 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIRE-Bench: Evaluating Agents on the Rediscovery of Scientific Insights
Feb 02, 2026Autonomous agents powered by large language models (LLMs) promise to accelerate scientific discovery end-to-end, but rigorously evaluating their capacity for verifiable discovery remains a central challenge. Existing benchmarks face a trade-off: they either heavily rely on LLM-as-judge evaluations of automatically generated research outputs or optimize convenient yet isolated performance metrics that provide coarse proxies for scientific insight. To address this gap, we introduce FIRE-Bench (Full-cycle Insight Rediscovery Evaluation), a benchmark that evaluates agents through the rediscovery of established findings from recent, high-impact machine learning research. Agents are given only a high-level research question extracted from a published, verified study and must autonomously explore ideas, design experiments, implement code, execute their plans, and derive conclusions supported by empirical evidence. We evaluate a range of state-of-the-art agents with frontier LLMs backbones like gpt-5 on FIRE-Bench. Our results show that full-cycle scientific research remains challenging for current agent systems: even the strongest agents achieve limited rediscovery success (<50 F1), exhibit high variance across runs, and display recurring failure modes in experimental design, execution, and evidence-based reasoning. FIRE-Bench provides a rigorous and diagnostic framework for measuring progress toward reliable agent-driven scientific discovery.
Learning Modal-Mixed Chain-of-Thought Reasoning with Latent Embeddings
Jan 31, 2026We study how to extend chain-of-thought (CoT) beyond language to better handle multimodal reasoning. While CoT helps LLMs and VLMs articulate intermediate steps, its text-only form often fails on vision-intensive problems where key intermediate states are inherently visual. We introduce modal-mixed CoT, which interleaves textual tokens with compact visual sketches represented as latent embeddings. To bridge the modality gap without eroding the original knowledge and capability of the VLM, we use the VLM itself as an encoder and train the language backbone to reconstruct its own intermediate vision embeddings, to guarantee the semantic alignment of the visual latent space. We further attach a diffusion-based latent decoder, invoked by a special control token and conditioned on hidden states from the VLM. In this way, the diffusion head carries fine-grained perceptual details while the VLM specifies high-level intent, which cleanly disentangles roles and reduces the optimization pressure of the VLM. Training proceeds in two stages: supervised fine-tuning on traces that interleave text and latents with a joint next-token and latent-reconstruction objective, followed by reinforcement learning that teaches when to switch modalities and how to compose long reasoning chains. Extensive experiments across 11 diverse multimodal reasoning tasks, demonstrate that our method yields better performance than language-only and other CoT methods. Our code will be publicly released.
SimWorld-Robotics: Synthesizing Photorealistic and Dynamic Urban Environments for Multimodal Robot Navigation and Collaboration
Dec 10, 2025Recent advances in foundation models have shown promising results in developing generalist robotics that can perform diverse tasks in open-ended scenarios given multimodal inputs. However, current work has been mainly focused on indoor, household scenarios. In this work, we present SimWorld-Robotics~(SWR), a simulation platform for embodied AI in large-scale, photorealistic urban environments. Built on Unreal Engine 5, SWR procedurally generates unlimited photorealistic urban scenes populated with dynamic elements such as pedestrians and traffic systems, surpassing prior urban simulations in realism, complexity, and scalability. It also supports multi-robot control and communication. With these key features, we build two challenging robot benchmarks: (1) a multimodal instruction-following task, where a robot must follow vision-language navigation instructions to reach a destination in the presence of pedestrians and traffic; and (2) a multi-agent search task, where two robots must communicate to cooperatively locate and meet each other. Unlike existing benchmarks, these two new benchmarks comprehensively evaluate a wide range of critical robot capacities in realistic scenarios, including (1) multimodal instructions grounding, (2) 3D spatial reasoning in large environments, (3) safe, long-range navigation with people and traffic, (4) multi-robot collaboration, and (5) grounded communication. Our experimental results demonstrate that state-of-the-art models, including vision-language models (VLMs), struggle with our tasks, lacking robust perception, reasoning, and planning abilities necessary for urban environments.
PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025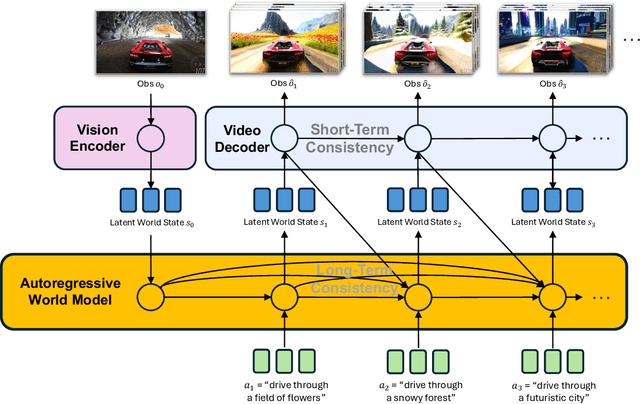
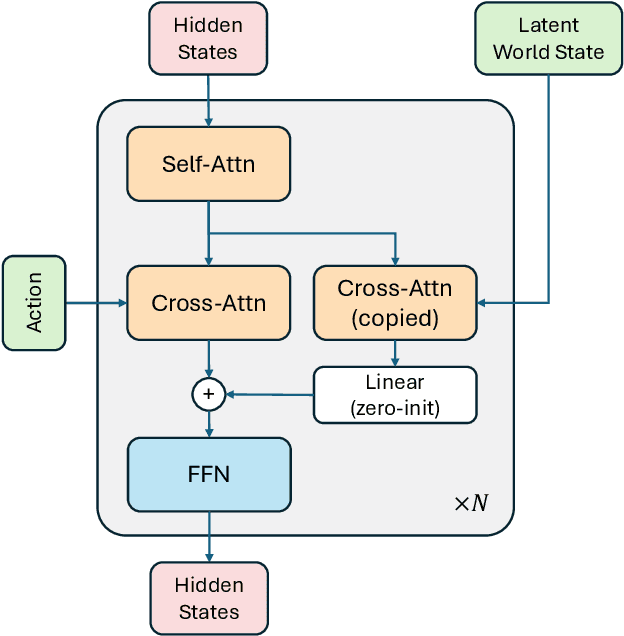
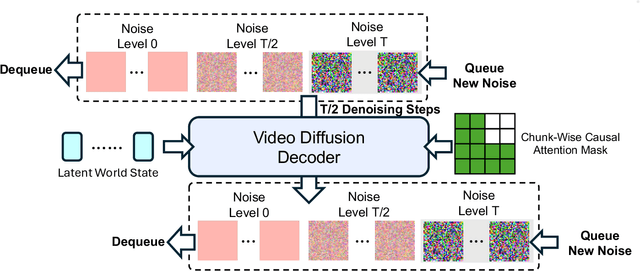
A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
K2-Think: A Parameter-Efficient Reasoning System
Sep 09, 2025K2-Think is a reasoning system that achieves state-of-the-art performance with a 32B parameter model, matching or surpassing much larger models like GPT-OSS 120B and DeepSeek v3.1. Built on the Qwen2.5 base model, our system shows that smaller models can compete at the highest levels by combining advanced post-training and test-time computation techniques. The approach is based on six key technical pillars: Long Chain-of-thought Supervised Finetuning, Reinforcement Learning with Verifiable Rewards (RLVR), Agentic planning prior to reasoning, Test-time Scaling, Speculative Decoding, and Inference-optimized Hardware, all using publicly available open-source datasets. K2-Think excels in mathematical reasoning, achieving state-of-the-art scores on public benchmarks for open-source models, while also performing strongly in other areas such as Code and Science. Our results confirm that a more parameter-efficient model like K2-Think 32B can compete with state-of-the-art systems through an integrated post-training recipe that includes long chain-of-thought training and strategic inference-time enhancements, making open-source reasoning systems more accessible and affordable. K2-Think is freely available at k2think.ai, offering best-in-class inference speeds of over 2,000 tokens per second per request via the Cerebras Wafer-Scale Engine.
