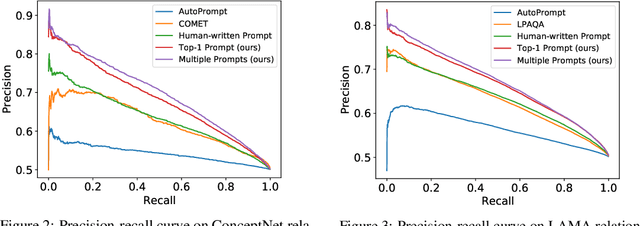

Symbolic knowledge graphs (KGs) have been constructed either by expensive human crowdsourcing or with domain-specific complex information extraction pipelines. The emerging large pretrained language models (LMs), such as Bert, have shown to implicitly encode massive knowledge which can be queried with properly designed prompts. However, compared to the explicit KGs, the implict knowledge in the black-box LMs is often difficult to access or edit and lacks explainability. In this work, we aim at harvesting symbolic KGs from the LMs, a new framework for automatic KG construction empowered by the neural LMs' flexibility and scalability. Compared to prior works that often rely on large human annotated data or existing massive KGs, our approach requires only the minimal definition of relations as inputs, and hence is suitable for extracting knowledge of rich new relations not available before.The approach automatically generates diverse prompts, and performs efficient knowledge search within a given LM for consistent and extensive outputs. The harvested knowledge with our approach is substantially more accurate than with previous methods, as shown in both automatic and human evaluation. As a result, we derive from diverse LMs a family of new KGs (e.g., BertNet and RoBERTaNet) that contain a richer set of commonsense relations, including complex ones (e.g., "A is capable of but not good at B"), than the human-annotated KGs (e.g., ConceptNet). Besides, the resulting KGs also serve as a vehicle to interpret the respective source LMs, leading to new insights into the varying knowledge capability of different LMs.
Multi-modal Self-supervised Pre-training for Regulatory Genome Across Cell Types
Nov 03, 2021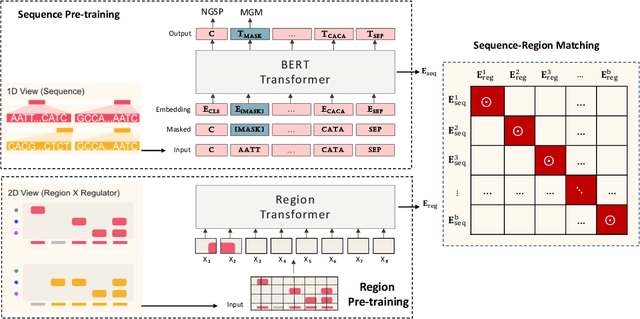

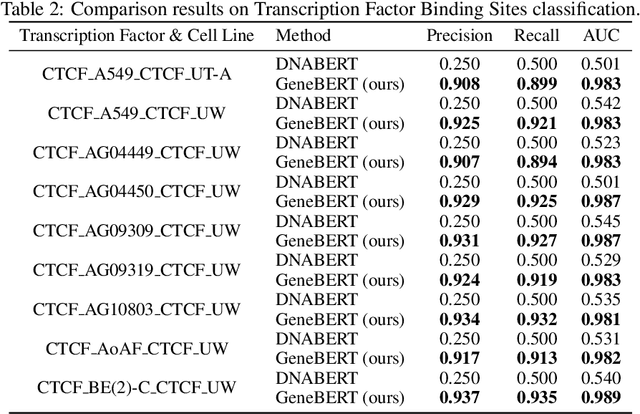
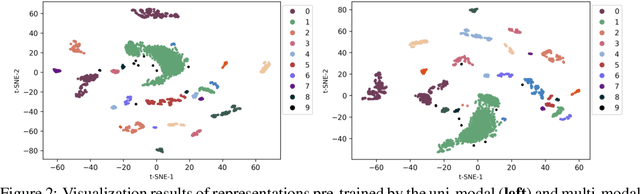
In the genome biology research, regulatory genome modeling is an important topic for many regulatory downstream tasks, such as promoter classification, transaction factor binding sites prediction. The core problem is to model how regulatory elements interact with each other and its variability across different cell types. However, current deep learning methods often focus on modeling genome sequences of a fixed set of cell types and do not account for the interaction between multiple regulatory elements, making them only perform well on the cell types in the training set and lack the generalizability required in biological applications. In this work, we propose a simple yet effective approach for pre-training genome data in a multi-modal and self-supervised manner, which we call GeneBERT. Specifically, we simultaneously take the 1d sequence of genome data and a 2d matrix of (transcription factors x regions) as the input, where three pre-training tasks are proposed to improve the robustness and generalizability of our model. We pre-train our model on the ATAC-seq dataset with 17 million genome sequences. We evaluate our GeneBERT on regulatory downstream tasks across different cell types, including promoter classification, transaction factor binding sites prediction, disease risk estimation, and splicing sites prediction. Extensive experiments demonstrate the effectiveness of multi-modal and self-supervised pre-training for large-scale regulatory genomics data.
