 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIEVE: Effective Filtered Vector Search with Collection of Indexes
Jul 16, 2025Many real-world tasks such as recommending videos with the kids tag can be reduced to finding most similar vectors associated with hard predicates. This task, filtered vector search, is challenging as prior state-of-the-art graph-based (unfiltered) similarity search techniques quickly degenerate when hard constraints are considered. That is, effective graph-based filtered similarity search relies on sufficient connectivity for reaching the most similar items within just a few hops. To consider predicates, recent works propose modifying graph traversal to visit only the items that may satisfy predicates. However, they fail to offer the just-a-few-hops property for a wide range of predicates: they must restrict predicates significantly or lose efficiency if only a small fraction of items satisfy predicates. We propose an opposite approach: instead of constraining traversal, we build many indexes each serving different predicate forms. For effective construction, we devise a three-dimensional analytical model capturing relationships among index size, search time, and recall, with which we follow a workload-aware approach to pack as many useful indexes as possible into a collection. At query time, the analytical model is employed yet again to discern the one that offers the fastest search at a given recall. We show superior performance and support on datasets with varying selectivities and forms: our approach achieves up to 8.06x speedup while having as low as 1% build time versus other indexes, with less than 2.15x memory of a standard HNSW graph and modest knowledge of past workloads.
Cache-of-Thought: Master-Apprentice Framework for Cost-Effective Vision Language Model Inference
Feb 27, 2025Vision Language Models (VLMs) have achieved remarkable success in a wide range of vision applications of increasing complexity and scales, yet choosing the right VLM model size involves a trade-off between response quality and cost. While smaller VLMs are cheaper to run, they typically produce responses only marginally better than random guessing on benchmarks such as MMMU. In this paper, we propose Cache of Thought (CoT), a master apprentice framework for collaborative inference between large and small VLMs. CoT manages high quality query results from large VLMs (master) in a cache, which are then selected via a novel multi modal retrieval and in-context learning to aid the performance of small VLMs (apprentice). We extensively evaluate CoT on various widely recognized and challenging general VQA benchmarks, and show that CoT increases overall VQA performance by up to 7.7% under the same budget, and specifically boosts the performance of apprentice VLMs by up to 36.6%.
Transactional Python for Durable Machine Learning: Vision, Challenges, and Feasibility
May 15, 2023



In machine learning (ML), Python serves as a convenient abstraction for working with key libraries such as PyTorch, scikit-learn, and others. Unlike DBMS, however, Python applications may lose important data, such as trained models and extracted features, due to machine failures or human errors, leading to a waste of time and resources. Specifically, they lack four essential properties that could make ML more reliable and user-friendly -- durability, atomicity, replicability, and time-versioning (DART). This paper presents our vision of Transactional Python that provides DART without any code modifications to user programs or the Python kernel, by non-intrusively monitoring application states at the object level and determining a minimal amount of information sufficient to reconstruct a whole application. Our evaluation of a proof-of-concept implementation with public PyTorch and scikit-learn applications shows that DART can be offered with overheads ranging 1.5%--15.6%.
Revamp: Enhancing Accessible Information Seeking Experience of Online Shopping for Blind or Low Vision Users
Feb 01, 2021
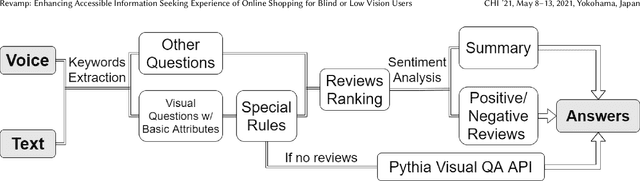

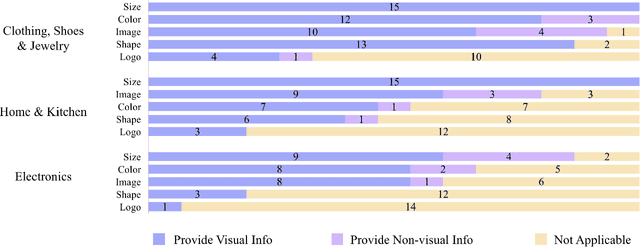
Online shopping has become a valuable modern convenience, but blind or low vision (BLV) users still face significant challenges using it, because of: 1) inadequate image descriptions and 2) the inability to filter large amounts of information using screen readers. To address those challenges, we propose Revamp, a system that leverages customer reviews for interactive information retrieval. Revamp is a browser integration that supports review-based question-answering interactions on a reconstructed product page. From our interview, we identified four main aspects (color, logo, shape, and size) that are vital for BLV users to understand the visual appearance of a product. Based on the findings, we formulated syntactic rules to extract review snippets, which were used to generate image descriptions and responses to users' queries. Evaluations with eight BLV users showed that Revamp 1) provided useful descriptive information for understanding product appearance and 2) helped the participants locate key information efficiently.