 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaintaining Natural Image Statistics with the Contextual Loss
Jul 18, 2018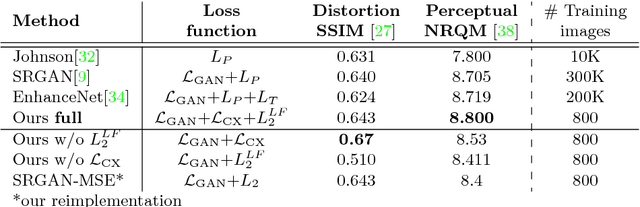
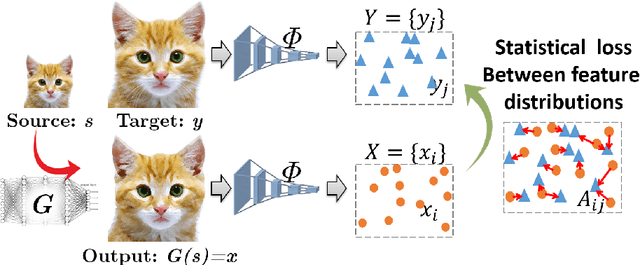
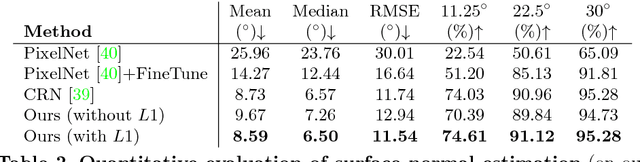
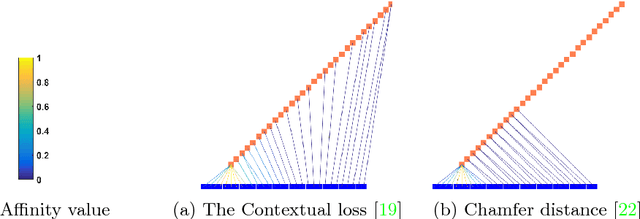
Maintaining natural image statistics is a crucial factor in restoration and generation of realistic looking images. When training CNNs, photorealism is usually attempted by adversarial training (GAN), that pushes the output images to lie on the manifold of natural images. GANs are very powerful, but not perfect. They are hard to train and the results still often suffer from artifacts. In this paper we propose a complementary approach, that could be applied with or without GAN, whose goal is to train a feed-forward CNN to maintain natural internal statistics. We look explicitly at the distribution of features in an image and train the network to generate images with natural feature distributions. Our approach reduces by orders of magnitude the number of images required for training and achieves state-of-the-art results on both single-image super-resolution, and high-resolution surface normal estimation.
The Contextual Loss for Image Transformation with Non-Aligned Data
Jul 18, 2018


Feed-forward CNNs trained for image transformation problems rely on loss functions that measure the similarity between the generated image and a target image. Most of the common loss functions assume that these images are spatially