 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Aware Reinforcement Learning for Output Diversity in Large Language Models
Nov 16, 2025Large Language Models (LLMs) often suffer from mode collapse, repeatedly generating the same few completions even when many valid answers exist, limiting their diversity across a wide range of tasks. We introduce Group-Aware Policy Optimization (GAPO), a simple extension of the recent and popular Group Relative Policy Optimization (GRPO) that computes rewards over the group as a whole. GAPO enables learning from the group-level properties such as diversity and coverage. We demonstrate GAPO using a frequency-aware reward function that encourages uniform sampling over valid LLM completions, and show that GAPO-trained models produce valid and more diverse model responses. Beyond this setup, GAPO generalizes to open-ended prompts and improves response diversity without compromising accuracy on standard LLM benchmarks (GSM8K, MATH, HumanEval, MMLU-Pro). Our code will be made publicly available.
LV-MAE: Learning Long Video Representations through Masked-Embedding Autoencoders
Apr 04, 2025In this work, we introduce long-video masked-embedding autoencoders (LV-MAE), a self-supervised learning framework for long video representation. Our approach treats short- and long-span dependencies as two separate tasks. Such decoupling allows for a more intuitive video processing where short-span spatiotemporal primitives are first encoded and are then used to capture long-range dependencies across consecutive video segments. To achieve this, we leverage advanced off-the-shelf multimodal encoders to extract representations from short segments within the long video, followed by pre-training a masked-embedding autoencoder capturing high-level interactions across segments. LV-MAE is highly efficient to train and enables the processing of much longer videos by alleviating the constraint on the number of input frames. Furthermore, unlike existing methods that typically pre-train on short-video datasets, our approach offers self-supervised pre-training using long video samples (e.g., 20+ minutes video clips) at scale. Using LV-MAE representations, we achieve state-of-the-art results on three long-video benchmarks -- LVU, COIN, and Breakfast -- employing only a simple classification head for either attentive or linear probing. Finally, to assess LV-MAE pre-training and visualize its reconstruction quality, we leverage the video-language aligned space of short video representations to monitor LV-MAE through video-text retrieval.
Data Pruning via Separability, Integrity, and Model Uncertainty-Aware Importance Sampling
Sep 20, 2024



This paper improves upon existing data pruning methods for image classification by introducing a novel pruning metric and pruning procedure based on importance sampling. The proposed pruning metric explicitly accounts for data separability, data integrity, and model uncertainty, while the sampling procedure is adaptive to the pruning ratio and considers both intra-class and inter-class separation to further enhance the effectiveness of pruning. Furthermore, the sampling method can readily be applied to other pruning metrics to improve their performance. Overall, the proposed approach scales well to high pruning ratio and generalizes better across different classification models, as demonstrated by experiments on four benchmark datasets, including the fine-grained classification scenario.
FPGAN-Control: A Controllable Fingerprint Generator for Training with Synthetic Data
Oct 29, 2023


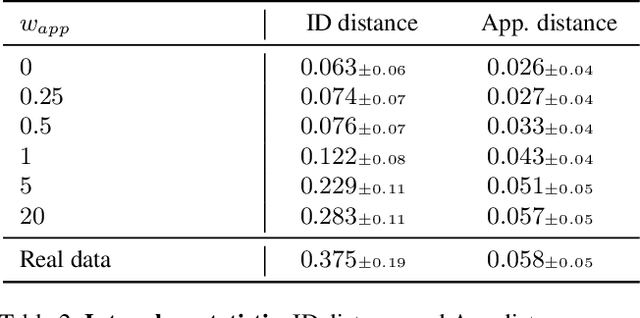
Training fingerprint recognition models using synthetic data has recently gained increased attention in the biometric community as it alleviates the dependency on sensitive personal data. Existing approaches for fingerprint generation are limited in their ability to generate diverse impressions of the same finger, a key property for providing effective data for training recognition models. To address this gap, we present FPGAN-Control, an identity preserving image generation framework which enables control over the fingerprint's image appearance (e.g., fingerprint type, acquisition device, pressure level) of generated fingerprints. We introduce a novel appearance loss that encourages disentanglement between the fingerprint's identity and appearance properties. In our experiments, we used the publicly available NIST SD302 (N2N) dataset for training the FPGAN-Control model. We demonstrate the merits of FPGAN-Control, both quantitatively and qualitatively, in terms of identity preservation level, degree of appearance control, and low synthetic-to-real domain gap. Finally, training recognition models using only synthetic datasets generated by FPGAN-Control lead to recognition accuracies that are on par or even surpass models trained using real data. To the best of our knowledge, this is the first work to demonstrate this.
Shape of You: Precise 3D shape estimations for diverse body types
Apr 14, 2023



