 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTool-R1: VLMs Learn to Think with Images via Reinforcement Learning on Multimodal Tool Use
May 25, 2025Reinforcement Learning Finetuning (RFT) has significantly advanced the reasoning capabilities of large language models (LLMs) by enabling long chains of thought, self-correction, and effective tool use. While recent works attempt to extend RFT to vision-language models (VLMs), these efforts largely produce text-only reasoning conditioned on static image inputs, falling short of true multimodal reasoning in the response. In contrast, test-time methods like Visual Sketchpad incorporate visual steps but lack training mechanisms. We introduce VTool-R1, the first framework that trains VLMs to generate multimodal chains of thought by interleaving text and intermediate visual reasoning steps. VTool-R1 integrates Python-based visual editing tools into the RFT process, enabling VLMs to learn when and how to generate visual reasoning steps that benefit final reasoning. Trained with outcome-based rewards tied to task accuracy, our approach elicits strategic visual tool use for reasoning without relying on process-based supervision. Experiments on structured visual question answering over charts and tables show that VTool-R1 enhances reasoning performance by teaching VLMs to "think with images" and generate multimodal chain of thoughts with tools.
Cache-of-Thought: Master-Apprentice Framework for Cost-Effective Vision Language Model Inference
Feb 27, 2025Vision Language Models (VLMs) have achieved remarkable success in a wide range of vision applications of increasing complexity and scales, yet choosing the right VLM model size involves a trade-off between response quality and cost. While smaller VLMs are cheaper to run, they typically produce responses only marginally better than random guessing on benchmarks such as MMMU. In this paper, we propose Cache of Thought (CoT), a master apprentice framework for collaborative inference between large and small VLMs. CoT manages high quality query results from large VLMs (master) in a cache, which are then selected via a novel multi modal retrieval and in-context learning to aid the performance of small VLMs (apprentice). We extensively evaluate CoT on various widely recognized and challenging general VQA benchmarks, and show that CoT increases overall VQA performance by up to 7.7% under the same budget, and specifically boosts the performance of apprentice VLMs by up to 36.6%.
UOUO: Uncontextualized Uncommon Objects for Measuring Knowledge Horizons of Vision Language Models
Jul 25, 2024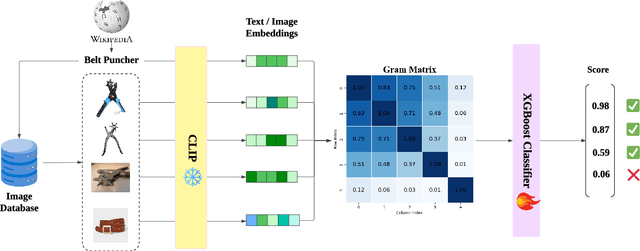
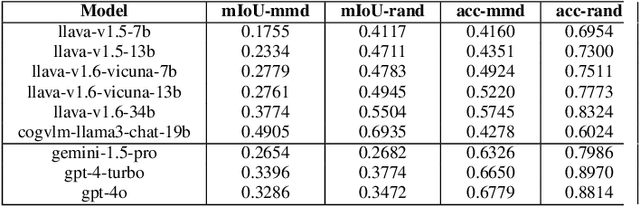
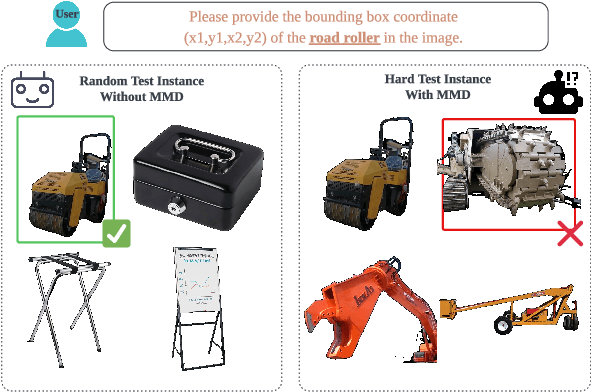
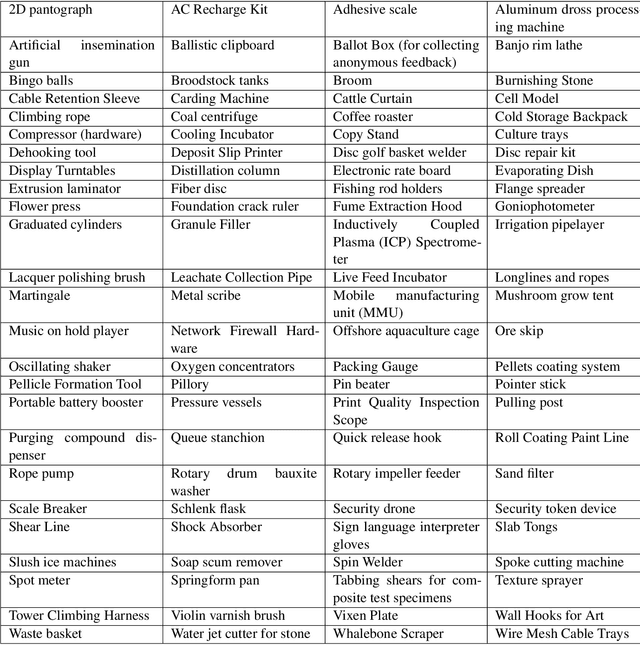
