 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-VLM: Multimodal Video Scene Segmentation via Vision-Language Models
Dec 25, 2025



Segmenting long-form videos into semantically coherent scenes is a fundamental task in large-scale video understanding. Existing encoder-based methods are limited by visual-centric biases, classify each shot in isolation without leveraging sequential dependencies, and lack both narrative understanding and explainability. In this paper, we present Scene-VLM, the first fine-tuned vision-language model (VLM) framework for video scene segmentation. Scene-VLM jointly processes visual and textual cues including frames, transcriptions, and optional metadata to enable multimodal reasoning across consecutive shots. The model generates predictions sequentially with causal dependencies among shots and introduces a context-focus window mechanism to ensure sufficient temporal context for each shot-level decision. In addition, we propose a scheme to extract confidence scores from the token-level logits of the VLM, enabling controllable precision-recall trade-offs that were previously limited to encoder-based methods. Furthermore, we demonstrate that our model can be aligned to generate coherent natural-language rationales for its boundary decisions through minimal targeted supervision. Our approach achieves state-of-the-art performance on standard scene segmentation benchmarks. On MovieNet, for example, Scene-VLM yields significant improvements of +6 AP and +13.7 F1 over the previous leading method.
LV-MAE: Learning Long Video Representations through Masked-Embedding Autoencoders
Apr 04, 2025In this work, we introduce long-video masked-embedding autoencoders (LV-MAE), a self-supervised learning framework for long video representation. Our approach treats short- and long-span dependencies as two separate tasks. Such decoupling allows for a more intuitive video processing where short-span spatiotemporal primitives are first encoded and are then used to capture long-range dependencies across consecutive video segments. To achieve this, we leverage advanced off-the-shelf multimodal encoders to extract representations from short segments within the long video, followed by pre-training a masked-embedding autoencoder capturing high-level interactions across segments. LV-MAE is highly efficient to train and enables the processing of much longer videos by alleviating the constraint on the number of input frames. Furthermore, unlike existing methods that typically pre-train on short-video datasets, our approach offers self-supervised pre-training using long video samples (e.g., 20+ minutes video clips) at scale. Using LV-MAE representations, we achieve state-of-the-art results on three long-video benchmarks -- LVU, COIN, and Breakfast -- employing only a simple classification head for either attentive or linear probing. Finally, to assess LV-MAE pre-training and visualize its reconstruction quality, we leverage the video-language aligned space of short video representations to monitor LV-MAE through video-text retrieval.
Distilling the Knowledge in Data Pruning
Mar 12, 2024



With the increasing size of datasets used for training neural networks, data pruning becomes an attractive field of research. However, most current data pruning algorithms are limited in their ability to preserve accuracy compared to models trained on the full data, especially in high pruning regimes. In this paper we explore the application of data pruning while incorporating knowledge distillation (KD) when training on a pruned subset. That is, rather than relying solely on ground-truth labels, we also use the soft predictions from a teacher network pre-trained on the complete data. By integrating KD into training, we demonstrate significant improvement across datasets, pruning methods, and on all pruning fractions. We first establish a theoretical motivation for employing self-distillation to improve training on pruned data. Then, we empirically make a compelling and highly practical observation: using KD, simple random pruning is comparable or superior to sophisticated pruning methods across all pruning regimes. On ImageNet for example, we achieve superior accuracy despite training on a random subset of only 50% of the data. Additionally, we demonstrate a crucial connection between the pruning factor and the optimal knowledge distillation weight. This helps mitigate the impact of samples with noisy labels and low-quality images retained by typical pruning algorithms. Finally, we make an intriguing observation: when using lower pruning fractions, larger teachers lead to accuracy degradation, while surprisingly, employing teachers with a smaller capacity than the student's may improve results. Our code will be made available.