ArcMemo: Abstract Reasoning Composition with Lifelong LLM Memory
Sep 04, 2025


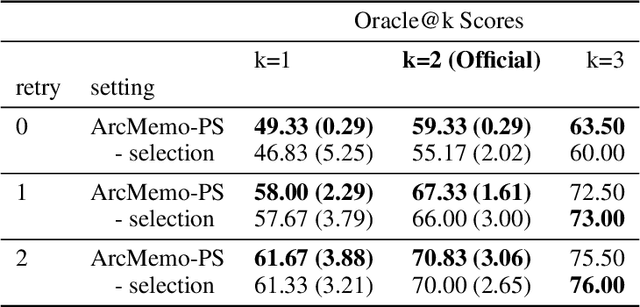
While inference-time scaling enables LLMs to carry out increasingly long and capable reasoning traces, the patterns and insights uncovered during these traces are immediately discarded once the context window is reset for a new query. External memory is a natural way to persist these discoveries, and recent work has shown clear benefits for reasoning-intensive tasks. We see an opportunity to make such memories more broadly reusable and scalable by moving beyond instance-based memory entries (e.g. exact query/response pairs, or summaries tightly coupled with the original problem context) toward concept-level memory: reusable, modular abstractions distilled from solution traces and stored in natural language. For future queries, relevant concepts are selectively retrieved and integrated into the prompt, enabling test-time continual learning without weight updates. Our design introduces new strategies for abstracting takeaways from rollouts and retrieving entries for new queries, promoting reuse and allowing memory to expand with additional experiences. On the challenging ARC-AGI benchmark, our method yields a 7.5% relative gain over a strong no-memory baseline with performance continuing to scale with inference compute. We find abstract concepts to be the most consistent memory design, outscoring the baseline at all tested inference compute scales. Moreover, we confirm that dynamically updating memory during test-time outperforms an otherwise identical fixed memory setting with additional attempts, supporting the hypothesis that solving more problems and abstracting more patterns to memory enables further solutions in a form of self-improvement. Code available at https://github.com/matt-seb-ho/arc_memo.
