 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Dynamic Networks for Covariate Shift Robustness
Jun 06, 2020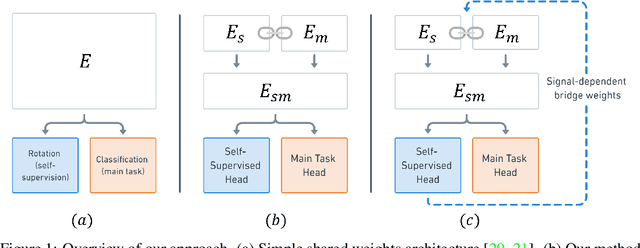

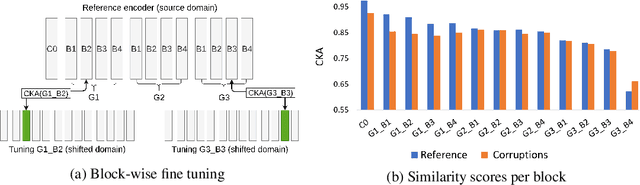
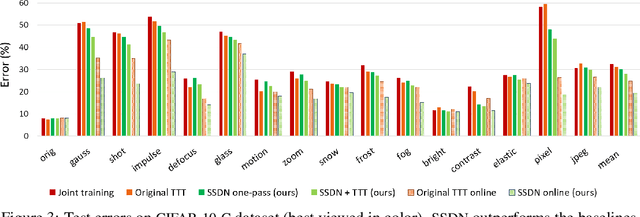
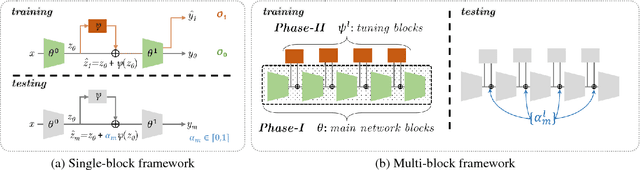
As supervised learning still dominates most AI applications, test-time performance is often unexpected. Specifically, a shift of the input covariates, caused by typical nuisances like background-noise, illumination variations or transcription errors, can lead to a significant decrease in prediction accuracy. Recently, it was shown that incorporating self-supervision can significantly improve covariate shift robustness. In this work, we propose Self-Supervised Dynamic Networks (SSDN): an input-dependent mechanism, inspired by dynamic networks, that allows a self-supervised network to predict the weights of the main network, and thus directly handle covariate shifts at test-time. We present the conceptual and empirical advantages of the proposed method on the problem of image classification under different covariate shifts, and show that it significantly outperforms comparable methods.
Dynamic-Net: Tuning the Objective Without Re-training
Nov 21, 2018


One of the key ingredients for successful optimization of modern CNNs is identifying a suitable objective. To date, the objective is fixed a-priori at training time, and any variation to it requires re-training a new network. In this paper we present a first attempt at alleviating the need for re-training. Rather than fixing the network at training time, we train a "Dynamic-Net" that can be modified at inference time. Our approach considers an "objective-space" as the space of all linear combinations of two objectives, and the Dynamic-Net can traverse this objective-space at test-time, without any further training. We show that this upgrades pre-trained networks by providing an out-of-learning extension, while maintaining the performance quality. The solution we propose is fast and allows a user to interactively modify the network, in real-time, in order to obtain the result he/she desires. We show the benefits of such an approach via several different applications.
