 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-Aware Reinforcement Learning for Output Diversity in Large Language Models
Nov 16, 2025Large Language Models (LLMs) often suffer from mode collapse, repeatedly generating the same few completions even when many valid answers exist, limiting their diversity across a wide range of tasks. We introduce Group-Aware Policy Optimization (GAPO), a simple extension of the recent and popular Group Relative Policy Optimization (GRPO) that computes rewards over the group as a whole. GAPO enables learning from the group-level properties such as diversity and coverage. We demonstrate GAPO using a frequency-aware reward function that encourages uniform sampling over valid LLM completions, and show that GAPO-trained models produce valid and more diverse model responses. Beyond this setup, GAPO generalizes to open-ended prompts and improves response diversity without compromising accuracy on standard LLM benchmarks (GSM8K, MATH, HumanEval, MMLU-Pro). Our code will be made publicly available.
LV-MAE: Learning Long Video Representations through Masked-Embedding Autoencoders
Apr 04, 2025In this work, we introduce long-video masked-embedding autoencoders (LV-MAE), a self-supervised learning framework for long video representation. Our approach treats short- and long-span dependencies as two separate tasks. Such decoupling allows for a more intuitive video processing where short-span spatiotemporal primitives are first encoded and are then used to capture long-range dependencies across consecutive video segments. To achieve this, we leverage advanced off-the-shelf multimodal encoders to extract representations from short segments within the long video, followed by pre-training a masked-embedding autoencoder capturing high-level interactions across segments. LV-MAE is highly efficient to train and enables the processing of much longer videos by alleviating the constraint on the number of input frames. Furthermore, unlike existing methods that typically pre-train on short-video datasets, our approach offers self-supervised pre-training using long video samples (e.g., 20+ minutes video clips) at scale. Using LV-MAE representations, we achieve state-of-the-art results on three long-video benchmarks -- LVU, COIN, and Breakfast -- employing only a simple classification head for either attentive or linear probing. Finally, to assess LV-MAE pre-training and visualize its reconstruction quality, we leverage the video-language aligned space of short video representations to monitor LV-MAE through video-text retrieval.
FPGAN-Control: A Controllable Fingerprint Generator for Training with Synthetic Data
Oct 29, 2023


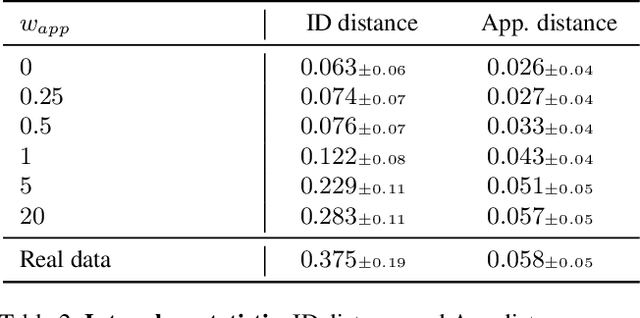
Training fingerprint recognition models using synthetic data has recently gained increased attention in the biometric community as it alleviates the dependency on sensitive personal data. Existing approaches for fingerprint generation are limited in their ability to generate diverse impressions of the same finger, a key property for providing effective data for training recognition models. To address this gap, we present FPGAN-Control, an identity preserving image generation framework which enables control over the fingerprint's image appearance (e.g., fingerprint type, acquisition device, pressure level) of generated fingerprints. We introduce a novel appearance loss that encourages disentanglement between the fingerprint's identity and appearance properties. In our experiments, we used the publicly available NIST SD302 (N2N) dataset for training the FPGAN-Control model. We demonstrate the merits of FPGAN-Control, both quantitatively and qualitatively, in terms of identity preservation level, degree of appearance control, and low synthetic-to-real domain gap. Finally, training recognition models using only synthetic datasets generated by FPGAN-Control lead to recognition accuracies that are on par or even surpass models trained using real data. To the best of our knowledge, this is the first work to demonstrate this.
Asymmetric Face Recognition with Cross Model Compatible Ensembles
Mar 30, 2023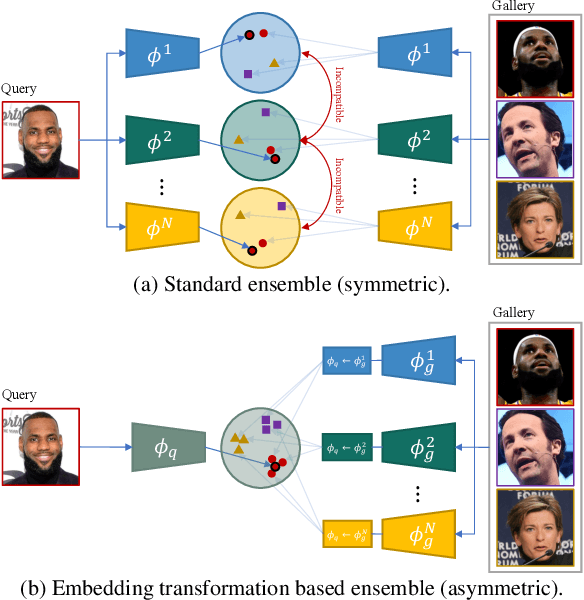
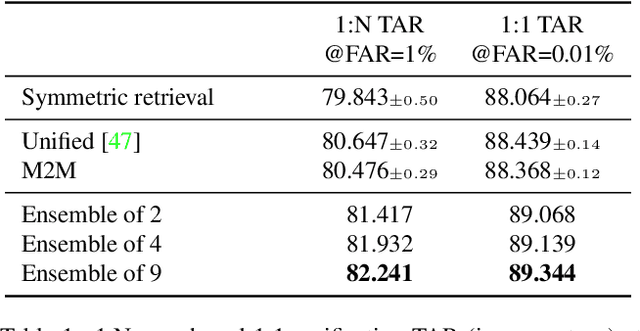
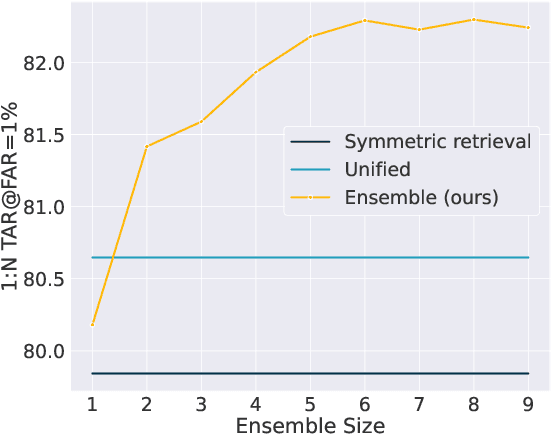