Effective Use of Bidirectional Language Modeling for Transfer Learning in Biomedical Named Entity Recognition
Aug 15, 2018
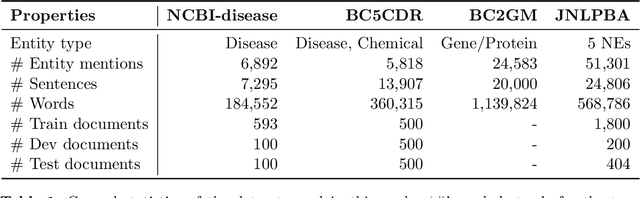
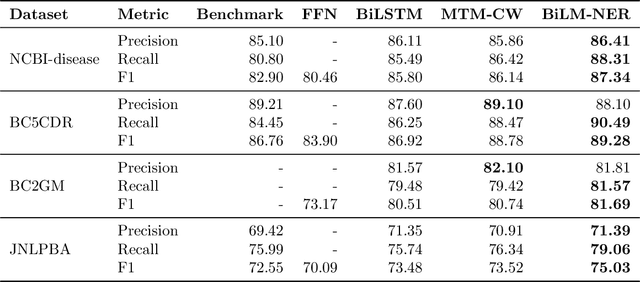
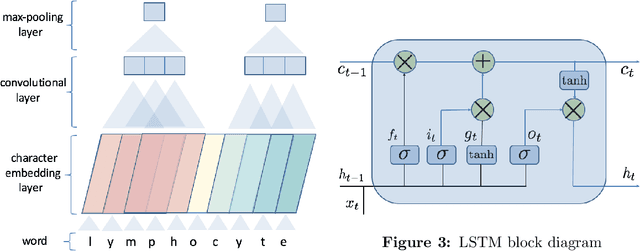
Biomedical named entity recognition (NER) is a fundamental task in text mining of medical documents and has many applications. Deep learning based approaches to this task have been gaining increasing attention in recent years as their parameters can be learned end-to-end without the need for hand-engineered features. However, these approaches rely on high-quality labeled data, which is expensive to obtain. To address this issue, we investigate how to use unlabeled text data to improve the performance of NER models. Specifically, we train a bidirectional language model (BiLM) on unlabeled data and transfer its weights to "pretrain" an NER model with the same architecture as the BiLM, which results in a better parameter initialization of the NER model. We evaluate our approach on four benchmark datasets for biomedical NER and show that it leads to a substantial improvement in the F1 scores compared with the state-of-the-art approaches. We also show that BiLM weight transfer leads to a faster model training and the pretrained model requires fewer training examples to achieve a particular F1 score.