Adversarial Feedback Loop
Nov 20, 2018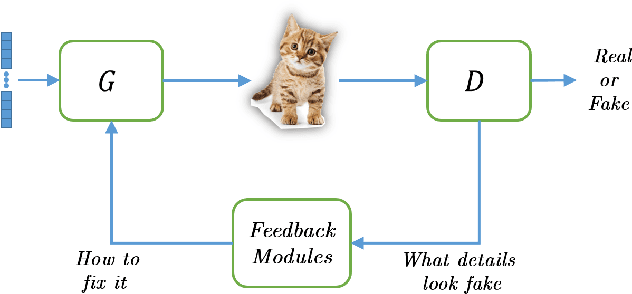
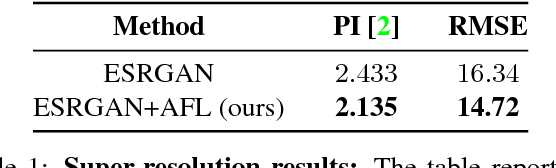

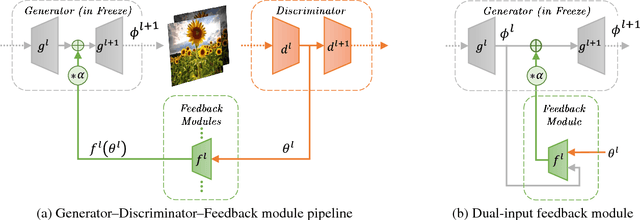
Thanks to their remarkable generative capabilities, GANs have gained great popularity, and are used abundantly in state-of-the-art methods and applications. In a GAN based model, a discriminator is trained to learn the real data distribution. To date, it has been used only for training purposes, where it's utilized to train the generator to provide real-looking outputs. In this paper we propose a novel method that makes an explicit use of the discriminator in test-time, in a feedback manner in order to improve the generator results. To the best of our knowledge it is the first time a discriminator is involved in test-time. We claim that the discriminator holds significant information on the real data distribution, that could be useful for test-time as well, a potential that has not been explored before. The approach we propose does not alter the conventional training stage. At test-time, however, it transfers the output from the generator into the discriminator, and uses feedback modules (convolutional blocks) to translate the features of the discriminator layers into corrections to the features of the generator layers, which are used eventually to get a better generator result. Our method can contribute to both conditional and unconditional GANs. As demonstrated by our experiments, it can improve the results of state-of-the-art networks for super-resolution, and image generation.
Improving CNN Training using Disentanglement for Liver Lesion Classification in CT
Nov 01, 2018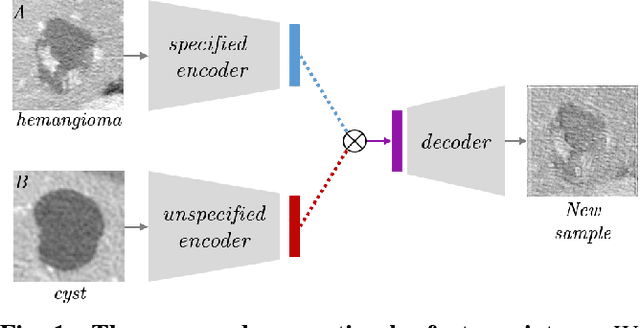
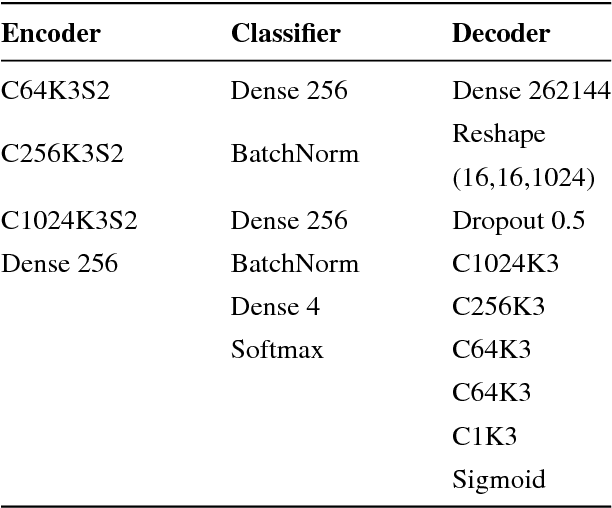
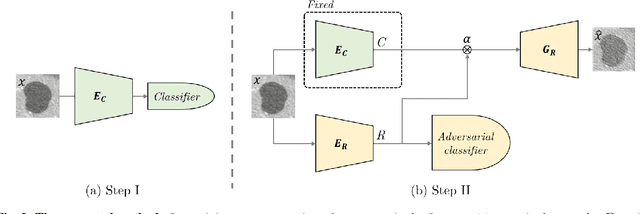
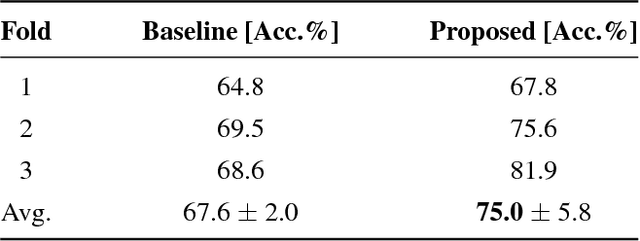
Training data is the key component in designing algorithms for medical image analysis and in many cases it is the main bottleneck in achieving good results. Recent progress in image generation has enabled the training of neural network based solutions using synthetic data. A key factor in the generation of new samples is controlling the important appearance features and potentially being able to generate a new sample of a specific class with different variants. In this work we suggest the synthesis of new data by mixing the class specified and unspecified representation of different factors in the training data. Our experiments on liver lesion classification in CT show an average improvement of 7.4% in accuracy over the baseline training scheme.