Vision-G1: Towards General Vision Language Reasoning with Multi-Domain Data Curation
Aug 18, 2025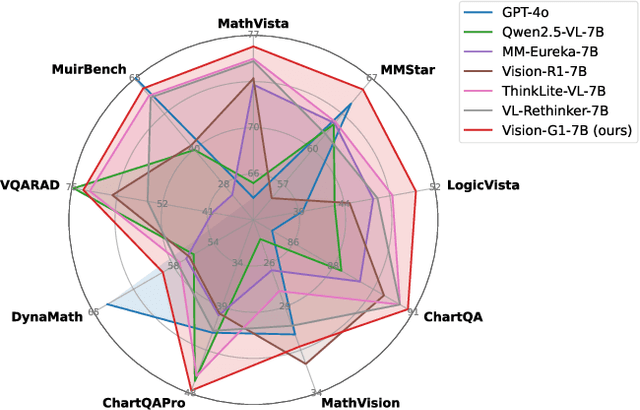
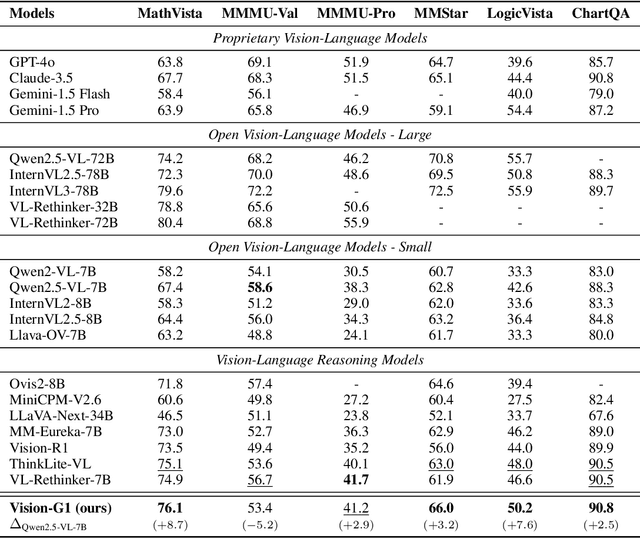
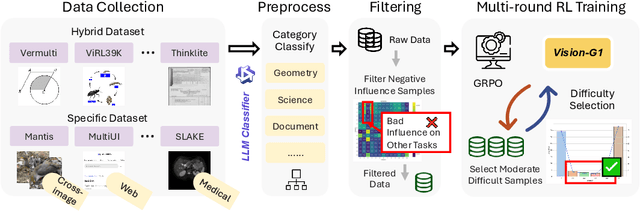
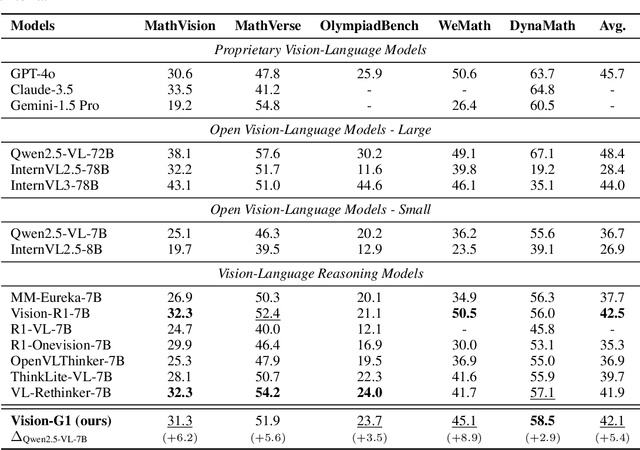
Despite their success, current training pipelines for reasoning VLMs focus on a limited range of tasks, such as mathematical and logical reasoning. As a result, these models face difficulties in generalizing their reasoning capabilities to a wide range of domains, primarily due to the scarcity of readily available and verifiable reward data beyond these narrowly defined areas. Moreover, integrating data from multiple domains is challenging, as the compatibility between domain-specific datasets remains uncertain. To address these limitations, we build a comprehensive RL-ready visual reasoning dataset from 46 data sources across 8 dimensions, covering a wide range of tasks such as infographic, mathematical, spatial, cross-image, graphic user interface, medical, common sense and general science. We propose an influence function based data selection and difficulty based filtering strategy to identify high-quality training samples from this dataset. Subsequently, we train the VLM, referred to as Vision-G1, using multi-round RL with a data curriculum to iteratively improve its visual reasoning capabilities. Our model achieves state-of-the-art performance across various visual reasoning benchmarks, outperforming similar-sized VLMs and even proprietary models like GPT-4o and Gemini-1.5 Flash. The model, code and dataset are publicly available at https://github.com/yuh-zha/Vision-G1.