Smaller-scale Vision-Langauge Models (VLMs) often claim to perform on par with larger models in general-domain visual grounding and question-answering benchmarks while offering advantages in computational efficiency and storage. However, their ability to handle rare objects, which fall into the long tail of data distributions, is less understood. To rigorously evaluate this aspect, we introduce the "Uncontextualized Uncommon Objects" (UOUO) benchmark. This benchmark focuses on systematically testing VLMs with both large and small parameter counts on rare and specialized objects. Our comprehensive analysis reveals that while smaller VLMs maintain competitive performance on common datasets, they significantly underperform on tasks involving uncommon objects. We also propose an advanced, scalable pipeline for data collection and cleaning, ensuring the UOUO benchmark provides high-quality, challenging instances. These findings highlight the need to consider long-tail distributions when assessing the true capabilities of VLMs.
TraceNet: Segment one thing efficiently
Jun 21, 2024
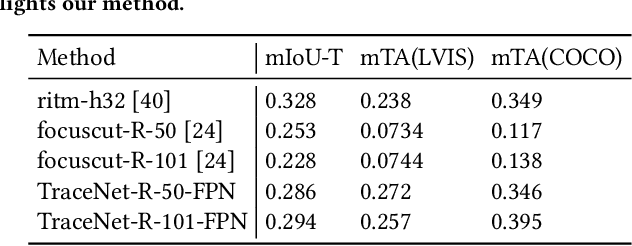
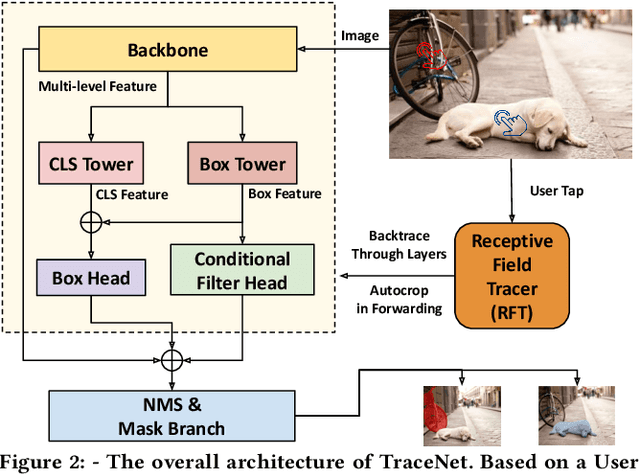

Efficient single instance segmentation is essential for unlocking features in the mobile imaging applications, such as capture or editing. Existing on-the-fly mobile imaging applications scope the segmentation task to portraits or the salient subject due to the computational constraints. Instance segmentation, despite its recent developments towards efficient networks, is still heavy due to the cost of computation on the entire image to identify all instances. To address this, we propose and formulate a one tap driven single instance segmentation task that segments a single instance selected by a user via a positive tap. This task, in contrast to the broader task of segmenting anything as suggested in the Segment Anything Model \cite{sam}, focuses on efficient segmentation of a single instance specified by the user. To solve this problem, we present TraceNet, which explicitly locates the selected instance by way of receptive field tracing. TraceNet identifies image regions that are related to the user tap and heavy computations are only performed on selected regions of the image. Therefore overall computation cost and memory consumption are reduced during inference. We evaluate the performance of TraceNet on instance IoU average over taps and the proportion of the region that a user tap can fall into for a high-quality single-instance mask. Experimental results on MS-COCO and LVIS demonstrate the effectiveness and efficiency of the proposed approach. TraceNet can jointly achieve the efficiency and interactivity, filling in the gap between needs for efficient mobile inference and recent research trend towards multimodal and interactive segmentation models.