 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing Humans with a Biomechanically Accurate Skeleton
Mar 27, 2025



In this paper, we introduce a method for reconstructing 3D humans from a single image using a biomechanically accurate skeleton model. To achieve this, we train a transformer that takes an image as input and estimates the parameters of the model. Due to the lack of training data for this task, we build a pipeline to produce pseudo ground truth model parameters for single images and implement a training procedure that iteratively refines these pseudo labels. Compared to state-of-the-art methods for 3D human mesh recovery, our model achieves competitive performance on standard benchmarks, while it significantly outperforms them in settings with extreme 3D poses and viewpoints. Additionally, we show that previous reconstruction methods frequently violate joint angle limits, leading to unnatural rotations. In contrast, our approach leverages the biomechanically plausible degrees of freedom making more realistic joint rotation estimates. We validate our approach across multiple human pose estimation benchmarks. We make the code, models and data available at: https://isshikihugh.github.io/HSMR/
Data-Free Learning of Reduced-Order Kinematics
May 05, 2023Physical systems ranging from elastic bodies to kinematic linkages are defined on high-dimensional configuration spaces, yet their typical low-energy configurations are concentrated on much lower-dimensional subspaces. This work addresses the challenge of identifying such subspaces automatically: given as input an energy function for a high-dimensional system, we produce a low-dimensional map whose image parameterizes a diverse yet low-energy submanifold of configurations. The only additional input needed is a single seed configuration for the system to initialize our procedure; no dataset of trajectories is required. We represent subspaces as neural networks that map a low-dimensional latent vector to the full configuration space, and propose a training scheme to fit network parameters to any system of interest. This formulation is effective across a very general range of physical systems; our experiments demonstrate not only nonlinear and very low-dimensional elastic body and cloth subspaces, but also more general systems like colliding rigid bodies and linkages. We briefly explore applications built on this formulation, including manipulation, latent interpolation, and sampling.
Virtual Elastic Objects
Jan 12, 2022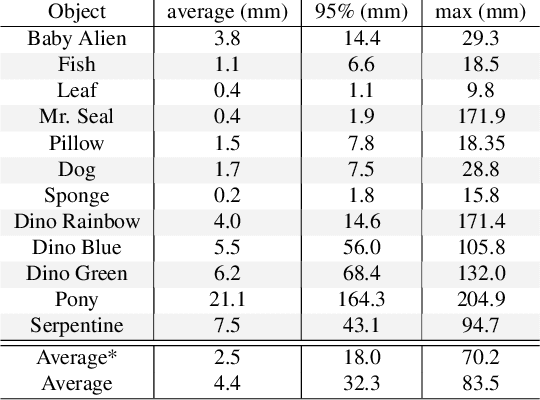

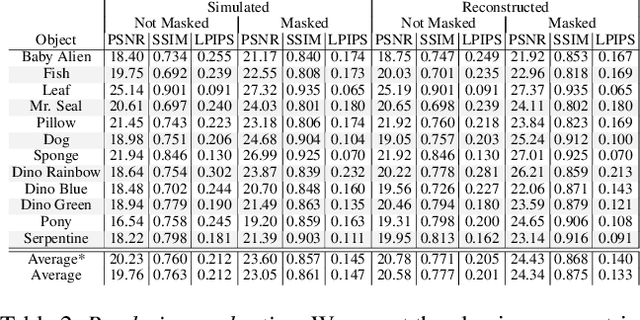

We present Virtual Elastic Objects (VEOs): virtual objects that not only look like their real-world counterparts but also behave like them, even when subject to novel interactions. Achieving this presents multiple challenges: not only do objects have to be captured including the physical forces acting on them, then faithfully reconstructed and rendered, but also plausible material parameters found and simulated. To create VEOs, we built a multi-view capture system that captures objects under the influence of a compressed air stream. Building on recent advances in model-free, dynamic Neural Radiance Fields, we reconstruct the objects and corresponding deformation fields. We propose to use a differentiable, particle-based simulator to use these deformation fields to find representative material parameters, which enable us to run new simulations. To render simulated objects, we devise a method for integrating the simulation results with Neural Radiance Fields. The resulting method is applicable to a wide range of scenarios: it can handle objects composed of inhomogeneous material, with very different shapes, and it can simulate interactions with other virtual objects. We present our results using a newly collected dataset of 12 objects under a variety of force fields, which will be shared with the community.
HPNet: Deep Primitive Segmentation Using Hybrid Representations
May 22, 2021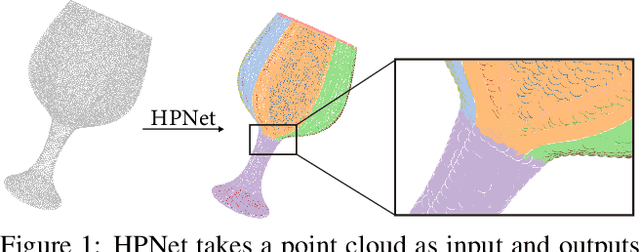