SimuRA: Towards General Goal-Oriented Agent via Simulative Reasoning Architecture with LLM-Based World Model
Jul 31, 2025



AI agents built on large language models (LLMs) hold enormous promise, but current practice focuses on a one-task-one-agent approach, which not only falls short of scalability and generality, but also suffers from the fundamental limitations of autoregressive LLMs. On the other hand, humans are general agents who reason by mentally simulating the outcomes of their actions and plans. Moving towards a more general and powerful AI agent, we introduce SimuRA, a goal-oriented architecture for generalized agentic reasoning. Based on a principled formulation of optimal agent in any environment, \modelname overcomes the limitations of autoregressive reasoning by introducing a world model for planning via simulation. The generalized world model is implemented using LLM, which can flexibly plan in a wide range of environments using the concept-rich latent space of natural language. Experiments on difficult web browsing tasks show that \modelname improves the success of flight search from 0\% to 32.2\%. World-model-based planning, in particular, shows consistent advantage of up to 124\% over autoregressive planning, demonstrating the advantage of world model simulation as a reasoning paradigm. We are excited about the possibility for training a single, general agent model based on LLMs that can act superintelligently in all environments. To start, we make SimuRA, a web-browsing agent built on \modelname with pretrained LLMs, available as a research demo for public testing.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025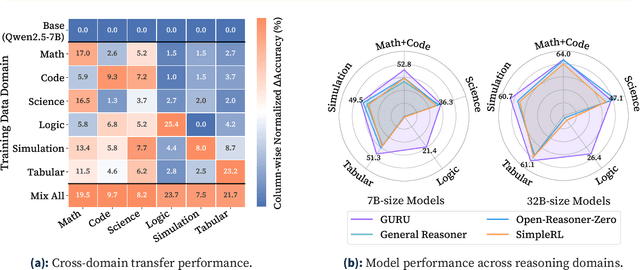
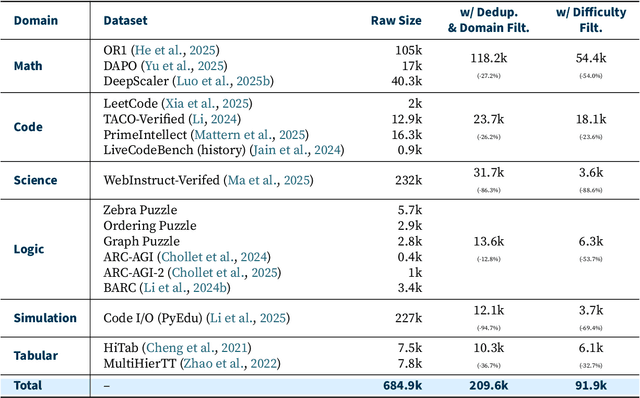
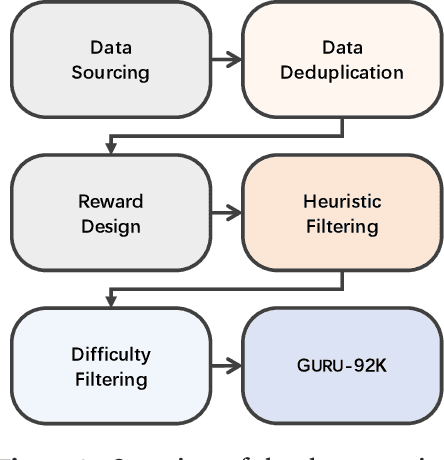

Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
Activation Control for Efficiently Eliciting Long Chain-of-thought Ability of Language Models
May 23, 2025Despite the remarkable reasoning performance, eliciting the long chain-of-thought (CoT) ability in large language models (LLMs) typically requires costly reinforcement learning or supervised fine-tuning on high-quality distilled data. We investigate the internal mechanisms behind this capability and show that a small set of high-impact activations in the last few layers largely governs long-form reasoning attributes, such as output length and self-reflection. By simply amplifying these activations and inserting "wait" tokens, we can invoke the long CoT ability without any training, resulting in significantly increased self-reflection rates and accuracy. Moreover, we find that the activation dynamics follow predictable trajectories, with a sharp rise after special tokens and a subsequent exponential decay. Building on these insights, we introduce a general training-free activation control technique. It leverages a few contrastive examples to identify key activations, and employs simple analytic functions to modulate their values at inference time to elicit long CoTs. Extensive experiments confirm the effectiveness of our method in efficiently eliciting long CoT reasoning in LLMs and improving their performance. Additionally, we propose a parameter-efficient fine-tuning method that trains only a last-layer activation amplification module and a few LoRA layers, outperforming full LoRA fine-tuning on reasoning benchmarks with significantly fewer parameters. Our code and data are publicly released.