 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiamonds in the Sky: Pareidolic Animals in Clouds
May 31, 2026People often see animal shapes in clouds, a phenomenon known as pareidolia. We propose an AI-based method that aims to predict which animals people are likely to perceive in clouds, even though state-of-the-art recognition methods typically fail to detect such animals. Additionally, we introduce a method to assist individuals in perceiving specific pareidolic animals, even if they did not recognize them initially. Our approach uses a diffusion model to transform cloud segments into an animal shape that visually resemble the original cloud. This diffusion technique is inspired by the observation that the diffusion process succeeds only when the target animal resembles the shape of the cloud, and that subtle visual hints often suffice to help individuals recognize specific pareidolic animals. A generated image, successfully derived from the diffusion model, is then used to predict the pareidolic animal. Additionally, a short morphing video transitioning from the generated image back to the original cloud segment is employed to further enhance the human's perception of the pareidolic animals.
On the Role of Geometry in Geo-Localization
Jun 26, 2019
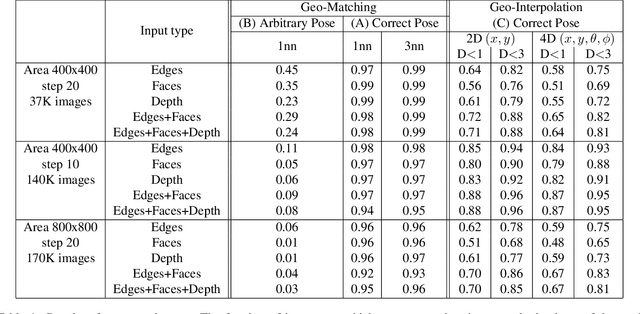
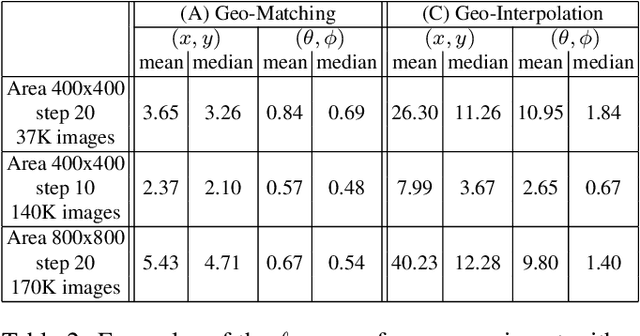
Humans can build a mental map of a geographical area to find their way and recognize places. The basic task we consider is geo-localization - finding the pose (position & orientation) of a camera in a large 3D scene from a single image. We aim to experimentally explore the role of geometry in geo-localization in a convolutional neural network (CNN) solution. We do so by ignoring the often available texture of the scene. We therefore deliberately avoid using texture or rich geometric details and use images projected from a simple 3D model of a city, which we term lean images. Lean images contain solely information that relates to the geometry of the area viewed (edges, faces, or relative depth). We find that the network is capable of estimating the camera pose from the lean images, and it does so not by memorization but by some measure of geometric learning of the geographical area. The main contributions of this paper are: (i) providing insight into the role of geometry in the CNN learning process; and (ii) demonstrating the power of CNNs for recovering camera pose using lean images.
CrowdCam: Dynamic Region Segmentation
Nov 28, 2018
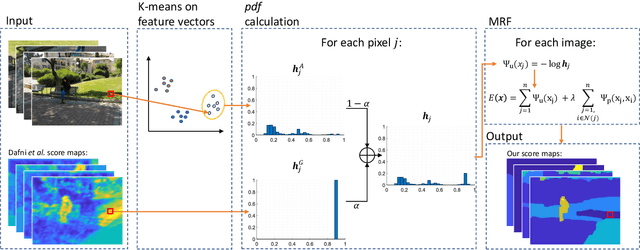
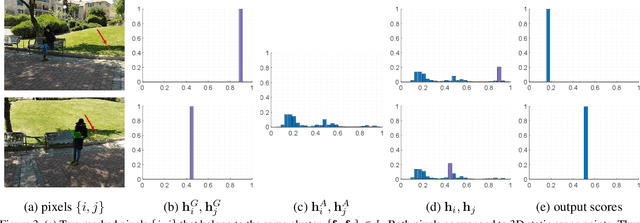
We consider the problem of segmenting dynamic regions in CrowdCam images, where a dynamic region is the projection of a moving 3D object on the image plane. Quite often, these regions are the most interesting parts of an image. CrowdCam images is a set of images of the same dynamic event, captured by a group of non-collaborating users. Almost every event of interest today is captured this way. This new type of images raises the need to develop new algorithms tailored specifically for it. We propose an algorithm that segments the dynamic regions in CrowdCam images. The proposed algorithm combines cues that are based on geometry, appearance and proximity. First, geometric reasoning is used to produce rough score maps that determine, for every pixel, how likely it is to be the projection of a static or dynamic scene point. These maps are noisy because CrowdCam images are usually few and far apart both in space and in time. Then, we use similarity in appearance space and proximity in the image plane to encourage neighboring pixels to be labeled similarly as either static or dynamic. We define an objective function that combines all the cues and solves it using an MRF solver. The proposed method was tested on publicly available CrowdCam datasets, as well as a new and challenging dataset we collected. Our results are better than the current state-of-the-art.
Detecting Moving Regions in CrowdCam Images
Nov 10, 2016
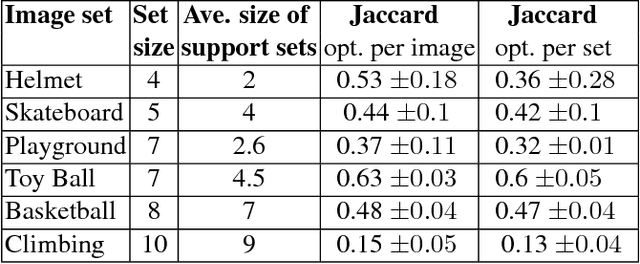


