 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind The Edge: Refining Depth Edges in Sparsely-Supervised Monocular Depth Estimation
Dec 10, 2022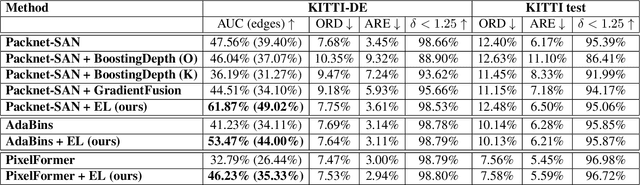



Monocular Depth Estimation (MDE) is a fundamental problem in computer vision with numerous applications. Recently, LIDAR-supervised methods have achieved remarkable per-pixel depth accuracy in outdoor scenes. However, significant errors are typically found in the proximity of depth discontinuities, i.e., depth edges, which often hinder the performance of depth-dependent applications that are sensitive to such inaccuracies, e.g., novel view synthesis and augmented reality. Since direct supervision for the location of depth edges is typically unavailable in sparse LIDAR-based scenes, encouraging the MDE model to produce correct depth edges is not straightforward. In this work we propose to learn to detect the location of depth edges from densely-supervised synthetic data, and use it to generate supervision for the depth edges in the MDE training. %Despite the 'domain gap' between synthetic and real data, we show that depth edges that are estimated directly are significantly more accurate than the ones that emerge indirectly from the MDE training. To quantitatively evaluate our approach, and due to the lack of depth edges ground truth in LIDAR-based scenes, we manually annotated subsets of the KITTI and the DDAD datasets with depth edges ground truth. We demonstrate significant gains in the accuracy of the depth edges with comparable per-pixel depth accuracy on several challenging datasets.
Consistent Semantic Attacks on Optical Flow
Nov 16, 2021


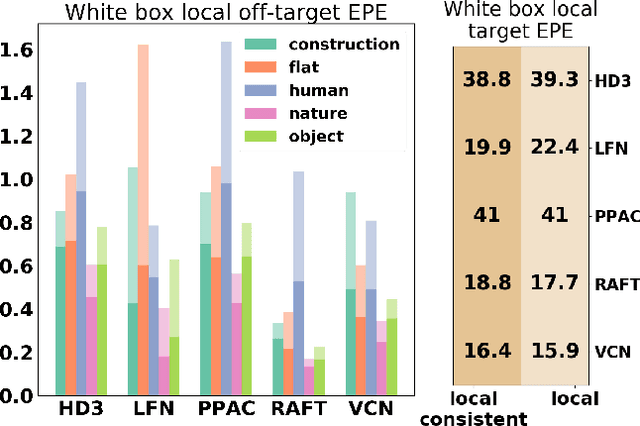
We present a novel approach for semantically targeted adversarial attacks on Optical Flow. In such attacks the goal is to corrupt the flow predictions of a specific object category or instance. Usually, an attacker seeks to hide the adversarial perturbations in the input. However, a quick scan of the output reveals the attack. In contrast, our method helps to hide the attackers intent in the output as well. We achieve this thanks to a regularization term that encourages off-target consistency. We perform extensive tests on leading optical flow models to demonstrate the benefits of our approach in both white-box and black-box settings. Also, we demonstrate the effectiveness of our attack on subsequent tasks that depend on the optical flow.
Have a Look at What I See
May 19, 2015

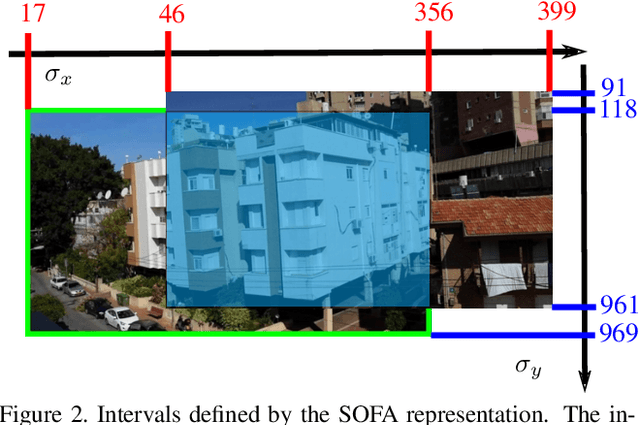

We propose a method for guiding a photographer to rotate her/his smartphone camera to obtain an image that overlaps with another image of the same scene. The other image is taken by another photographer from a different viewpoint. Our method is applicable even when the images do not have overlapping fields of view. Straightforward applications of our method include sharing attention to regions of interest for social purposes, or adding missing images to improve structure for motion results. Our solution uses additional images of the scene, which are often available since many people use their smartphone cameras regularly. These images may be available online from other photographers who are present at the scene. Our method avoids 3D scene reconstruction; it relies instead on a new representation that consists of the spatial orders of the scene points on two axes, x and y. This representation allows a sequence of points to be chosen efficiently and projected onto the photographers images, using epipolar point transfer. Overlaying these epipolar lines on the live preview of the camera produces a convenient interface to guide the user. The method was tested on challenging datasets of images and succeeded in guiding a photographer from one view to a non-overlapping destination view.