aligned and compare pixels at corresponding locations. However, for many tasks, aligned training pairs of images will not be available. We present an alternative loss function that does not require alignment, thus providing an effective and simple solution for a new space of problems. Our loss is based on both context and semantics -- it compares regions with similar semantic meaning, while considering the context of the entire image. Hence, for example, when transferring the style of one face to another, it will translate eyes-to-eyes and mouth-to-mouth. Our code can be found at https://www.github.com/roimehrez/contextualLoss
Template Matching with Deformable Diversity Similarity
Apr 18, 2017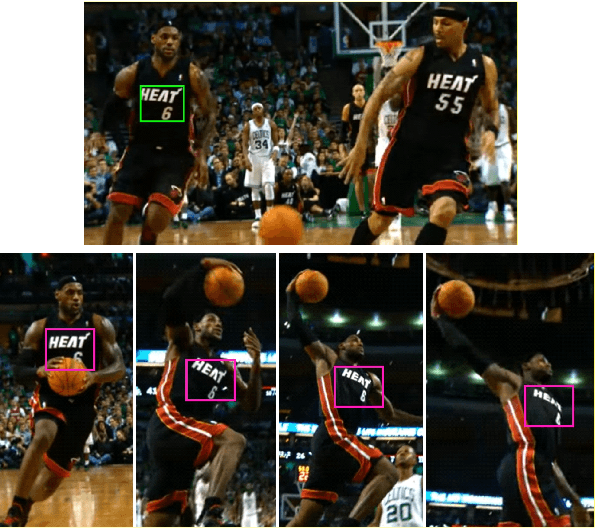
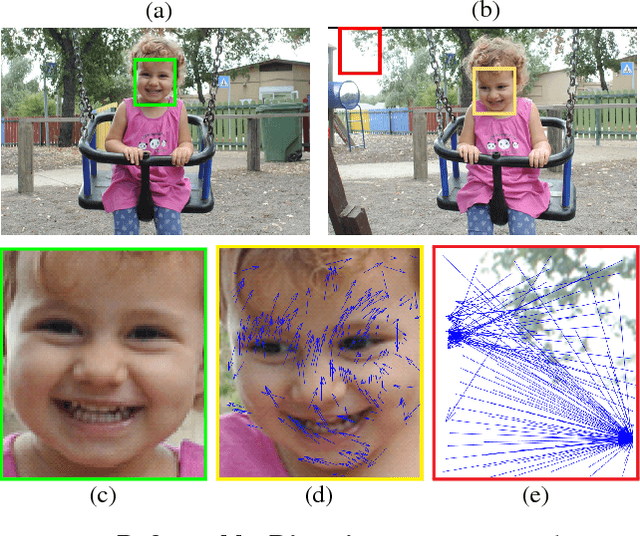
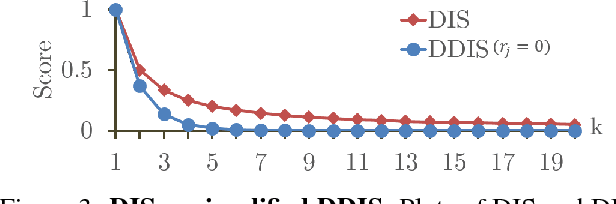
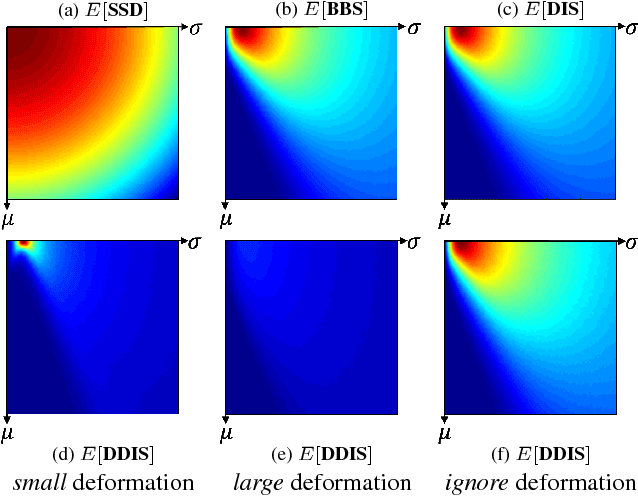
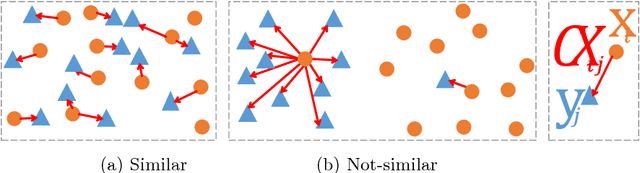
We propose a novel measure for template matching named Deformable Diversity Similarity -- based on the diversity of feature matches between a target image window and the template. We rely on both local appearance and geometric information that jointly lead to a powerful approach for matching. Our key contribution is a similarity measure, that is robust to complex deformations, significant background clutter, and occlusions. Empirical evaluation on the most up-to-date benchmark shows that our method outperforms the current state-of-the-art in its detection accuracy while improving computational complexity.