 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Cold Start to Active Learning: Embedding-Based Scan Selection for Medical Image Segmentation
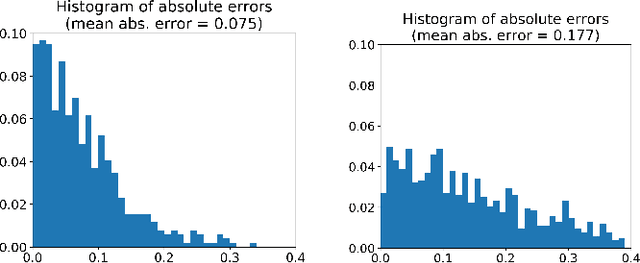
Jan 26, 2026Accurate segmentation annotations are critical for disease monitoring, yet manual labeling remains a major bottleneck due to the time and expertise required. Active learning (AL) alleviates this burden by prioritizing informative samples for annotation, typically through a diversity-based cold-start phase followed by uncertainty-driven selection. We propose a novel cold-start sampling strategy that combines foundation-model embeddings with clustering, including automatic selection of the number of clusters and proportional sampling across clusters, to construct a diverse and representative initial training. This is followed by an uncertainty-based AL framework that integrates spatial diversity to guide sample selection. The proposed method is intuitive and interpretable, enabling visualization of the feature-space distribution of candidate samples. We evaluate our approach on three datasets spanning X-ray and MRI modalities. On the CheXmask dataset, the cold-start strategy outperforms random selection, improving Dice from 0.918 to 0.929 and reducing the Hausdorff distance from 32.41 to 27.66 mm. In the AL setting, combined entropy and diversity selection improves Dice from 0.919 to 0.939 and reduces the Hausdorff distance from 30.10 to 19.16 mm. On the Montgomery dataset, cold-start gains are substantial, with Dice improving from 0.928 to 0.950 and Hausdorff distance decreasing from 14.22 to 9.38 mm. On the SynthStrip dataset, cold-start selection slightly affects Dice but reduces the Hausdorff distance from 9.43 to 8.69 mm, while active learning improves Dice from 0.816 to 0.826 and reduces the Hausdorff distance from 7.76 to 6.38 mm. Overall, the proposed framework consistently outperforms baseline methods in low-data regimes, improving segmentation accuracy.
DogFLW: Dog Facial Landmarks in the Wild Dataset
May 19, 2024Affective computing for animals is a rapidly expanding research area that is going deeper than automated movement tracking to address animal internal states, like pain and emotions. Facial expressions can serve to communicate information about these states in mammals. However, unlike human-related studies, there is a significant shortage of datasets that would enable the automated analysis of animal facial expressions. Inspired by the recently introduced Cat Facial Landmarks in the Wild dataset, presenting cat faces annotated with 48 facial anatomy-based landmarks, in this paper, we develop an analogous dataset containing 3,274 annotated images of dogs. Our dataset is based on a scheme of 46 facial anatomy-based landmarks. The DogFLW dataset is available from the corresponding author upon a reasonable request.
Automated Detection of Cat Facial Landmarks
Oct 15, 2023The field of animal affective computing is rapidly emerging, and analysis of facial expressions is a crucial aspect. One of the most significant challenges that researchers in the field currently face is the scarcity of high-quality, comprehensive datasets that allow the development of models for facial expressions analysis. One of the possible approaches is the utilisation of facial landmarks, which has been shown for humans and animals. In this paper we present a novel dataset of cat facial images annotated with bounding boxes and 48 facial landmarks grounded in cat facial anatomy. We also introduce a landmark detection convolution neural network-based model which uses a magnifying ensembe method. Our model shows excellent performance on cat faces and is generalizable to human facial landmark detection.
