 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne scalar is all you need -- absolute depth estimation using monocular self-supervision
Mar 15, 2023



Self-supervised monocular depth estimators can be trained or fine-tuned on new scenes using only images and no ground-truth depth data, achieving good accuracy. However, these estimators suffer from the inherent ambiguity of the depth scale, significantly limiting their applicability. In this work, we present a method for transferring the depth-scale from existing source datasets collected with ground-truth depths to depth estimators that are trained using self-supervision on a newly collected target dataset consisting of images only, solving a significant limiting factor. We show that self-supervision based on projective geometry results in predicted depths that are linearly correlated with their ground-truth depths. Moreover, the linearity of this relationship also holds when jointly training on images from two different (real or synthetic) source and target domains. We utilize this observed property and model the relationship between the ground-truth and the predicted up-to-scale depths of images from the source domain using a single global scalar. Then, we scale the predicted up-to-scale depths of images from the target domain using the estimated global scaling factor, performing depth-scale transfer between the two domains. This suggested method was evaluated on the target KITTI and DDAD datasets, while using other real or synthetic source datasets, that have a larger field-of-view, other image style or structural content. Our approach achieves competitive accuracy on KITTI, even without using the specially tailored vKITTI or vKITTI2 datasets, and higher accuracy on DDAD, when using both real or synthetic source datasets.
Mind The Edge: Refining Depth Edges in Sparsely-Supervised Monocular Depth Estimation
Dec 10, 2022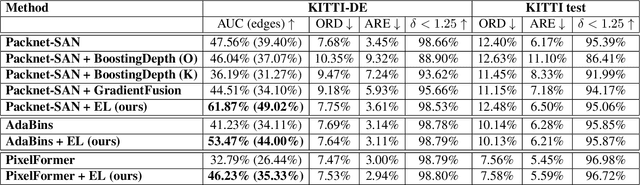



Monocular Depth Estimation (MDE) is a fundamental problem in computer vision with numerous applications. Recently, LIDAR-supervised methods have achieved remarkable per-pixel depth accuracy in outdoor scenes. However, significant errors are typically found in the proximity of depth discontinuities, i.e., depth edges, which often hinder the performance of depth-dependent applications that are sensitive to such inaccuracies, e.g., novel view synthesis and augmented reality. Since direct supervision for the location of depth edges is typically unavailable in sparse LIDAR-based scenes, encouraging the MDE model to produce correct depth edges is not straightforward. In this work we propose to learn to detect the location of depth edges from densely-supervised synthetic data, and use it to generate supervision for the depth edges in the MDE training. %Despite the 'domain gap' between synthetic and real data, we show that depth edges that are estimated directly are significantly more accurate than the ones that emerge indirectly from the MDE training. To quantitatively evaluate our approach, and due to the lack of depth edges ground truth in LIDAR-based scenes, we manually annotated subsets of the KITTI and the DDAD datasets with depth edges ground truth. We demonstrate significant gains in the accuracy of the depth edges with comparable per-pixel depth accuracy on several challenging datasets.
You Better Look Twice: a new perspective for designing accurate detectors with reduced computations
Aug 03, 2021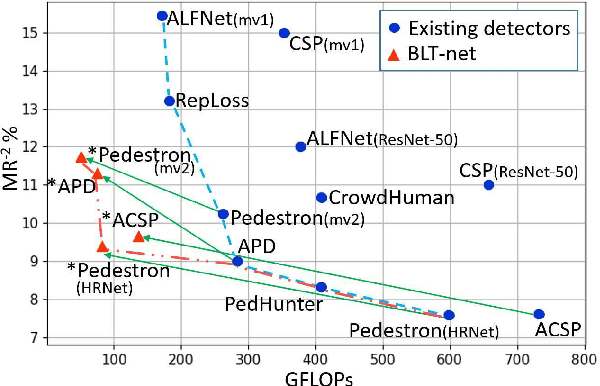
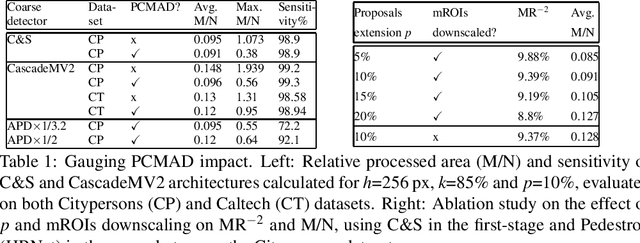
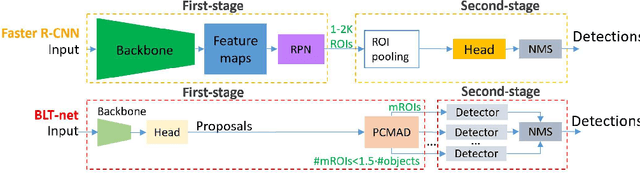
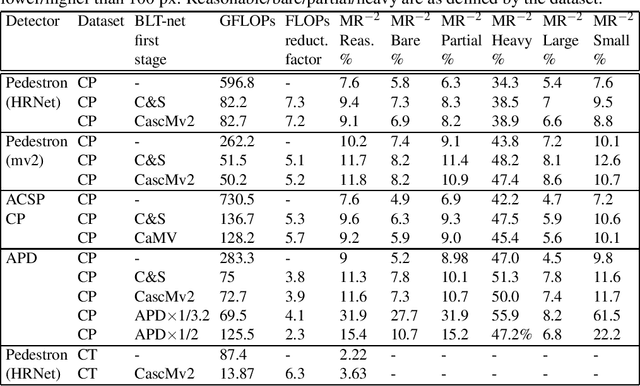
General object detectors use powerful backbones that uniformly extract features from images for enabling detection of a vast amount of object types. However, utilization of such backbones in object detection applications developed for specific object types can unnecessarily over-process an extensive amount of background. In addition, they are agnostic to object scales, thus redundantly process all image regions at the same resolution. In this work we introduce BLT-net, a new low-computation two-stage object detection architecture designed to process images with a significant amount of background and objects of variate scales. BLT-net reduces computations by separating objects from background using a very lite first-stage. BLT-net then efficiently merges obtained proposals to further decrease processed background and then dynamically reduces their resolution to minimize computations. Resulting image proposals are then processed in the second-stage by a highly accurate model. We demonstrate our architecture on the pedestrian detection problem, where objects are of different sizes, images are of high resolution and object detection is required to run in real-time. We show that our design reduces computations by a factor of x4-x7 on the Citypersons and Caltech datasets with respect to leading pedestrian detectors, on account of a small accuracy degradation. This method can be applied on other object detection applications in scenes with a considerable amount of background and variate object sizes to reduce computations.