Solving ImageNet: a Unified Scheme for Training any Backbone to Top Results
Apr 07, 2022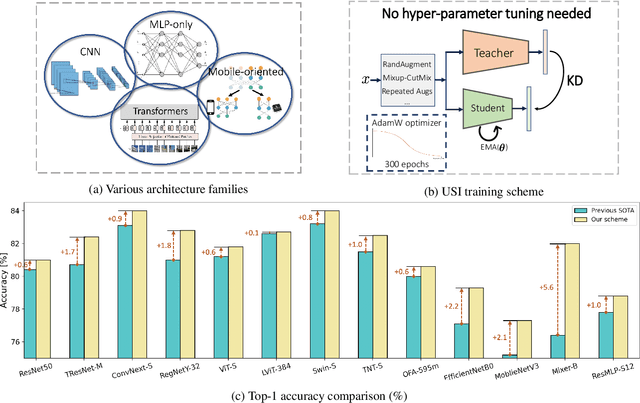
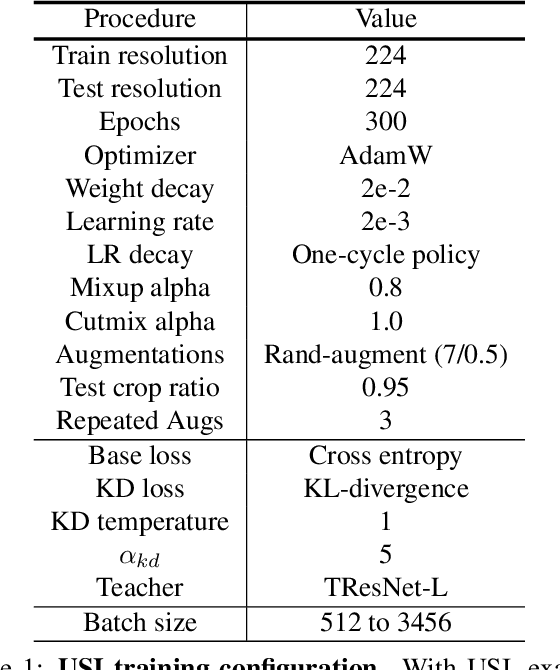
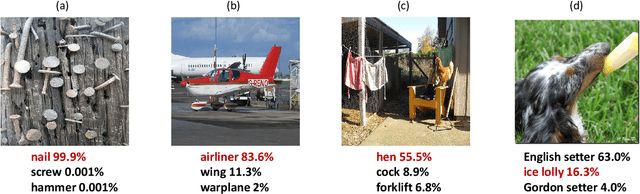
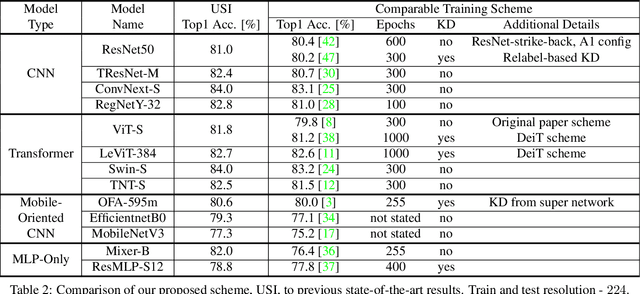
ImageNet serves as the primary dataset for evaluating the quality of computer-vision models. The common practice today is training each architecture with a tailor-made scheme, designed and tuned by an expert. In this paper, we present a unified scheme for training any backbone on ImageNet. The scheme, named USI (Unified Scheme for ImageNet), is based on knowledge distillation and modern tricks. It requires no adjustments or hyper-parameters tuning between different models, and is efficient in terms of training times. We test USI on a wide variety of architectures, including CNNs, Transformers, Mobile-oriented and MLP-only. On all models tested, USI outperforms previous state-of-the-art results. Hence, we are able to transform training on ImageNet from an expert-oriented task to an automatic seamless routine. Since USI accepts any backbone and trains it to top results, it also enables to perform methodical comparisons, and identify the most efficient backbones along the speed-accuracy Pareto curve. Implementation is available at:https://github.com/Alibaba-MIIL/Solving_ImageNet
It's All in the Head: Representation Knowledge Distillation through Classifier Sharing
Jan 18, 2022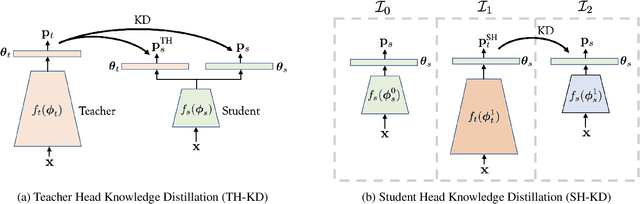
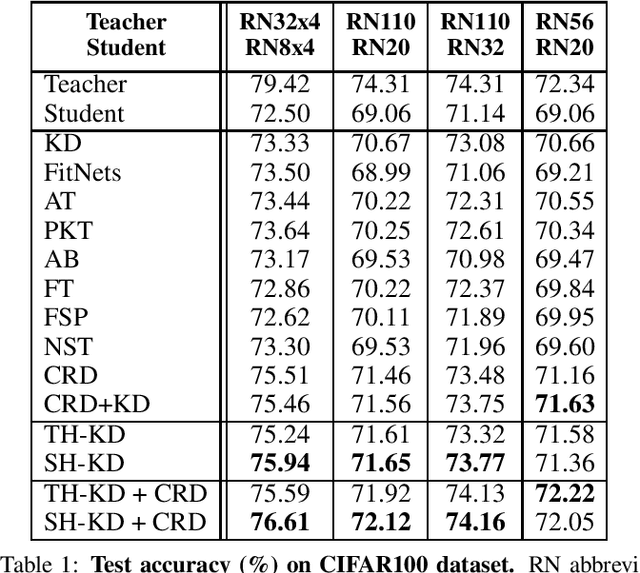