CatFLW: Cat Facial Landmarks in the Wild Dataset
May 07, 2023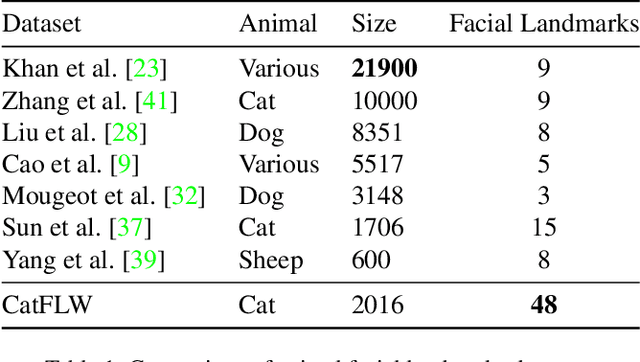


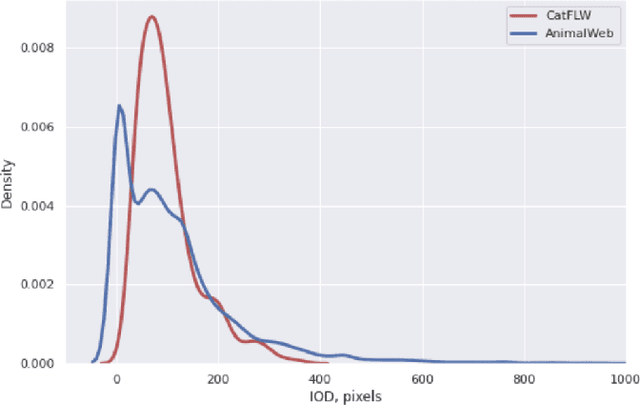
Animal affective computing is a quickly growing field of research, where only recently first efforts to go beyond animal tracking into recognizing their internal states, such as pain and emotions, have emerged. In most mammals, facial expressions are an important channel for communicating information about these states. However, unlike the human domain, there is an acute lack of datasets that make automation of facial analysis of animals feasible. This paper aims to fill this gap by presenting a dataset called Cat Facial Landmarks in the Wild (CatFLW) which contains 2016 images of cat faces in different environments and conditions, annotated with 48 facial landmarks specifically chosen for their relationship with underlying musculature, and relevance to cat-specific facial Action Units (CatFACS). To the best of our knowledge, this dataset has the largest amount of cat facial landmarks available. In addition, we describe a semi-supervised (human-in-the-loop) method of annotating images with landmarks, used for creating this dataset, which significantly reduces the annotation time and could be used for creating similar datasets for other animals. The dataset is available on request.
ArcAid: Analysis of Archaeological Artifacts using Drawings
Nov 17, 2022Archaeology is an intriguing domain for computer vision. It suffers not only from shortage in (labeled) data, but also from highly-challenging data, which is often extremely abraded and damaged. This paper proposes a novel semi-supervised model for classification and retrieval of images of archaeological artifacts. This model utilizes unique data that exists in the domain -- manual drawings made by special artists.These are used during training to implicitly transfer the domain knowledge from the drawings to their corresponding images, improving their classification results. We show that while learning how to classify, our model also learns how to generate drawings of the artifacts, an important documentation task, which is currently performed manually. Last but not least, we collected a new dataset of stamp-seals of the Southern Levant.