State Space LSTM Models with Particle MCMC Inference
Nov 30, 2017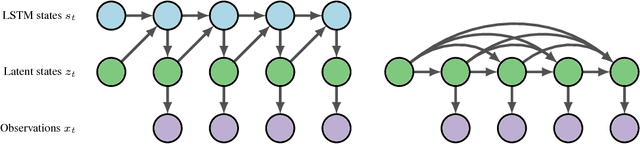
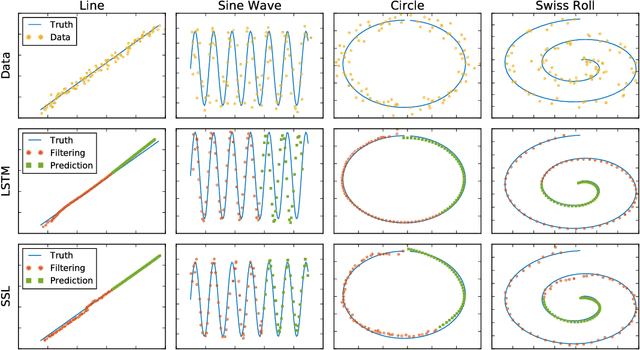
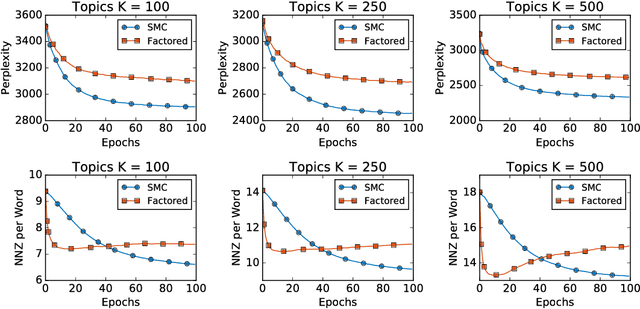
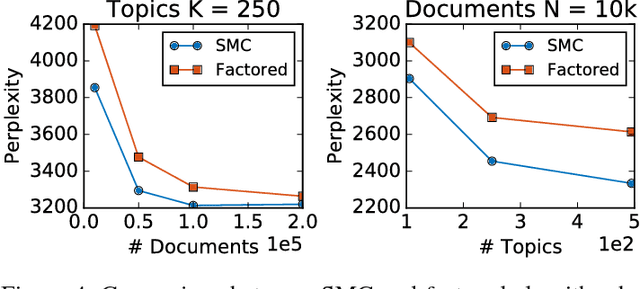
Long Short-Term Memory (LSTM) is one of the most powerful sequence models. Despite the strong performance, however, it lacks the nice interpretability as in state space models. In this paper, we present a way to combine the best of both worlds by introducing State Space LSTM (SSL) models that generalizes the earlier work \cite{zaheer2017latent} of combining topic models with LSTM. However, unlike \cite{zaheer2017latent}, we do not make any factorization assumptions in our inference algorithm. We present an efficient sampler based on sequential Monte Carlo (SMC) method that draws from the joint posterior directly. Experimental results confirms the superiority and stability of this SMC inference algorithm on a variety of domains.
Mixed membership stochastic blockmodels
May 30, 2007

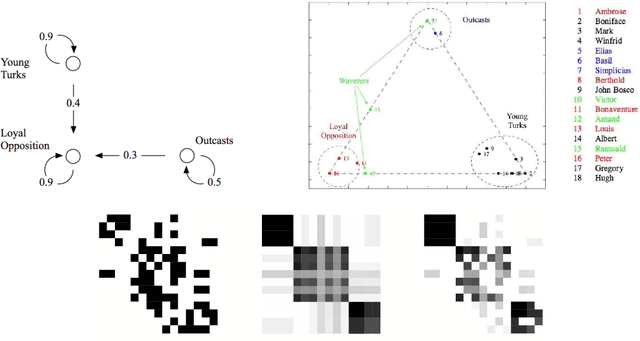
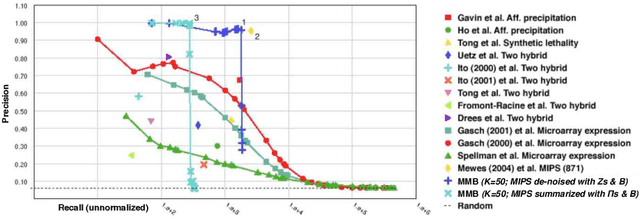
Observations consisting of measurements on relationships for pairs of objects arise in many settings, such as protein interaction and gene regulatory networks, collections of author-recipient email, and social networks. Analyzing such data with probabilisic models can be delicate because the simple exchangeability assumptions underlying many boilerplate models no longer hold. In this paper, we describe a latent variable model of such data called the mixed membership stochastic blockmodel. This model extends blockmodels for relational data to ones which capture mixed membership latent relational structure, thus providing an object-specific low-dimensional representation. We develop a general variational inference algorithm for fast approximate posterior inference. We explore applications to social and protein interaction networks.
* 46 pages, 14 figures, 3 tables