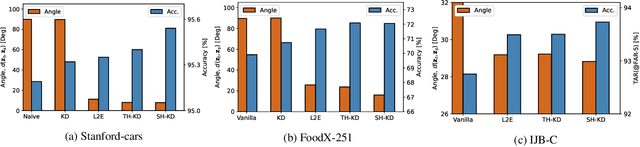
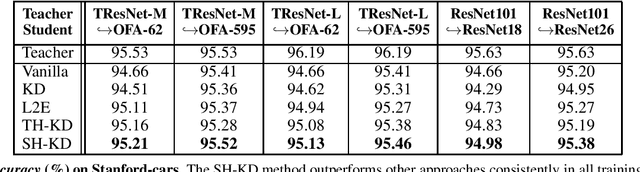
Representation knowledge distillation aims at transferring rich information from one model to another. Current approaches for representation distillation mainly focus on the direct minimization of distance metrics between the models' embedding vectors. Such direct methods may be limited in transferring high-order dependencies embedded in the representation vectors, or in handling the capacity gap between the teacher and student models. In this paper, we introduce two approaches for enhancing representation distillation using classifier sharing between the teacher and student. Specifically, we first show that connecting the teacher's classifier to the student backbone and freezing its parameters is beneficial for the process of representation distillation, yielding consistent improvements. Then, we propose an alternative approach that asks to tailor the teacher model to a student with limited capacity. This approach competes with and in some cases surpasses the first method. Via extensive experiments and analysis, we show the effectiveness of the proposed methods on various datasets and tasks, including image classification, fine-grained classification, and face verification. For example, we achieve state-of-the-art performance for face verification on the IJB-C dataset for a MobileFaceNet model: TAR@(FAR=1e-5)=93.7\%. Code is available at https://github.com/Alibaba-MIIL/HeadSharingKD.
