 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazyAttention: Efficient Retrieval-Augmented Generation with Deferred Positional Encoding
Jun 03, 2026Key-value (KV) caching accelerates inference of large language models (LLMs) by reusing past computations for generated tokens. Its importance becomes even greater in long-context applications such as retrieval-augmented generation (RAG) and in-context learning (ICL). However, conventional KV caching embeds positional information directly into the cache, limiting its reusability. Existing solutions either restrict reuse to prefixes or require expensive memory materialization for positional re-encoding. We introduce LazyAttention, a novel attention mechanism that kernelizes deferred positional encoding to enable zero-copy, position-agnostic KV reuse. By adjusting positional encoding within attention kernels on-the-fly, LazyAttention resolves the materialization bottleneck, allowing a single physical KV copy to serve multiple logical requests at arbitrary positions. Leveraging attention kernels tailored for prefilling and decoding, our system achieves significant efficiency improvements: under skewed document distributions, it reduces time-to-first-token (TTFT) by 1.37$\times$ and increases inference throughput by 1.40$\times$ compared to the state-of-the-art Block-Attention, while maintaining comparable output quality.
Transactional Python for Durable Machine Learning: Vision, Challenges, and Feasibility
May 15, 2023



In machine learning (ML), Python serves as a convenient abstraction for working with key libraries such as PyTorch, scikit-learn, and others. Unlike DBMS, however, Python applications may lose important data, such as trained models and extracted features, due to machine failures or human errors, leading to a waste of time and resources. Specifically, they lack four essential properties that could make ML more reliable and user-friendly -- durability, atomicity, replicability, and time-versioning (DART). This paper presents our vision of Transactional Python that provides DART without any code modifications to user programs or the Python kernel, by non-intrusively monitoring application states at the object level and determining a minimal amount of information sufficient to reconstruct a whole application. Our evaluation of a proof-of-concept implementation with public PyTorch and scikit-learn applications shows that DART can be offered with overheads ranging 1.5%--15.6%.
Probabilistic PolarGMM: Unsupervised Cluster Learning of Very Noisy Projection Images of Unknown Pose
Jun 26, 2022



A crucial step in single particle analysis (SPA) of cryogenic electron microscopy (Cryo-EM), 2D classification and alignment takes a collection of noisy particle images to infer orientations and group similar images together. Averaging these aligned and clustered noisy images produces a set of clean images, ready for further analysis such as 3D reconstruction. Fourier-Bessel steerable principal component analysis (FBsPCA) enables an efficient, adaptable, low-rank rotation operator. We extend the FBsPCA to additionally handle translations. In this extended FBsPCA representation, we use a probabilistic polar-coordinate Gaussian mixture model to learn soft clusters in an unsupervised fashion using an expectation maximization (EM) algorithm. The obtained rotational clusters are thus additionally robust to the presence of pairwise alignment imperfections. Multiple benchmarks from simulated Cryo-EM datasets show probabilistic PolarGMM's improved performance in comparisons with standard single-particle Cryo-EM tools, EMAN2 and RELION, in terms of various clustering metrics and alignment errors.
Airphant: Cloud-oriented Document Indexing
Dec 26, 2021



Modern data warehouses can scale compute nodes independently of storage. These systems persist their data on cloud storage, which is always available and cost-efficient. Ad-hoc compute nodes then fetch necessary data on-demand from cloud storage. This ability to quickly scale or shrink data systems is highly beneficial if query workloads may change over time. We apply this new architecture to search engines with a focus on optimizing their latencies in cloud environments. However, simply placing existing search engines (e.g., Apache Lucene) on top of cloud storage significantly increases their end-to-end query latencies (i.e., more than 6 seconds on average in one of our studies). This is because their indexes can incur multiple network round-trips due to their hierarchical structure (e.g., skip lists, B-trees, learned indexes). To address this issue, we develop a new statistical index (called IoU Sketch). For lookup, IoU Sketch makes multiple asynchronous network requests in parallel. While IoU Sketch may fetch more bytes than existing indexes, it significantly reduces the index lookup time because parallel requests do not block each other. Based on IoU Sketch, we build an end-to-end search engine, called Airphant; we describe how Airphant builds, optimizes, and manages IoU Sketch; and ultimately, supports keyword-based querying. In our experiments with four real datasets, Airphant's average end-to-end latencies are between 13 milliseconds and 300 milliseconds, being up to 8.97x faster than Apache Lucence and 113.39x faster than Elasticsearch.
Hypothesis-Driven Skill Discovery for Hierarchical Deep Reinforcement Learning
May 27, 2019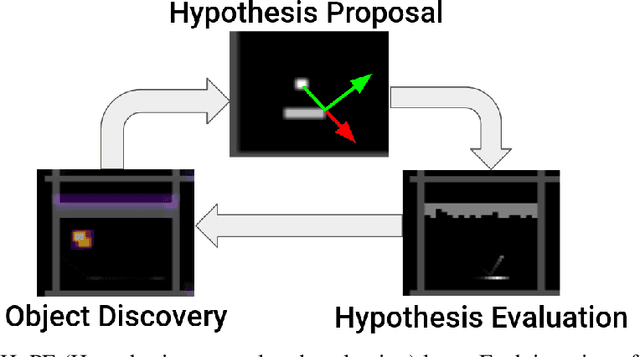


