 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Aware Reinforcement Learning for Output Diversity in Large Language Models
Nov 16, 2025Large Language Models (LLMs) often suffer from mode collapse, repeatedly generating the same few completions even when many valid answers exist, limiting their diversity across a wide range of tasks. We introduce Group-Aware Policy Optimization (GAPO), a simple extension of the recent and popular Group Relative Policy Optimization (GRPO) that computes rewards over the group as a whole. GAPO enables learning from the group-level properties such as diversity and coverage. We demonstrate GAPO using a frequency-aware reward function that encourages uniform sampling over valid LLM completions, and show that GAPO-trained models produce valid and more diverse model responses. Beyond this setup, GAPO generalizes to open-ended prompts and improves response diversity without compromising accuracy on standard LLM benchmarks (GSM8K, MATH, HumanEval, MMLU-Pro). Our code will be made publicly available.
FPGAN-Control: A Controllable Fingerprint Generator for Training with Synthetic Data
Oct 29, 2023


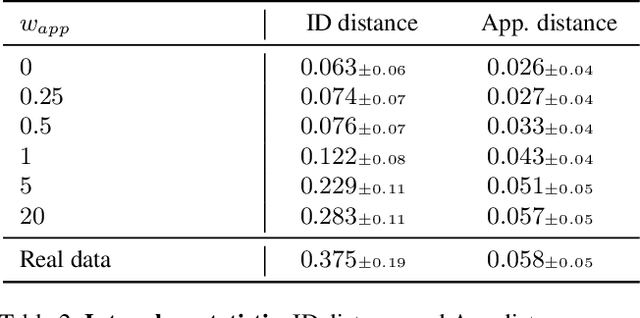
Training fingerprint recognition models using synthetic data has recently gained increased attention in the biometric community as it alleviates the dependency on sensitive personal data. Existing approaches for fingerprint generation are limited in their ability to generate diverse impressions of the same finger, a key property for providing effective data for training recognition models. To address this gap, we present FPGAN-Control, an identity preserving image generation framework which enables control over the fingerprint's image appearance (e.g., fingerprint type, acquisition device, pressure level) of generated fingerprints. We introduce a novel appearance loss that encourages disentanglement between the fingerprint's identity and appearance properties. In our experiments, we used the publicly available NIST SD302 (N2N) dataset for training the FPGAN-Control model. We demonstrate the merits of FPGAN-Control, both quantitatively and qualitatively, in terms of identity preservation level, degree of appearance control, and low synthetic-to-real domain gap. Finally, training recognition models using only synthetic datasets generated by FPGAN-Control lead to recognition accuracies that are on par or even surpass models trained using real data. To the best of our knowledge, this is the first work to demonstrate this.
Semantic Diversity Learning for Zero-Shot Multi-label Classification
May 12, 2021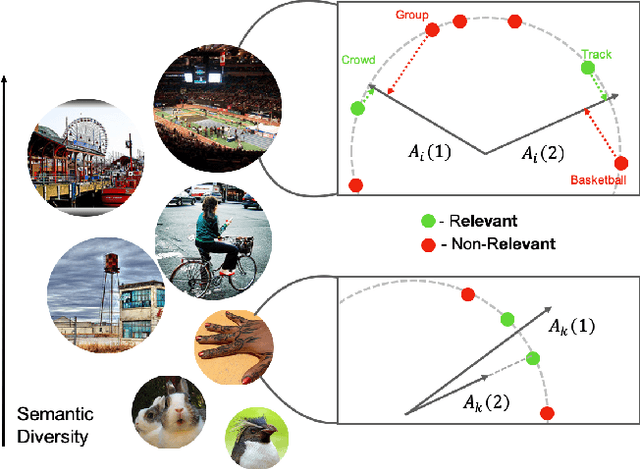
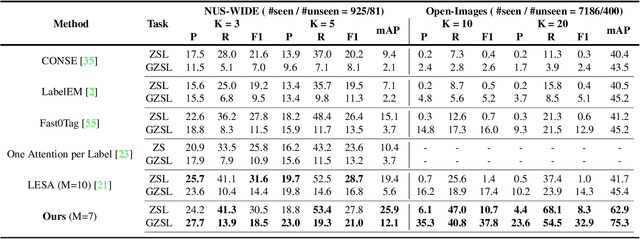
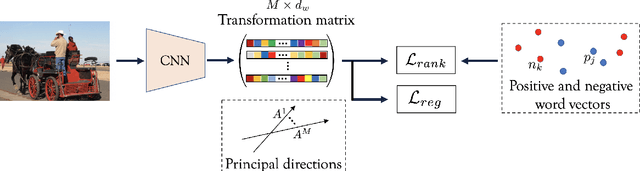
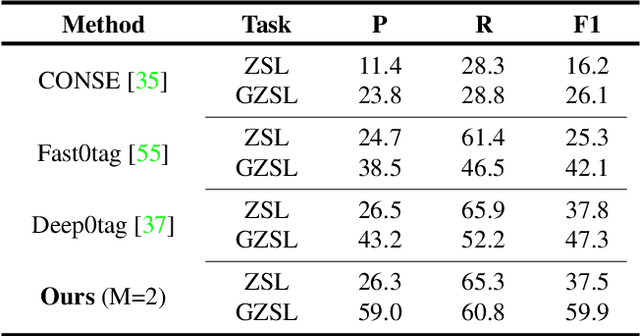
Training a neural network model for recognizing multiple labels associated with an image, including identifying unseen labels, is challenging, especially for images that portray numerous semantically diverse labels. As challenging as this task is, it is an essential task to tackle since it represents many real-world cases, such as image retrieval of natural images. We argue that using a single embedding vector to represent an image, as commonly practiced, is not sufficient to rank both relevant seen and unseen labels accurately. This study introduces an end-to-end model training for multi-label zero-shot learning that supports semantic diversity of the images and labels. We propose to use an embedding matrix having principal embedding vectors trained using a tailored loss function. In addition, during training, we suggest up-weighting in the loss function image samples presenting higher semantic diversity to encourage the diversity of the embedding matrix. Extensive experiments show that our proposed method improves the zero-shot model's quality in tag-based image retrieval achieving SoTA results on several common datasets (NUS-Wide, COCO, Open Images).