ML-Decoder: Scalable and Versatile Classification Head
Nov 25, 2021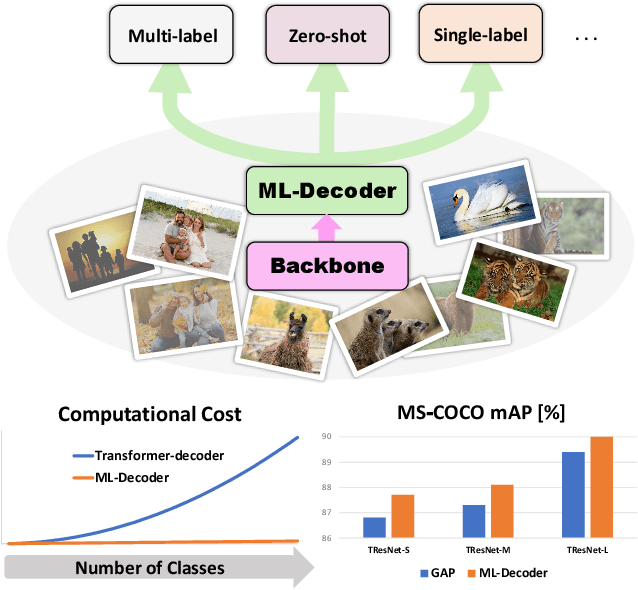
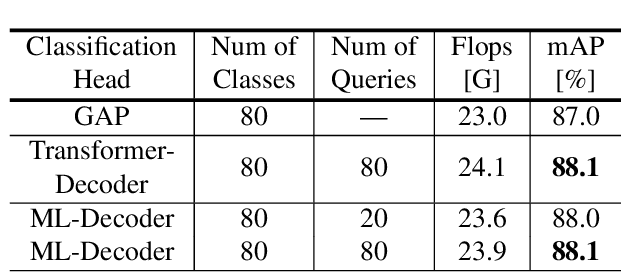
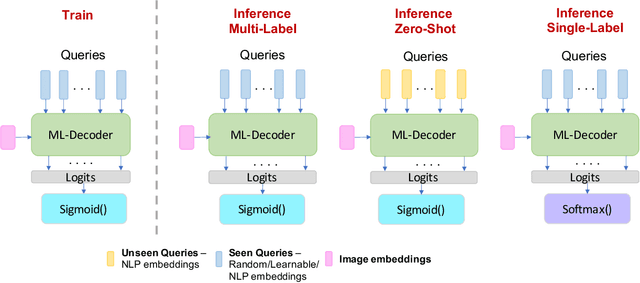
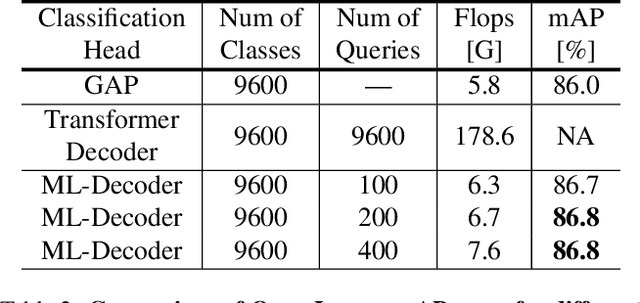
In this paper, we introduce ML-Decoder, a new attention-based classification head. ML-Decoder predicts the existence of class labels via queries, and enables better utilization of spatial data compared to global average pooling. By redesigning the decoder architecture, and using a novel group-decoding scheme, ML-Decoder is highly efficient, and can scale well to thousands of classes. Compared to using a larger backbone, ML-Decoder consistently provides a better speed-accuracy trade-off. ML-Decoder is also versatile - it can be used as a drop-in replacement for various classification heads, and generalize to unseen classes when operated with word queries. Novel query augmentations further improve its generalization ability. Using ML-Decoder, we achieve state-of-the-art results on several classification tasks: on MS-COCO multi-label, we reach 91.4% mAP; on NUS-WIDE zero-shot, we reach 31.1% ZSL mAP; and on ImageNet single-label, we reach with vanilla ResNet50 backbone a new top score of 80.7%, without extra data or distillation. Public code is available at: https://github.com/Alibaba-MIIL/ML_Decoder
Multi-label Classification with Partial Annotations using Class-aware Selective Loss
Oct 21, 2021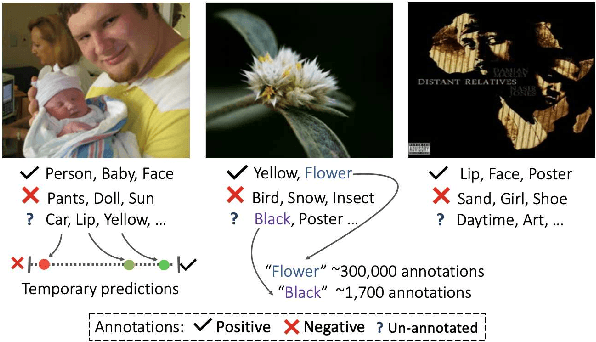
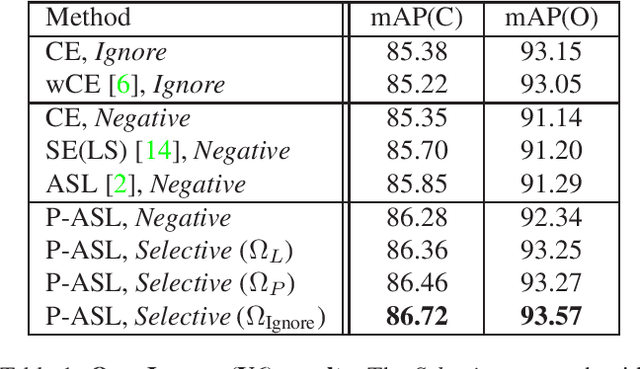
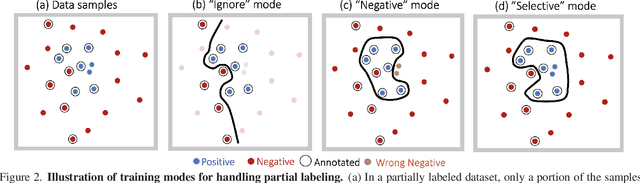

Large-scale multi-label classification datasets are commonly, and perhaps inevitably, partially annotated. That is, only a small subset of labels are annotated per sample. Different methods for handling the missing labels induce different properties on the model and impact its accuracy. In this work, we analyze the partial labeling problem, then propose a solution based on two key ideas. First, un-annotated labels should be treated selectively according to two probability quantities: the class distribution in the overall dataset and the specific label likelihood for a given data sample. We propose to estimate the class distribution using a dedicated