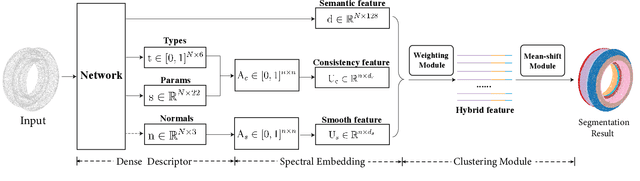
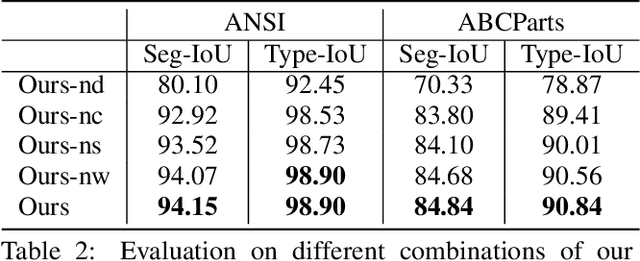
This paper introduces HPNet, a novel deep-learning approach for segmenting a 3D shape represented as a point cloud into primitive patches. The key to deep primitive segmentation is learning a feature representation that can separate points of different primitives. Unlike utilizing a single feature representation, HPNet leverages hybrid representations that combine one learned semantic descriptor, two spectral descriptors derived from predicted geometric parameters, as well as an adjacency matrix that encodes sharp edges. Moreover, instead of merely concatenating the descriptors, HPNet optimally combines hybrid representations by learning combination weights. This weighting module builds on the entropy of input features. The output primitive segmentation is obtained from a mean-shift clustering module. Experimental results on benchmark datasets ANSI and ABCParts show that HPNet leads to significant performance gains from baseline approaches.
Deep Generative Modeling for Scene Synthesis via Hybrid Representations
Aug 06, 2018
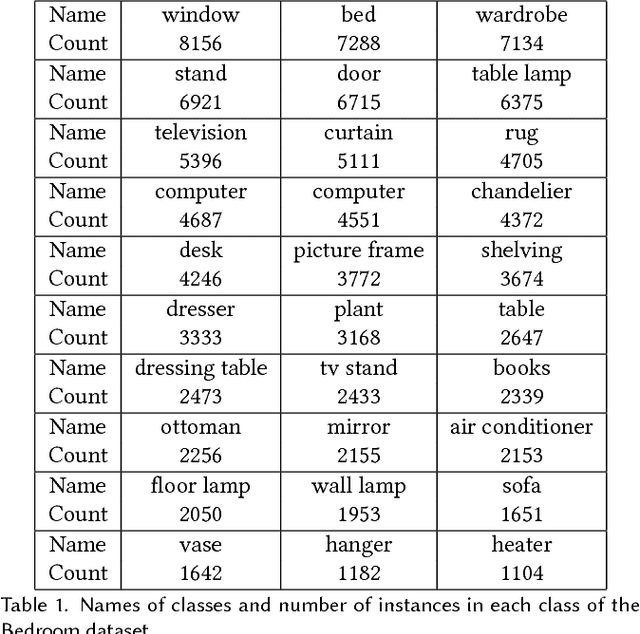
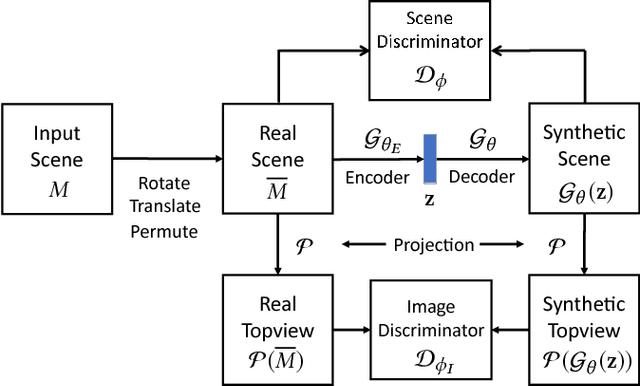
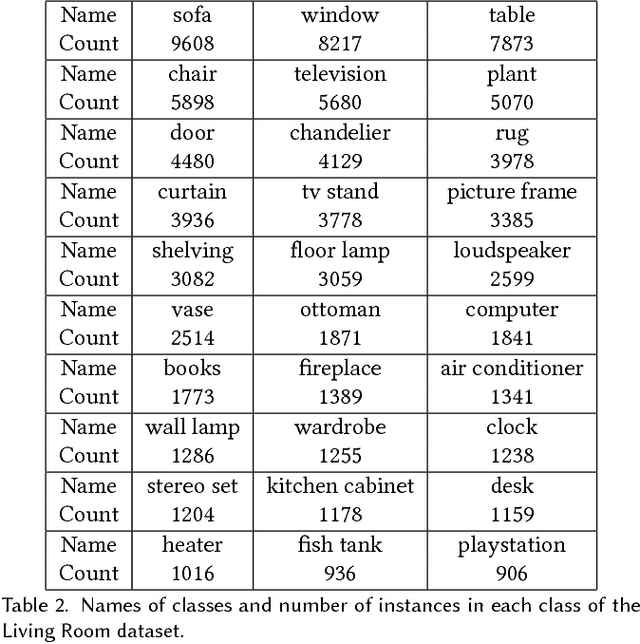
We present a deep generative scene modeling technique for indoor environments. Our goal is to train a generative model using a feed-forward neural network that maps a prior distribution (e.g., a normal distribution) to the distribution of primary objects in indoor scenes. We introduce a 3D object arrangement representation that models the locations and orientations of objects, based on their size and shape attributes. Moreover, our scene representation is applicable for 3D objects with different multiplicities (repetition counts), selected from a database. We show a principled way to train this model by combining discriminator losses for both a 3D object arrangement representation and a 2D image-based representation. We demonstrate the effectiveness of our scene representation and the deep learning method on benchmark datasets. We also show the applications of this generative model in scene interpolation and scene completion.
Functional Generative Design: An Evolutionary Approach to 3D-Printing
Apr 19, 2018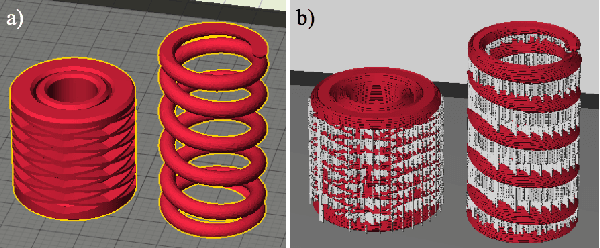



