 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Reverberation and Dereverberation using an Acoustic Multiple-Input Multiple-Output System
Jan 07, 2024Methods are proposed for modifying the reverberation characteristics of sound fields in rooms by employing a loudspeaker with adjustable directivity, realized with a compact spherical loudspeaker array (SLA). These methods are based on minimization and maximization of clarity and direct-to-reverberant sound ratio. Significant modification of reverberation is achieved by these methods, as shown in simulation studies. The system under investigation includes a spherical microphone array and an SLA comprising a multiple-input multiple-output system. The robustness of these methods to system identification errors is also investigated. Finally, reverberation and dereverberation results are validated by a listening experiment.
Theory and investigation of acoustic multiple-input multiple-output systems based on spherical arrays in a room
Jan 07, 2024Spatial attributes of room acoustics have been widely studied using microphone and loudspeaker arrays. However, systems that combine both arrays, referred to as multiple-input multiple-output (MIMO) systems, have only been studied to a limited degree in this context. These systems can potentially provide a powerful tool for room acoustics analysis due to the ability to simultaneously control both arrays. This paper offers a theoretical framework for the spatial analysis of enclosed sound fields using a MIMO system comprising spherical loudspeaker and microphone arrays. A system transfer function is formulated in matrix form for free-field conditions, and its properties are studied using tools from linear algebra. The system is shown to have unit-rank, regardless of the array types, and its singular vectors are related to the directions of arrival and radiation at the microphone and loudspeaker arrays, respectively. The formulation is then generalized to apply to rooms, using an image source method. In this case, the rank of the system is related to the number of significant reflections. The paper ends with simulation studies, which support the developed theory, and with an extensive reflection analysis of a room impulse response, using the platform of a MIMO system.
Modal smoothing for analysis of room reflections measured with spherical microphone and loudspeaker arrays
Jan 07, 2024Spatial analysis of room acoustics is an ongoing research topic. Microphone arrays have been employed for spatial analyses with an important objective being the estimation of the direction-of-arrival (DOA) of direct sound and early room reflections using room impulse responses (RIRs). An optimal method for DOA estimation is the multiple signal classification algorithm. When RIRs are considered, this method typically fails due to the correlation of room reflections, which leads to rank deficiency of the cross-spectrum matrix. Preprocessing methods for rank restoration, which may involve averaging over frequency, for example, have been proposed exclusively for spherical arrays. However, these methods fail in the case of reflections with equal time delays, which may arise in practice and could be of interest. In this paper, a method is proposed for systems that combine a spherical microphone array and a spherical loudspeaker array, referred to as multiple-input multiple-output systems. This method, referred to as modal smoothing, exploits the additional spatial diversity for rank restoration and succeeds where previous methods fail, as demonstrated in a simulation study. Finally, combining modal smoothing with a preprocessing method is proposed in order to increase the number of DOAs that can be estimated using low-order spherical loudspeaker arrays.
Design framework for spherical microphone and loudspeaker arrays in a multiple-input multiple-output system
Jan 06, 2024Spherical microphone arrays (SMAs) and spherical loudspeaker arrays (SLAs) facilitate the study of room acoustics due to the three-dimensional analysis they provide. More recently, systems that combine both arrays, referred to as multiple-input multiple-output (MIMO) systems, have been proposed due to the added spatial diversity they facilitate. The literature provides frameworks for designing SMAs and SLAs separately, including error analysis from which the operating frequency range (OFR) of an array is defined. However, such a framework does not exist for the joint design of a SMA and a SLA that comprise a MIMO system. This paper develops a design framework for MIMO systems based on a model that addresses errors and highlights the importance of a matched design. Expanding on a free-field assumption, errors are incorporated separately for each array and error bounds are defined, facilitating error analysis for the system. The dependency of the error bounds on the SLA and SMA parameters is studied and it is recommended that parameters should be chosen to assure matched OFRs of the arrays in MIMO system design. A design example is provided, demonstrating the superiority of a matched system over an unmatched system in the synthesis of directional room impulse responses.
Decentralized Low-Latency Collaborative Inference via Ensembles on the Edge
Jun 07, 2022



The success of deep neural networks (DNNs) is heavily dependent on computational resources. While DNNs are often employed on cloud servers, there is a growing need to operate DNNs on edge devices. Edge devices are typically limited in their computational resources, yet, often multiple edge devices are deployed in the same environment and can reliably communicate with each other. In this work we propose to facilitate the application of DNNs on the edge by allowing multiple users to collaborate during inference to improve their accuracy. Our mechanism, coined {\em edge ensembles}, is based on having diverse predictors at each device, which form an ensemble of models during inference. To mitigate the communication overhead, the users share quantized features, and we propose a method for aggregating multiple decisions into a single inference rule. We analyze the latency induced by edge ensembles, showing that its performance improvement comes at the cost of a minor additional delay under common assumptions on the communication network. Our experiments demonstrate that collaborative inference via edge ensembles equipped with compact DNNs substantially improves the accuracy over having each user infer locally, and can outperform using a single centralized DNN larger than all the networks in the ensemble together.
Self-Supervised Dynamic Networks for Covariate Shift Robustness
Jun 06, 2020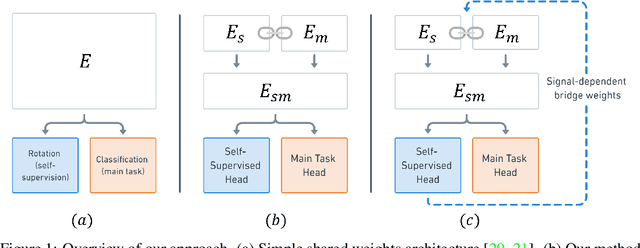

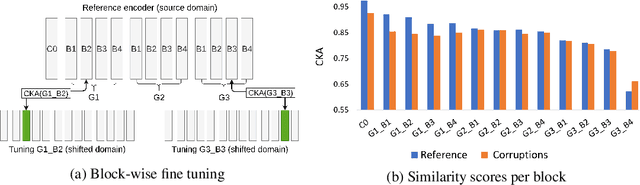
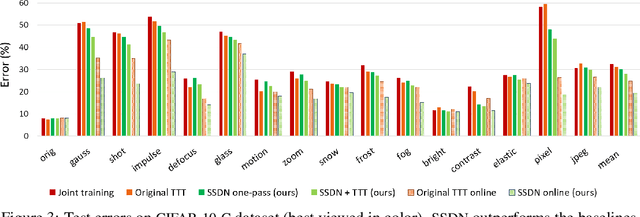
As supervised learning still dominates most AI applications, test-time performance is often unexpected. Specifically, a shift of the input covariates, caused by typical nuisances like background-noise, illumination variations or transcription errors, can lead to a significant decrease in prediction accuracy. Recently, it was shown that incorporating self-supervision can significantly improve covariate shift robustness. In this work, we propose Self-Supervised Dynamic Networks (SSDN): an input-dependent mechanism, inspired by dynamic networks, that allows a self-supervised network to predict the weights of the main network, and thus directly handle covariate shifts at test-time. We present the conceptual and empirical advantages of the proposed method on the problem of image classification under different covariate shifts, and show that it significantly outperforms comparable methods.