temporary model, and we show its improved efficiency over a naive estimation computed using the dataset's partial annotations. Second, during the training of the target model, we emphasize the contribution of annotated labels over originally un-annotated labels by using a dedicated asymmetric loss. With our novel approach, we achieve state-of-the-art results on OpenImages dataset (e.g. reaching 87.3 mAP on V6). In addition, experiments conducted on LVIS and simulated-COCO demonstrate the effectiveness of our approach. Code is available at https://github.com/Alibaba-MIIL/PartialLabelingCSL.
PETA: Photo Albums Event Recognition using Transformers Attention
Sep 26, 2021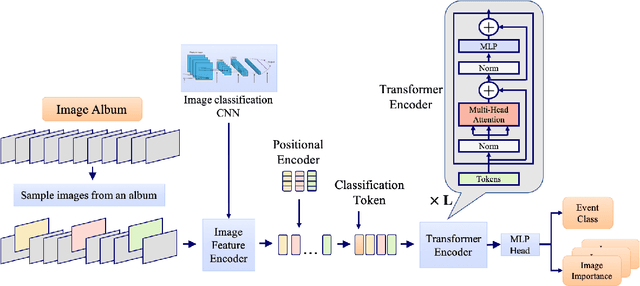
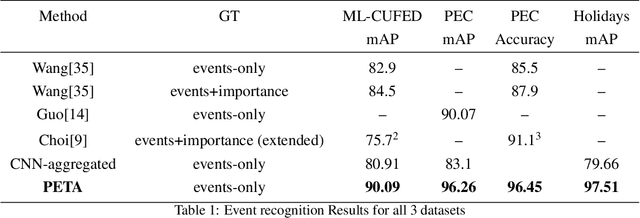

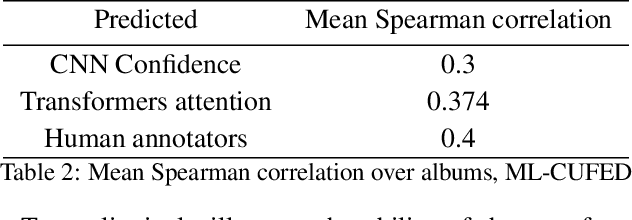
In recent years the amounts of personal photos captured increased significantly, giving rise to new challenges in multi-image understanding and high-level image understanding. Event recognition in personal photo albums presents one challenging scenario where life events are recognized from a disordered collection of images, including both relevant and irrelevant images. Event recognition in images also presents the challenge of high-level image understanding, as opposed to low-level image object classification. In absence of methods to analyze multiple inputs, previous methods adopted temporal mechanisms, including various forms of recurrent neural networks. However, their effective temporal window is local. In addition, they are not a natural choice given the disordered characteristic of photo albums. We address this gap with a tailor-made solution, combining the power of CNNs for image representation and transformers for album representation to perform global reasoning on image collection, offering a practical and efficient solution for photo albums event recognition. Our solution reaches state-of-the-art results on 3 prominent benchmarks, achieving above 90\% mAP on all datasets. We further explore the related image-importance task in event recognition, demonstrating how the learned attentions correlate with the human-annotated importance for this subjective task, thus opening the door for new applications.
