 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling the Knowledge in Data Pruning
Mar 12, 2024



With the increasing size of datasets used for training neural networks, data pruning becomes an attractive field of research. However, most current data pruning algorithms are limited in their ability to preserve accuracy compared to models trained on the full data, especially in high pruning regimes. In this paper we explore the application of data pruning while incorporating knowledge distillation (KD) when training on a pruned subset. That is, rather than relying solely on ground-truth labels, we also use the soft predictions from a teacher network pre-trained on the complete data. By integrating KD into training, we demonstrate significant improvement across datasets, pruning methods, and on all pruning fractions. We first establish a theoretical motivation for employing self-distillation to improve training on pruned data. Then, we empirically make a compelling and highly practical observation: using KD, simple random pruning is comparable or superior to sophisticated pruning methods across all pruning regimes. On ImageNet for example, we achieve superior accuracy despite training on a random subset of only 50% of the data. Additionally, we demonstrate a crucial connection between the pruning factor and the optimal knowledge distillation weight. This helps mitigate the impact of samples with noisy labels and low-quality images retained by typical pruning algorithms. Finally, we make an intriguing observation: when using lower pruning fractions, larger teachers lead to accuracy degradation, while surprisingly, employing teachers with a smaller capacity than the student's may improve results. Our code will be made available.
The Multi-Strand Graph for a PTZ Tracker
Jun 29, 2015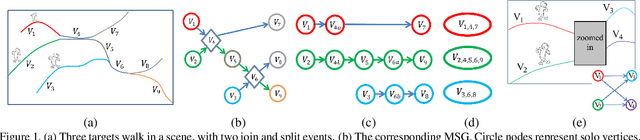
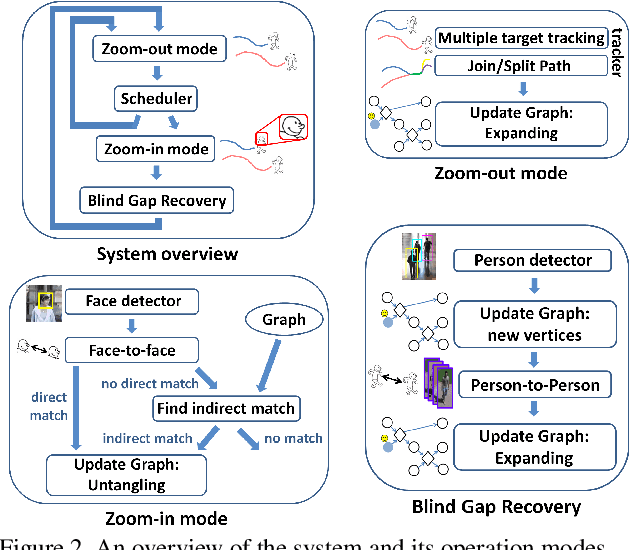

High-resolution images can be used to resolve matching ambiguities between trajectory fragments (tracklets), which is one of the main challenges in multiple target tracking. A PTZ camera, which can pan, tilt and zoom, is a powerful and efficient tool that offers both close-up views and wide area coverage on demand. The wide-area view makes it possible to track many targets while the close-up view allows individuals to be identified from high-resolution images of their faces. A central component of a PTZ tracking system is a scheduling algorithm that determines which target to zoom in on. In this paper we study this scheduling problem from a theoretical perspective, where the high resolution images are also used for tracklet matching. We propose a novel data structure, the Multi-Strand Tracking Graph (MSG), which represents the set of tracklets computed by a tracker and the possible associations between them. The MSG allows efficient scheduling as well as resolving -- directly or by elimination -- matching ambiguities between tracklets. The main feature of the MSG is the auxiliary data saved in each vertex, which allows efficient computation while avoiding time-consuming graph traversal. Synthetic data simulations are used to evaluate our scheduling algorithm and to demonstrate its superiority over a na\"ive one.