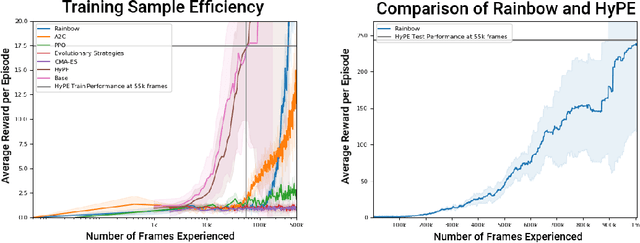
Deep reinforcement learning encompasses many versatile tools for designing learning agents that can perform well on a variety of high-dimensional visual tasks, ranging from video games to robotic manipulation. However, these methods typically suffer from poor sample efficiency, partially because they strive to be largely problem-agnostic. In this work, we demonstrate the utility of a different approach that is extremely sample efficient, but limited to object-centric tasks that (approximately) obey basic physical laws. Specifically, we propose the Hypothesis Proposal and Evaluation (HyPE) algorithm, which utilizes a small set of intuitive assumptions about the behavior of objects in the physical world (or in games that mimic physics) to automatically define and learn hierarchical skills in a highly efficient manner. HyPE does this by discovering objects from raw pixel data, generating hypotheses about the controllability of observed changes in object state, and learning a hierarchy of skills that can test these hypotheses and control increasingly complex interactions with objects. We demonstrate that HyPE can dramatically improve sample efficiency when learning a high-quality pixels-to-actions policy; in the popular benchmark task, Breakout, HyPE learns an order of magnitude faster than common baseline reinforcement learning and evolutionary strategies for policy learning.
Functional Generative Design: An Evolutionary Approach to 3D-Printing
Apr 19, 2018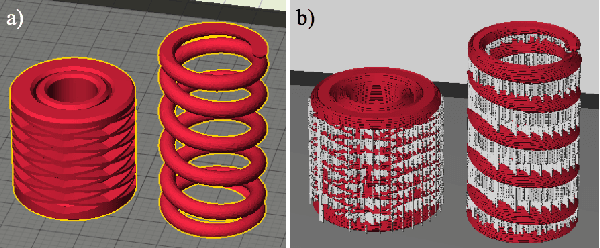



Consumer-grade printers are widely available, but their ability to print complex objects is limited. Therefore, new designs need to be discovered that serve the same function, but are printable. A representative such problem is to produce a working, reliable mechanical spring. The proposed methodology for discovering solutions to this problem consists of three components: First, an effective search space is learned through a variational autoencoder (VAE); second, a surrogate model for functional designs is built; and third, a genetic algorithm is used to simultaneously update the hyperparameters of the surrogate and to optimize the designs using the updated surrogate. Using a car-launcher mechanism as a test domain, spring designs were 3D-printed and evaluated to update the surrogate model. Two experiments were then performed: First, the initial set of designs for the surrogate-based optimizer was selected randomly from the training set that was used for training the VAE model, which resulted in an exploitative search behavior. On the other hand, in the second experiment, the initial set was composed of more uniformly selected designs from the same training set and a more explorative search behavior was observed. Both of the experiments showed that the methodology generates interesting, successful, and reliable spring geometries robust to the noise inherent in the 3D printing process. The methodology can be generalized to other functional design problems, thus making consumer-grade 3D printing more versatile.