ImageNet-21K Pretraining for the Masses
May 04, 2021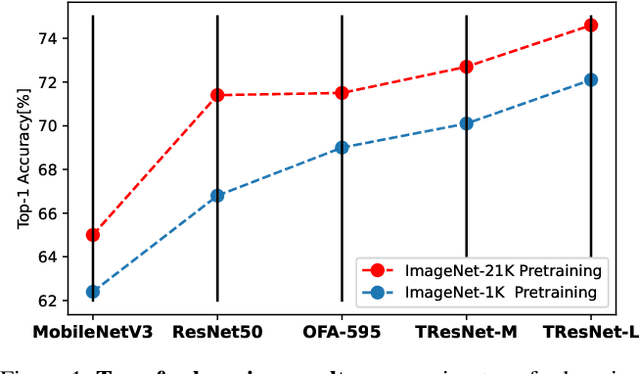

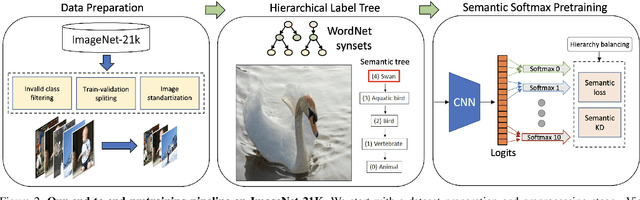
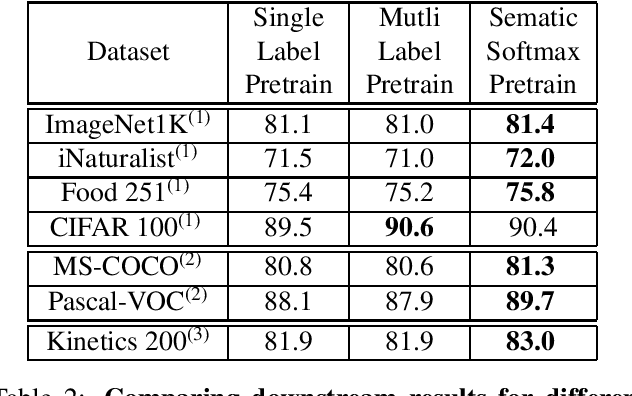
ImageNet-1K serves as the primary dataset for pretraining deep learning models for computer vision tasks. ImageNet-21K dataset, which contains more pictures and classes, is used less frequently for pretraining, mainly due to its complexity, and underestimation of its added value compared to standard ImageNet-1K pretraining. This paper aims to close this gap, and make high-quality efficient pretraining on ImageNet-21K available for everyone. Via a dedicated preprocessing stage, utilizing WordNet hierarchies, and a novel training scheme called semantic softmax, we show that various models, including small mobile-oriented models, significantly benefit from ImageNet-21K pretraining on numerous datasets and tasks. We also show that we outperform previous ImageNet-21K pretraining schemes for prominent new models like ViT. Our proposed pretraining pipeline is efficient, accessible, and leads to SoTA reproducible results, from a publicly available dataset. The training code and pretrained models are available at: https://github.com/Alibaba-MIIL/ImageNet21K
Asymmetric Loss For Multi-Label Classification
Sep 29, 2020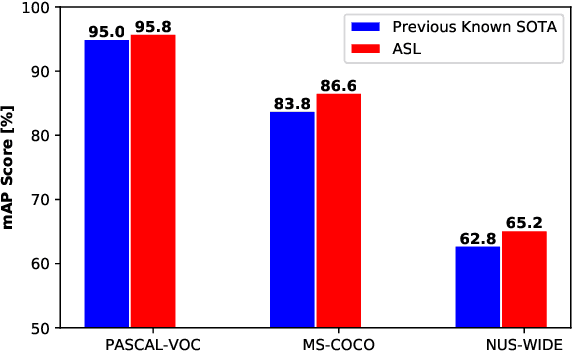
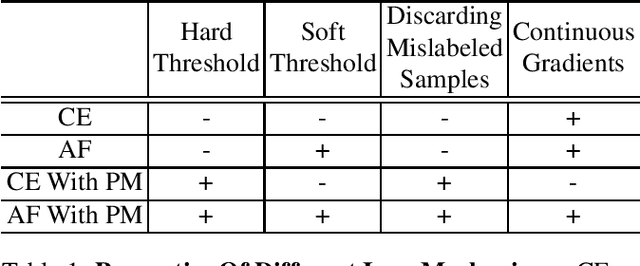
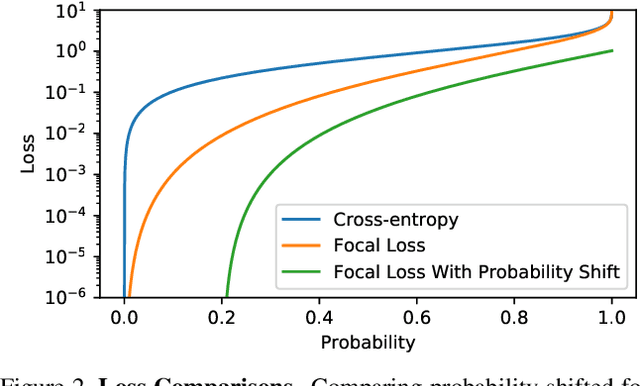
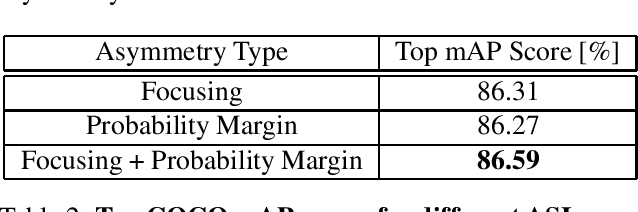
Pictures of everyday life are inherently multi-label in nature. Hence, multi-label classification is commonly used to analyze their content. In typical multi-label datasets, each picture contains only a few positive labels, and many negative ones. This positive-negative imbalance can result in under-emphasizing gradients from positive labels during training, leading to poor accuracy. In this paper, we introduce a novel asymmetric loss ("ASL"), that operates differently on positive and negative samples. The loss dynamically down-weights the importance of easy negative samples, causing the optimization process to focus more on the positive samples, and also enables to discard mislabeled negative samples. We demonstrate how ASL leads to a more "balanced" network, with increased average probabilities for positive samples, and show how this balanced network is translated to better mAP scores, compared to commonly used losses. Furthermore, we offer a method that can dynamically adjust the level of asymmetry throughout the training. With ASL, we reach new state-of-the-art results on three common multi-label datasets, including achieving 86.6% on MS-COCO. We also demonstrate ASL applicability for other tasks such as fine-grain single-label classification and object detection. ASL is effective, easy to implement, and does not increase the training time or complexity. Implementation is available at: https://github.com/Alibaba-MIIL/ASL.