2018 PIRM Challenge on Perceptual Image Super-resolution
Oct 03, 2018
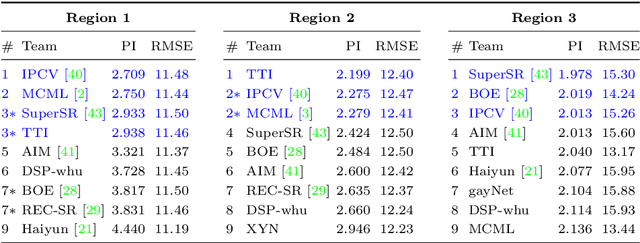
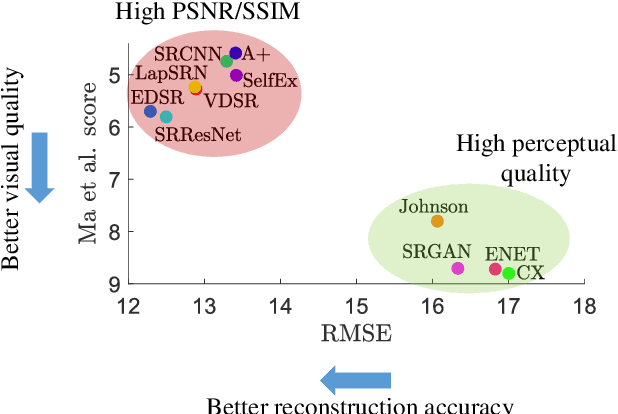

This paper reports on the 2018 PIRM challenge on perceptual super-resolution (SR), held in conjunction with the Perceptual Image Restoration and Manipulation (PIRM) workshop at ECCV 2018. In contrast to previous SR challenges, our evaluation methodology jointly quantifies accuracy and perceptual quality, therefore enabling perceptual-driven methods to compete alongside algorithms that target PSNR maximization. Twenty-one participating teams introduced algorithms which well-improved upon the existing state-of-the-art methods in perceptual SR, as confirmed by a human opinion study. We also analyze popular image quality measures and draw conclusions regarding which of them correlates best with human opinion scores. We conclude with an analysis of the current trends in perceptual SR, as reflected from the leading submissions.
Maintaining Natural Image Statistics with the Contextual Loss
Jul 18, 2018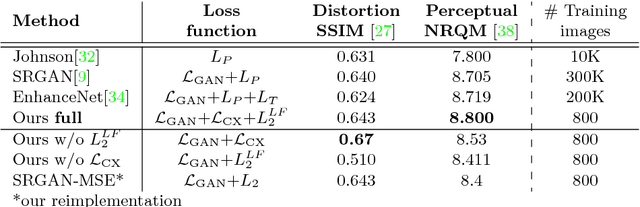
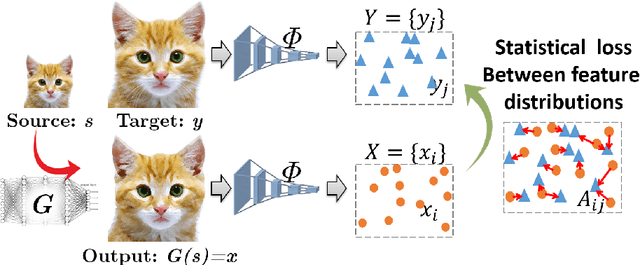
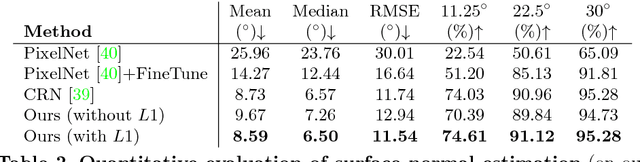
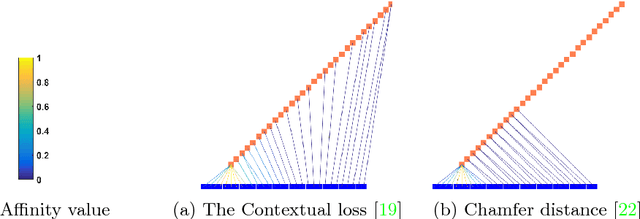
Maintaining natural image statistics is a crucial factor in restoration and generation of realistic looking images. When training CNNs, photorealism is usually attempted by adversarial training (GAN), that pushes the output images to lie on the manifold of natural images. GANs are very powerful, but not perfect. They are hard to train and the results still often suffer from artifacts. In this paper we propose a complementary approach, that could be applied with or without GAN, whose goal is to train a feed-forward CNN to maintain natural internal statistics. We look explicitly at the distribution of features in an image and train the network to generate images with natural feature distributions. Our approach reduces by orders of magnitude the number of images required for training and achieves state-of-the-art results on both single-image super-resolution, and high-resolution surface normal estimation.