This paper presents Shape of You (SoY), an approach to improve the accuracy of 3D body shape estimation for vision-based clothing recommendation systems. While existing methods have successfully estimated 3D poses, there remains a lack of work in precise shape estimation, particularly for diverse human bodies. To address this gap, we propose two loss functions that can be readily integrated into parametric 3D human reconstruction pipelines. Additionally, we propose a test-time optimization routine that further improves quality. Our method improves over the recent SHAPY method by 17.7% on the challenging SSP-3D dataset. We consider our work to be a step towards a more accurate 3D shape estimation system that works reliably on diverse body types and holds promise for practical applications in the fashion industry.
GPT4Rec: A Generative Framework for Personalized Recommendation and User Interests Interpretation
Apr 08, 2023Recent advancements in Natural Language Processing (NLP) have led to the development of NLP-based recommender systems that have shown superior performance. However, current models commonly treat items as mere IDs and adopt discriminative modeling, resulting in limitations of (1) fully leveraging the content information of items and the language modeling capabilities of NLP models; (2) interpreting user interests to improve relevance and diversity; and (3) adapting practical circumstances such as growing item inventories. To address these limitations, we present GPT4Rec, a novel and flexible generative framework inspired by search engines. It first generates hypothetical "search queries" given item titles in a user's history, and then retrieves items for recommendation by searching these queries. The framework overcomes previous limitations by learning both user and item embeddings in the language space. To well-capture user interests with different aspects and granularity for improving relevance and diversity, we propose a multi-query generation technique with beam search. The generated queries naturally serve as interpretable representations of user interests and can be searched to recommend cold-start items. With GPT-2 language model and BM25 search engine, our framework outperforms state-of-the-art methods by $75.7\%$ and $22.2\%$ in Recall@K on two public datasets. Experiments further revealed that multi-query generation with beam search improves both the diversity of retrieved items and the coverage of a user's multi-interests. The adaptiveness and interpretability of generated queries are discussed with qualitative case studies.
Asymmetric Face Recognition with Cross Model Compatible Ensembles
Mar 30, 2023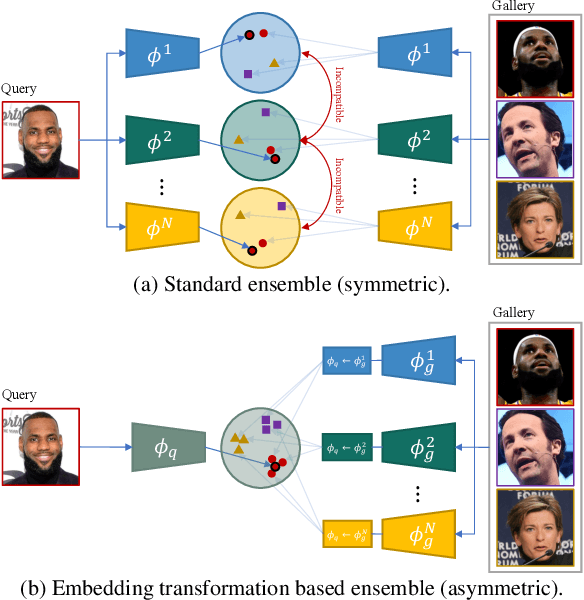
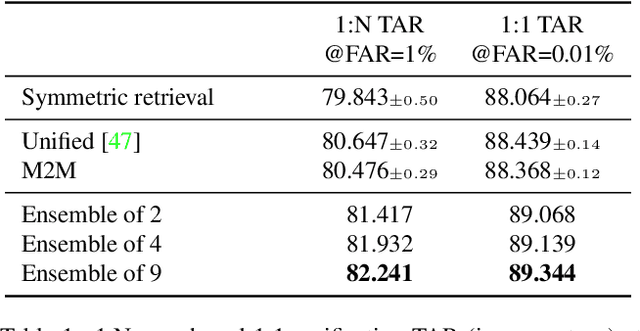
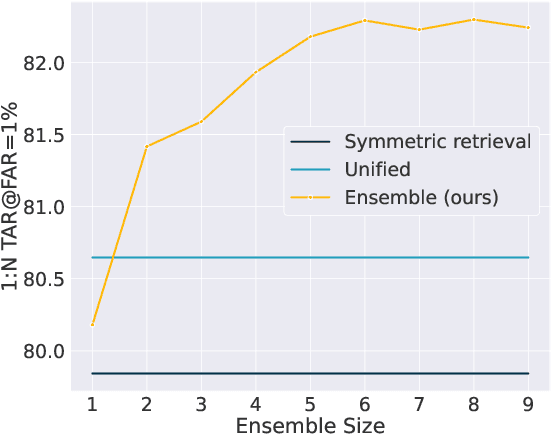