The asymmetrical retrieval setting is a well suited solution for resource constrained face recognition. In this setting a large model is used for indexing the gallery while a lightweight model is used for querying. The key principle in such systems is ensuring that both models share the same embedding space. Most methods in this domain are based on knowledge distillation. While useful, they suffer from several drawbacks: they are upper-bounded by the performance of the single best model found and cannot be extended to use an ensemble of models in a straightforward manner. In this paper we present an approach that does not rely on knowledge distillation, rather it utilizes embedding transformation models. This allows the use of N independently trained and diverse gallery models (e.g., trained on different datasets or having a different architecture) and a single query model. As a result, we improve the overall accuracy beyond that of any single model while maintaining a low computational budget for querying. Additionally, we propose a gallery image rejection method that utilizes the diversity between multiple transformed embeddings to estimate the uncertainty of gallery images.
Synthetic Data for Model Selection
May 03, 2021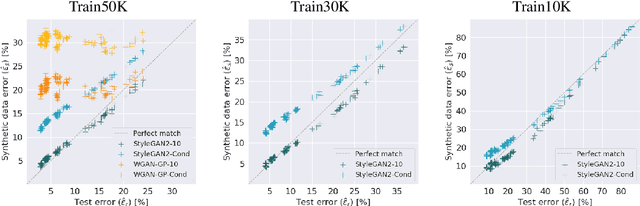

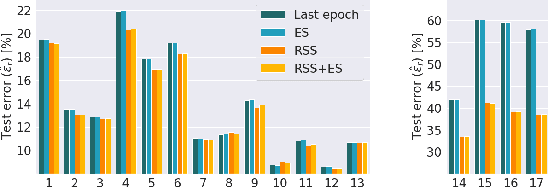

Recent improvements in synthetic data generation make it possible to produce images that are highly photorealistic and indistinguishable from real ones. Furthermore, synthetic generation pipelines have the potential to generate an unlimited number of images. The combination of high photorealism and scale turn the synthetic data into a promising candidate for potentially improving various machine learning (ML) pipelines. Thus far, a large body of research in this field has focused on using synthetic images for training, by augmenting and enlarging training data. In contrast to using synthetic data for training, in this work we explore whether synthetic data can be beneficial for model selection. Considering the task of image classification, we demonstrate that when data is scarce, synthetic data can be used to replace the held out validation set, thus allowing to train on a larger dataset.
GAN-Control: Explicitly Controllable GANs
Jan 07, 2021