We address the novel problem of detecting dynamic regions in CrowdCam images, a set of still images captured by a group of people. These regions capture the most interesting parts of the scene, and detecting them plays an important role in the analysis of visual data. Our method is based on the observation that matching static points must satisfy the epipolar geometry constraints, but computing exact matches is challenging. Instead, we compute the probability that a pixel has a match, not necessarily the correct one, along the corresponding epipolar line. The complement of this probability is not necessarily the probability of a dynamic point because of occlusions, noise, and matching errors. Therefore, information from all pairs of images is aggregated to obtain a high quality dynamic probability map, per image. Experiments on challenging datasets demonstrate the effectiveness of the algorithm on a broad range of settings; no prior knowledge about the scene, the camera characteristics or the camera locations is required.
The Multi-Strand Graph for a PTZ Tracker
Jun 29, 2015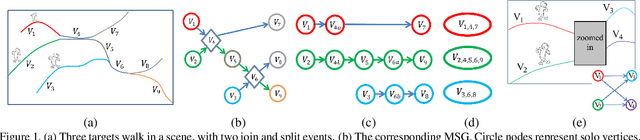
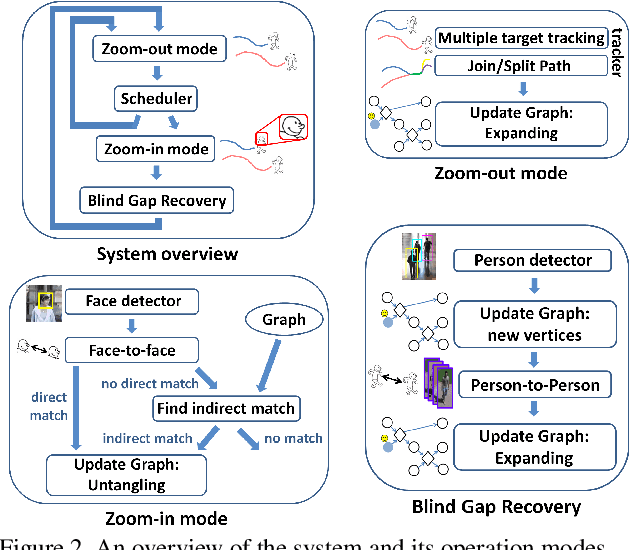

High-resolution images can be used to resolve matching ambiguities between trajectory fragments (tracklets), which is one of the main challenges in multiple target tracking. A PTZ camera, which can pan, tilt and zoom, is a powerful and efficient tool that offers both close-up views and wide area coverage on demand. The wide-area view makes it possible to track many targets while the close-up view allows individuals to be identified from high-resolution images of their faces. A central component of a PTZ tracking system is a scheduling algorithm that determines which target to zoom in on. In this paper we study this scheduling problem from a theoretical perspective, where the high resolution images are also used for tracklet matching. We propose a novel data structure, the Multi-Strand Tracking Graph (MSG), which represents the set of tracklets computed by a tracker and the possible associations between them. The MSG allows efficient scheduling as well as resolving -- directly or by elimination -- matching ambiguities between tracklets. The main feature of the MSG is the auxiliary data saved in each vertex, which allows efficient computation while avoiding time-consuming graph traversal. Synthetic data simulations are used to evaluate our scheduling algorithm and to demonstrate its superiority over a na\"ive one.
Have a Look at What I See
May 19, 2015

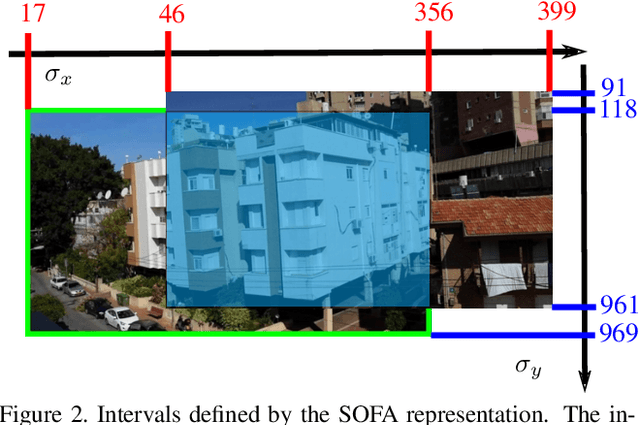

We propose a method for guiding a photographer to rotate her/his smartphone camera to obtain an image that overlaps with another image of the same scene. The other image is taken by another photographer from a different viewpoint. Our method is applicable even when the images do not have overlapping fields of view. Straightforward applications of our method include sharing attention to regions of interest for social purposes, or adding missing images to improve structure for motion results. Our solution uses additional images of the scene, which are often available since many people use their smartphone cameras regularly. These images may be available online from other photographers who are present at the scene. Our method avoids 3D scene reconstruction; it relies instead on a new representation that consists of the spatial orders of the scene points on two axes, x and y. This representation allows a sequence of points to be chosen efficiently and projected onto the photographers images, using epipolar point transfer. Overlaying these epipolar lines on the live preview of the camera produces a convenient interface to guide the user. The method was tested on challenging datasets of images and succeeded in guiding a photographer from one view to a non-overlapping destination view.