Detecting Deficient Coverage in Colonoscopies
Jan 26, 2020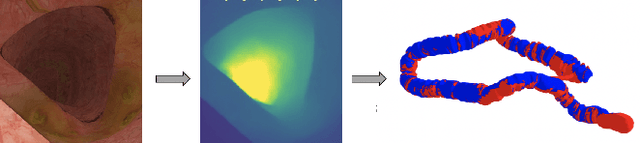
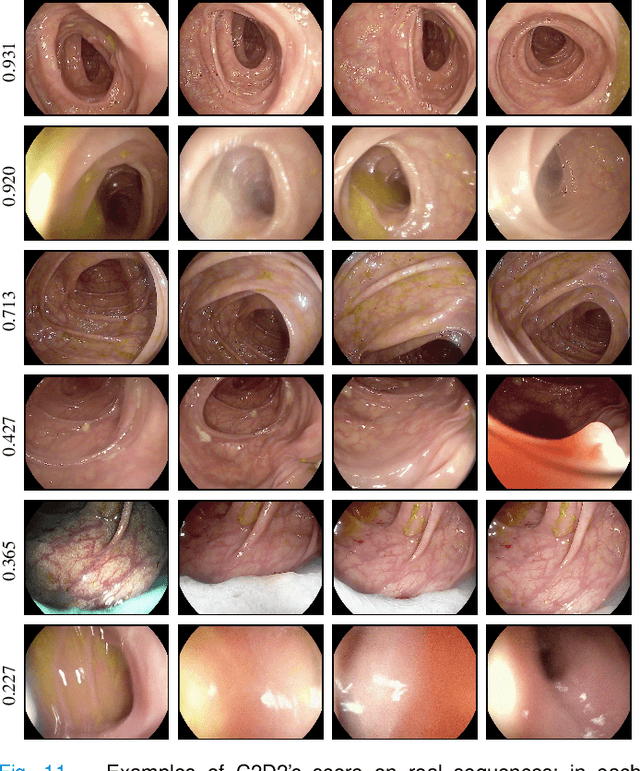
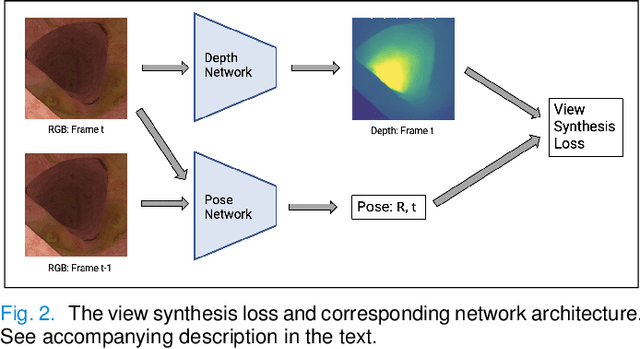
Colorectal Cancer (CRC) is a global health problem, resulting in 900K deaths per year. Colonoscopy is the tool of choice for preventing CRC, by detecting polyps before they become cancerous, and removing them. However, colonoscopy is hampered by the fact that endoscopists routinely miss an average of 22-28% of polyps. While some of these missed polyps appear in the endoscopist's field of view, others are missed simply because of substandard coverage of the procedure, i.e. not all of the colon is seen. This paper attempts to rectify the problem of substandard coverage in colonoscopy through the introduction of the C2D2 (Colonoscopy Coverage Deficiency via Depth) algorithm which detects deficient coverage, and can thereby alert the endoscopist to revisit a given area. More specifically, C2D2 consists of two separate algorithms: the first performs depth estimation of the colon given an ordinary RGB video stream; while the second computes coverage given these depth estimates. Rather than compute coverage for the entire colon, our algorithm computes coverage locally, on a segment-by-segment basis; C2D2 can then indicate in real-time whether a particular area of the colon has suffered from deficient coverage, and if so the endoscopist can return to that area. Our coverage algorithm is the first such algorithm to be evaluated in a large-scale way; while our depth estimation technique is the first calibration-free unsupervised method applied to colonoscopies. The C2D2 algorithm achieves state of the art results in the detection of deficient coverage: it is 2.4 times more accurate than human experts.
A-MAL: Automatic Motion Assessment Learning from Properly Performed Motions in 3D Skeleton Videos
Aug 29, 2019


Assessment of motion quality has recently gained high demand in a variety of domains. The ability to automatically assess subject motion in videos that were captured by cheap devices, such as Kinect cameras, is essential for monitoring clinical rehabilitation processes, for improving motor skills and for motion learning tasks. The need to pay attention to low-level details while accurately tracking the motion stages, makes this task very challenging. In this work, we introduce A-MAL, an automatic, strong motion assessment learning algorithm that only learns from properly-performed motion videos without further annotations, powered by a deviation time-segmentation algorithm, a parameter relevance detection algorithm, a novel time-warping algorithm that is based on automatic detection of common temporal points-of-interest and a textual-feedback generation mechanism. We demonstrate our method on motions from the Fugl-Meyer Assessment (FMA) test, which is typically held by occupational therapists in order to monitor patients' recovery processes after strokes.