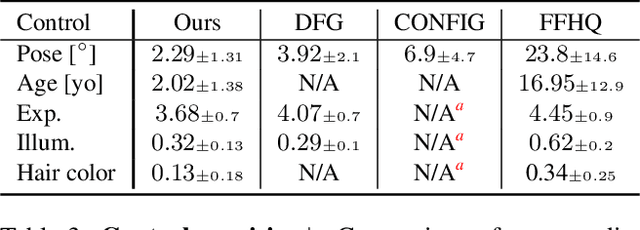
We present a framework for training GANs with explicit control over generated images. We are able to control the generated image by settings exact attributes such as age, pose, expression, etc. Most approaches for editing GAN-generated images achieve partial control by leveraging the latent space disentanglement properties, obtained implicitly after standard GAN training. Such methods are able to change the relative intensity of certain attributes, but not explicitly set their values. Recently proposed methods, designed for explicit control over human faces, harness morphable 3D face models to allow fine-grained control capabilities in GANs. Unlike these methods, our control is not constrained to morphable 3D face model parameters and is extendable beyond the domain of human faces. Using contrastive learning, we obtain GANs with an explicitly disentangled latent space. This disentanglement is utilized to train control-encoders mapping human-interpretable inputs to suitable latent vectors, thus allowing explicit control. In the domain of human faces we demonstrate control over identity, age, pose, expression, hair color and illumination. We also demonstrate control capabilities of our framework in the domains of painted portraits and dog image generation. We demonstrate that our approach achieves state-of-the-art performance both qualitatively and quantitatively.
Dynamic-Net: Tuning the Objective Without Re-training
Nov 21, 2018
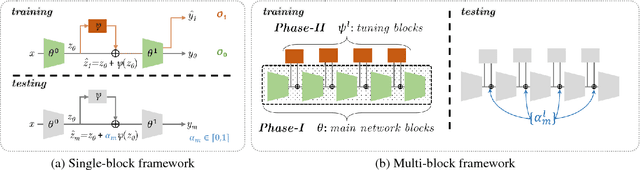


One of the key ingredients for successful optimization of modern CNNs is identifying a suitable objective. To date, the objective is fixed a-priori at training time, and any variation to it requires re-training a new network. In this paper we present a first attempt at alleviating the need for re-training. Rather than fixing the network at training time, we train a "Dynamic-Net" that can be modified at inference time. Our approach considers an "objective-space" as the space of all linear combinations of two objectives, and the Dynamic-Net can traverse this objective-space at test-time, without any further training. We show that this upgrades pre-trained networks by providing an out-of-learning extension, while maintaining the performance quality. The solution we propose is fast and allows a user to interactively modify the network, in real-time, in order to obtain the result he/she desires. We show the benefits of such an approach via several different applications.
Adversarial Feedback Loop
Nov 20, 2018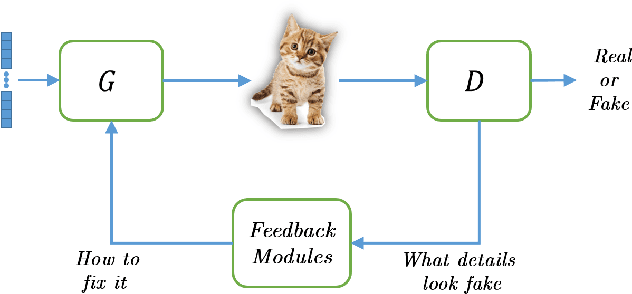
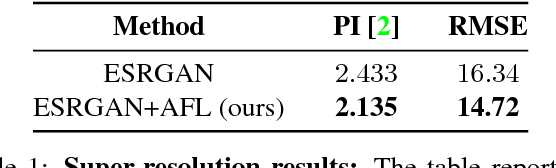

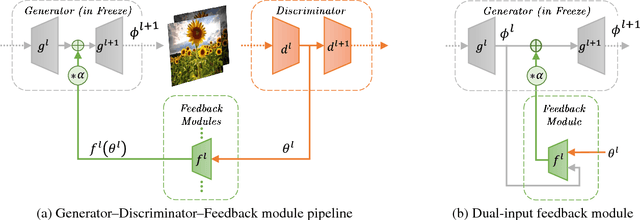
Thanks to their remarkable generative capabilities, GANs have gained great popularity, and are used abundantly in state-of-the-art methods and applications. In a GAN based model, a discriminator is trained to learn the real data distribution. To date, it has been used only for training purposes, where it's utilized to train the generator to provide real-looking outputs. In this paper we propose a novel method that makes an explicit use of the discriminator in test-time, in a feedback manner in order to improve the generator results. To the best of our knowledge it is the first time a discriminator is involved in test-time. We claim that the discriminator holds significant information on the real data distribution, that could be useful for test-time as well, a potential that has not been explored before. The approach we propose does not alter the conventional training stage. At test-time, however, it transfers the output from the generator into the discriminator, and uses feedback modules (convolutional blocks) to translate the features of the discriminator layers into corrections to the features of the generator layers, which are used eventually to get a better generator result. Our method can contribute to both conditional and unconditional GANs. As demonstrated by our experiments, it can improve the results of state-of-the-art networks for super-resolution, and image generation.