Consumer-grade printers are widely available, but their ability to print complex objects is limited. Therefore, new designs need to be discovered that serve the same function, but are printable. A representative such problem is to produce a working, reliable mechanical spring. The proposed methodology for discovering solutions to this problem consists of three components: First, an effective search space is learned through a variational autoencoder (VAE); second, a surrogate model for functional designs is built; and third, a genetic algorithm is used to simultaneously update the hyperparameters of the surrogate and to optimize the designs using the updated surrogate. Using a car-launcher mechanism as a test domain, spring designs were 3D-printed and evaluated to update the surrogate model. Two experiments were then performed: First, the initial set of designs for the surrogate-based optimizer was selected randomly from the training set that was used for training the VAE model, which resulted in an exploitative search behavior. On the other hand, in the second experiment, the initial set was composed of more uniformly selected designs from the same training set and a more explorative search behavior was observed. Both of the experiments showed that the methodology generates interesting, successful, and reliable spring geometries robust to the noise inherent in the 3D printing process. The methodology can be generalized to other functional design problems, thus making consumer-grade 3D printing more versatile.
Dense Human Body Correspondences Using Convolutional Networks
Jun 26, 2016
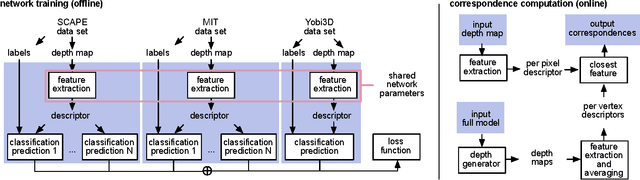