The Contextual Loss for Image Transformation with Non-Aligned Data
Jul 18, 2018

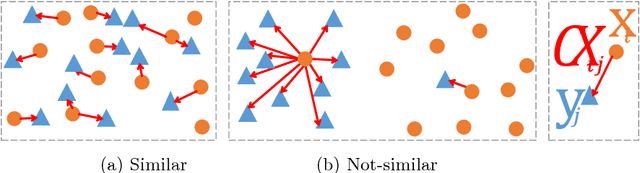

Feed-forward CNNs trained for image transformation problems rely on loss functions that measure the similarity between the generated image and a target image. Most of the common loss functions assume that these images are spatially aligned and compare pixels at corresponding locations. However, for many tasks, aligned training pairs of images will not be available. We present an alternative loss function that does not require alignment, thus providing an effective and simple solution for a new space of problems. Our loss is based on both context and semantics -- it compares regions with similar semantic meaning, while considering the context of the entire image. Hence, for example, when transferring the style of one face to another, it will translate eyes-to-eyes and mouth-to-mouth. Our code can be found at https://www.github.com/roimehrez/contextualLoss
Saliency Driven Image Manipulation
Jan 17, 2018
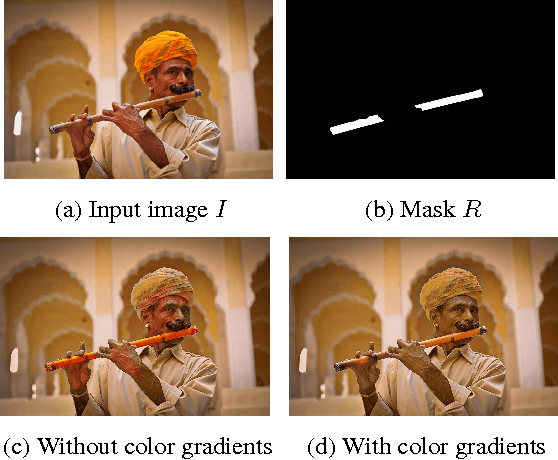
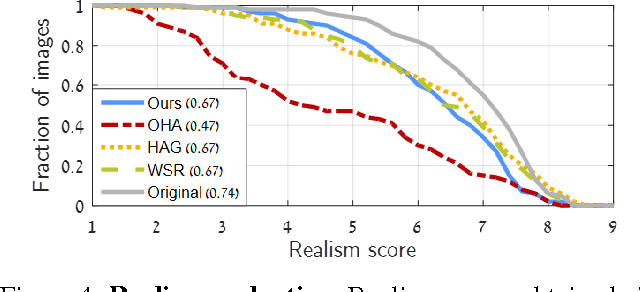
Have you ever taken a picture only to find out that an unimportant background object ended up being overly salient? Or one of those team sports photos where your favorite player blends with the rest? Wouldn't it be nice if you could tweak these pictures just a little bit so that the distractor would be attenuated and your favorite player will stand-out among her peers? Manipulating images in order to control the saliency of objects is the goal of this paper. We propose an approach that considers the internal color and saliency properties of the image. It changes the saliency map via an optimization framework that relies on patch-based manipulation using only patches from within the same image to achieve realistic looking results. Applications include object enhancement, distractors attenuation and background decluttering. Comparing our method to previous ones shows significant improvement, both in the achieved saliency manipulation and in the realistic appearance of the resulting images.
Photorealistic Style Transfer with Screened Poisson Equation
Sep 28, 2017
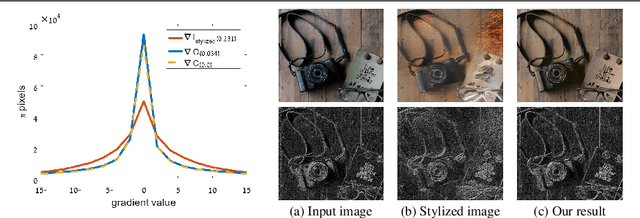


Recent work has shown impressive success in transferring painterly style to images. These approaches, however, fall short of photorealistic style transfer. Even when both the input and reference images are photographs, the output still exhibits distortions reminiscent of a painting. In this paper we propose an approach that takes as input a stylized image and makes it more photorealistic. It relies on the Screened Poisson Equation, maintaining the fidelity of the stylized image while constraining the gradients to those of the original input image. Our method is fast, simple, fully automatic and shows positive progress in making a stylized image photorealistic. Our results exhibit finer details and are less prone to artifacts than the state-of-the-art.