The asymmetrical retrieval setting is a well suited solution for resource constrained face recognition. In this setting a large model is used for indexing the gallery while a lightweight model is used for querying. The key principle in such systems is ensuring that both models share the same embedding space. Most methods in this domain are based on knowledge distillation. While useful, they suffer from several drawbacks: they are upper-bounded by the performance of the single best model found and cannot be extended to use an ensemble of models in a straightforward manner. In this paper we present an approach that does not rely on knowledge distillation, rather it utilizes embedding transformation models. This allows the use of N independently trained and diverse gallery models (e.g., trained on different datasets or having a different architecture) and a single query model. As a result, we improve the overall accuracy beyond that of any single model while maintaining a low computational budget for querying. Additionally, we propose a gallery image rejection method that utilizes the diversity between multiple transformed embeddings to estimate the uncertainty of gallery images.
Contrastive Learning for Interactive Recommendation in Fashion
Jul 25, 2022
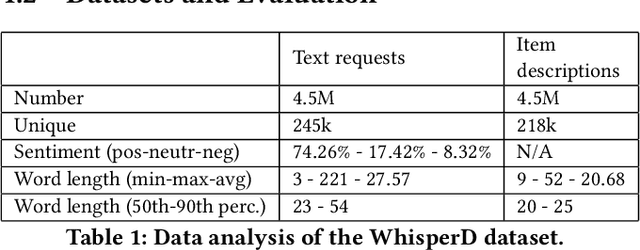
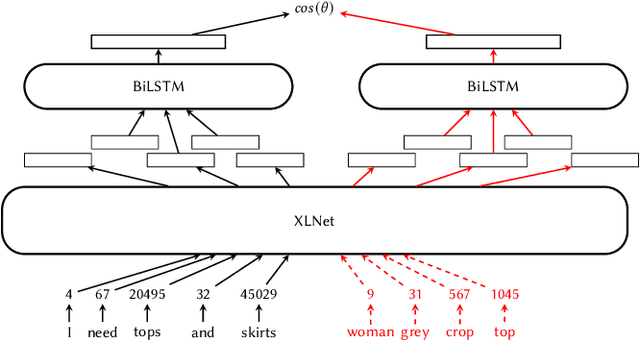
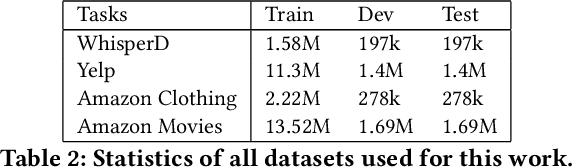
Recommender systems and search are both indispensable in facilitating personalization and ease of browsing in online fashion platforms. However, the two tools often operate independently, failing to combine the strengths of recommender systems to accurately capture user tastes with search systems' ability to process user queries. We propose a novel remedy to this problem by automatically recommending personalized fashion items based on a user-provided text request. Our proposed model, WhisperLite, uses contrastive learning to capture user intent from natural language text and improves the recommendation quality of fashion products. WhisperLite combines the strength of CLIP embeddings with additional neural network layers for personalization, and is trained using a composite loss function based on binary cross entropy and contrastive loss. The model demonstrates a significant improvement in offline recommendation retrieval metrics when tested on a real-world dataset collected from an online retail fashion store, as well as widely used open-source datasets in different e-commerce domains, such as restaurants, movies and TV shows, clothing and shoe reviews. We additionally conduct a user study that captures user judgements on the relevance of the model's recommended items, confirming the relevancy of WhisperLite's recommendations in an online setting.
Identity Preserving Loss for Learned Image Compression
Apr 27, 2022