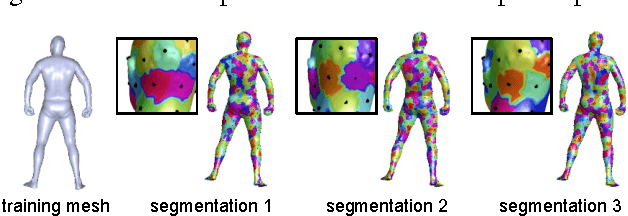
We propose a deep learning approach for finding dense correspondences between 3D scans of people. Our method requires only partial geometric information in the form of two depth maps or partial reconstructed surfaces, works for humans in arbitrary poses and wearing any clothing, does not require the two people to be scanned from similar viewpoints, and runs in real time. We use a deep convolutional neural network to train a feature descriptor on depth map pixels, but crucially, rather than training the network to solve the shape correspondence problem directly, we train it to solve a body region classification problem, modified to increase the smoothness of the learned descriptors near region boundaries. This approach ensures that nearby points on the human body are nearby in feature space, and vice versa, rendering the feature descriptor suitable for computing dense correspondences between the scans. We validate our method on real and synthetic data for both clothed and unclothed humans, and show that our correspondences are more robust than is possible with state-of-the-art unsupervised methods, and more accurate than those found using methods that require full watertight 3D geometry.
Capturing Dynamic Textured Surfaces of Moving Targets
Apr 11, 2016

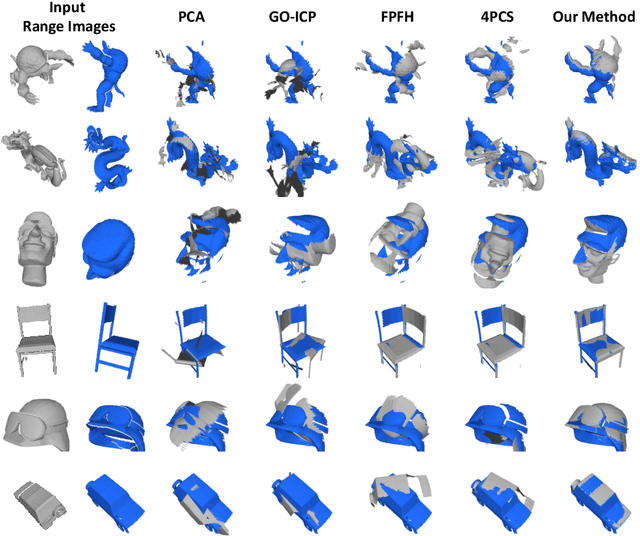
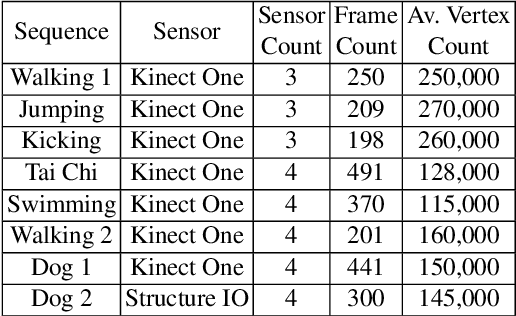
We present an end-to-end system for reconstructing complete watertight and textured models of moving subjects such as clothed humans and animals, using only three or four handheld sensors. The heart of our framework is a new pairwise registration algorithm that minimizes, using a particle swarm strategy, an alignment error metric based on mutual visibility and occlusion. We show that this algorithm reliably registers partial scans with as little as 15% overlap without requiring any initial correspondences, and outperforms alternative global registration algorithms. This registration algorithm allows us to reconstruct moving subjects from free-viewpoint video produced by consumer-grade sensors, without extensive sensor calibration, constrained capture volume, expensive arrays of cameras, or templates of the subject geometry.