Solving Archaeological Puzzles
Dec 26, 2018



Puzzle solving is a difficult problem in its own right, even when the pieces are all square and build up a natural image. But what if these ideal conditions do not hold? One such application domain is archaeology, where restoring an artifact from its fragments is highly important. From the point of view of computer vision, archaeological puzzle solving is very challenging, due to three additional difficulties: the fragments are of general shape; they are abraded, especially at the boundaries (where the strongest cues for matching should exist); and the domain of valid transformations between the pieces is continuous. The key contribution of this paper is a fully-automatic and general algorithm that addresses puzzle solving in this intriguing domain. We show that our state-of-the-art approach manages to correctly reassemble dozens of broken artifacts and frescoes.
Have a Look at What I See
May 19, 2015

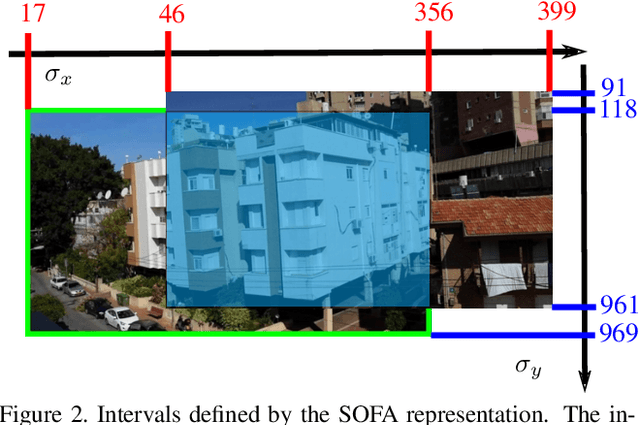

We propose a method for guiding a photographer to rotate her/his smartphone camera to obtain an image that overlaps with another image of the same scene. The other image is taken by another photographer from a different viewpoint. Our method is applicable even when the images do not have overlapping fields of view. Straightforward applications of our method include sharing attention to regions of interest for social purposes, or adding missing images to improve structure for motion results. Our solution uses additional images of the scene, which are often available since many people use their smartphone cameras regularly. These images may be available online from other photographers who are present at the scene. Our method avoids 3D scene reconstruction; it relies instead on a new representation that consists of the spatial orders of the scene points on two axes, x and y. This representation allows a sequence of points to be chosen efficiently and projected onto the photographers images, using epipolar point transfer. Overlaying these epipolar lines on the live preview of the camera produces a convenient interface to guide the user. The method was tested on challenging datasets of images and succeeded in guiding a photographer from one view to a non-overlapping destination view.
A General Preprocessing Method for Improved Performance of Epipolar Geometry Estimation Algorithms
Jan 27, 2015



In this paper a deterministic preprocessing algorithm is presented, whose output can be given as input to most state-of-the-art epipolar geometry estimation algorithms, improving their results considerably. They are now able to succeed on hard cases for which they failed before. The algorithm consists of three steps, whose scope changes from local to global. In the local step it extracts from a pair of images local features (e.g. SIFT). Similar features from each image are clustered and the clusters are matched yielding a large number of putative matches. In the second step pairs of spatially close features (called 2keypoints) are matched and ranked by a classifier. The 2keypoint matches with the highest ranks are selected. In the global step, from each two 2keypoint matches a fundamental matrix is computed. As quite a few of the matrices are generated from correct matches they are used to rank the putative matches found in the first step. For each match the number of fundamental matrices, for which it approximately satisfies the epipolar constraint, is calculated. This set of matches is combined with the putative matches generated by standard methods and their probabilities to be correct are estimated by a classifier. These are then given as input to state-of-the-art epipolar geometry estimation algorithms such as BEEM, BLOGS and USAC yielding much better results than the original algorithms. This was shown in extensive testing performed on almost 900 image pairs from six publicly available data-sets.