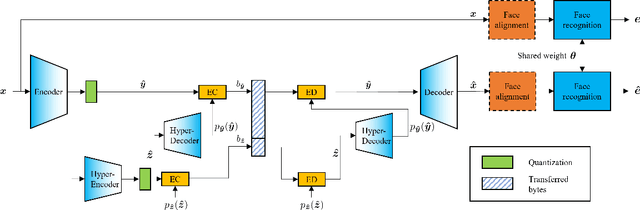

Deep learning model inference on embedded devices is challenging due to the limited availability of computation resources. A popular alternative is to perform model inference on the cloud, which requires transmitting images from the embedded device to the cloud. Image compression techniques are commonly employed in such cloud-based architectures to reduce transmission latency over low bandwidth networks. This work proposes an end-to-end image compression framework that learns domain-specific features to achieve higher compression ratios than standard HEVC/JPEG compression techniques while maintaining accuracy on downstream tasks (e.g., recognition). Our framework does not require fine-tuning of the downstream task, which allows us to drop-in any off-the-shelf downstream task model without retraining. We choose faces as an application domain due to the ready availability of datasets and off-the-shelf recognition models as representative downstream tasks. We present a novel Identity Preserving Reconstruction (IPR) loss function which achieves Bits-Per-Pixel (BPP) values that are ~38% and ~42% of CRF-23 HEVC compression for LFW (low-resolution) and CelebA-HQ (high-resolution) datasets, respectively, while maintaining parity in recognition accuracy. The superior compression ratio is achieved as the model learns to retain the domain-specific features (e.g., facial features) while sacrificing details in the background. Furthermore, images reconstructed by our proposed compression model are robust to changes in downstream model architectures. We show at-par recognition performance on the LFW dataset with an unseen recognition model while retaining a lower BPP value of ~38% of CRF-23 HEVC compression.
OutfitTransformer: Learning Outfit Representations for Fashion Recommendation
Apr 15, 2022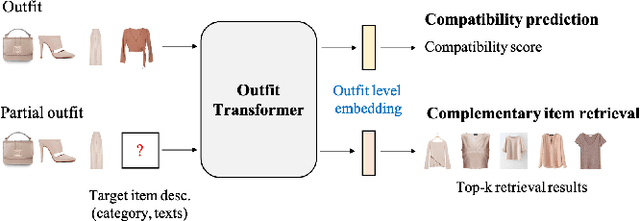

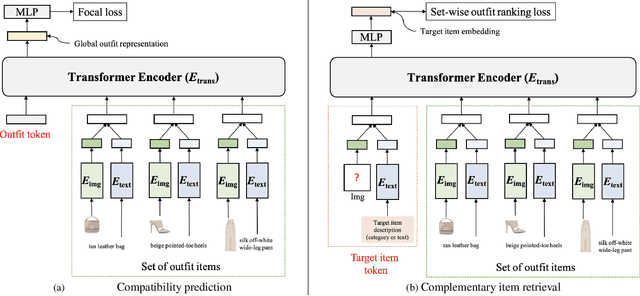
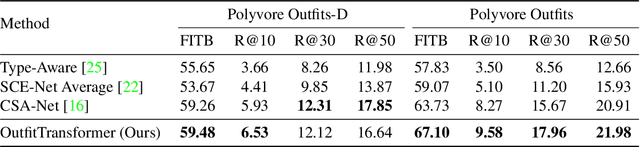
Learning an effective outfit-level representation is critical for predicting the compatibility of items in an outfit, and retrieving complementary items for a partial outfit. We present a framework, OutfitTransformer, that uses the proposed task-specific tokens and leverages the self-attention mechanism to learn effective outfit-level representations encoding the compatibility relationships between all items in the entire outfit for addressing both compatibility prediction and complementary item retrieval tasks. For compatibility prediction, we design an outfit token to capture a global outfit representation and train the framework using a classification loss. For complementary item retrieval, we design a target item token that additionally takes the target item specification (in the form of a category or text description) into consideration. We train our framework using a proposed set-wise outfit ranking loss to generate a target item embedding given an outfit, and a target item specification as inputs. The generated target item embedding is then used to retrieve compatible items that match the rest of the outfit. Additionally, we adopt a pre-training approach and a curriculum learning strategy to improve retrieval performance. Since our framework learns at an outfit-level, it allows us to learn a single embedding capturing higher-order relations among multiple items in the outfit more effectively than pairwise methods. Experiments demonstrate that our approach outperforms state-of-the-art methods on compatibility prediction, fill-in-the-blank, and complementary item retrieval tasks. We further validate the quality of our retrieval results with a user study.