Template Matching with Deformable Diversity Similarity
Apr 18, 2017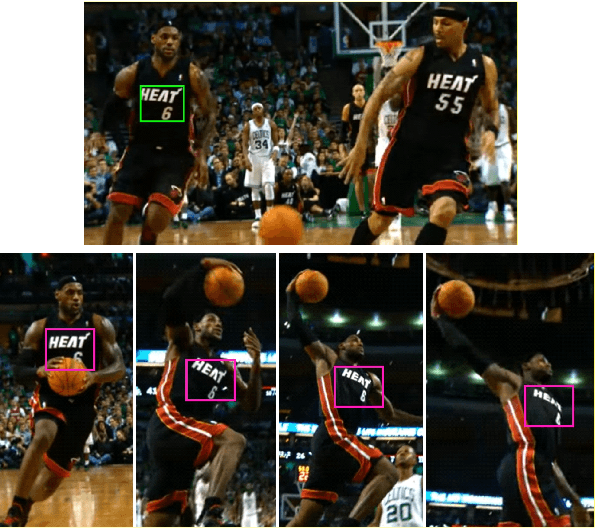
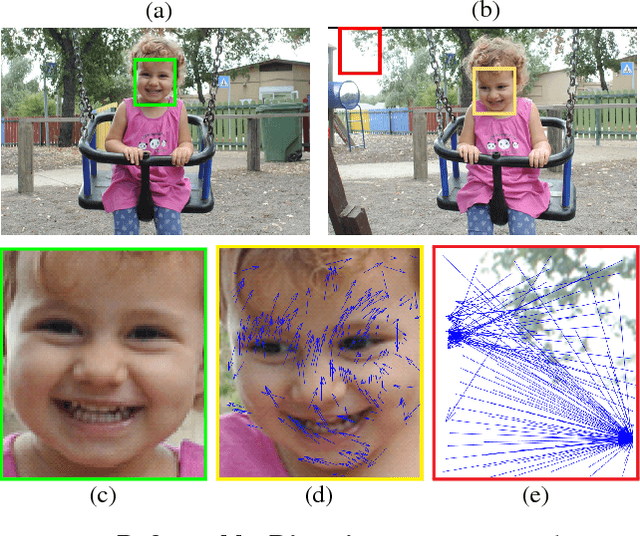
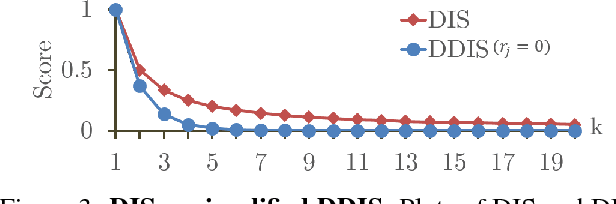
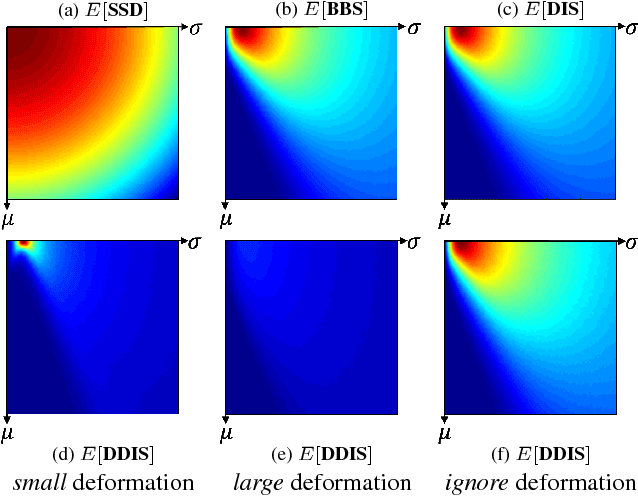
We propose a novel measure for template matching named Deformable Diversity Similarity -- based on the diversity of feature matches between a target image window and the template. We rely on both local appearance and geometric information that jointly lead to a powerful approach for matching. Our key contribution is a similarity measure, that is robust to complex deformations, significant background clutter, and occlusions. Empirical evaluation on the most up-to-date benchmark shows that our method outperforms the current state-of-the-art in its detection accuracy while improving computational complexity.