 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Better Look Twice: a new perspective for designing accurate detectors with reduced computations
Aug 03, 2021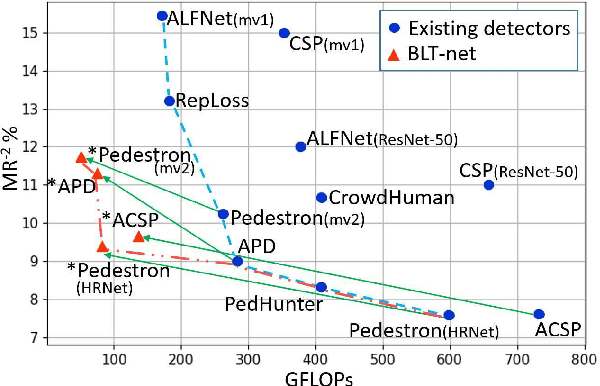
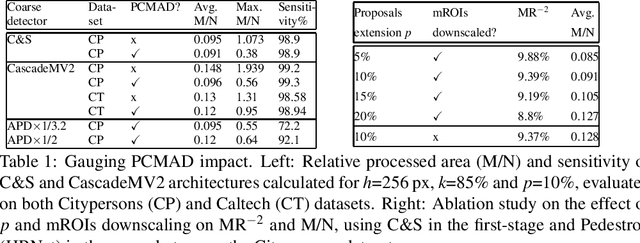
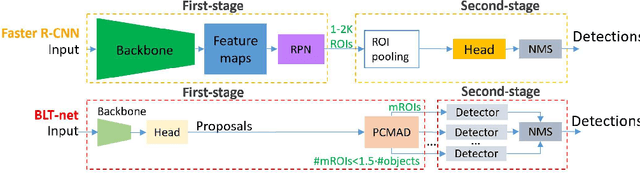
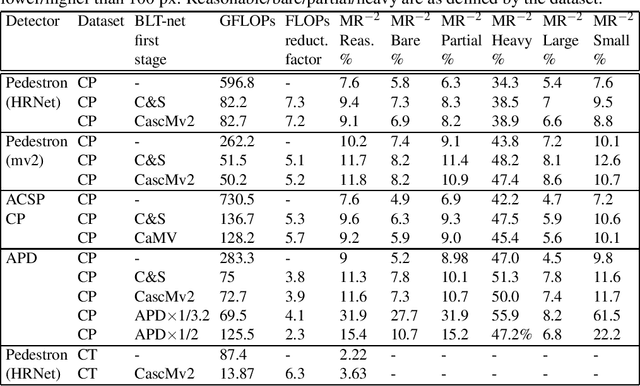
General object detectors use powerful backbones that uniformly extract features from images for enabling detection of a vast amount of object types. However, utilization of such backbones in object detection applications developed for specific object types can unnecessarily over-process an extensive amount of background. In addition, they are agnostic to object scales, thus redundantly process all image regions at the same resolution. In this work we introduce BLT-net, a new low-computation two-stage object detection architecture designed to process images with a significant amount of background and objects of variate scales. BLT-net reduces computations by separating objects from background using a very lite first-stage. BLT-net then efficiently merges obtained proposals to further decrease processed background and then dynamically reduces their resolution to minimize computations. Resulting image proposals are then processed in the second-stage by a highly accurate model. We demonstrate our architecture on the pedestrian detection problem, where objects are of different sizes, images are of high resolution and object detection is required to run in real-time. We show that our design reduces computations by a factor of x4-x7 on the Citypersons and Caltech datasets with respect to leading pedestrian detectors, on account of a small accuracy degradation. This method can be applied on other object detection applications in scenes with a considerable amount of background and variate object sizes to reduce computations.
Layer Folding: Neural Network Depth Reduction using Activation Linearization
Jun 17, 2021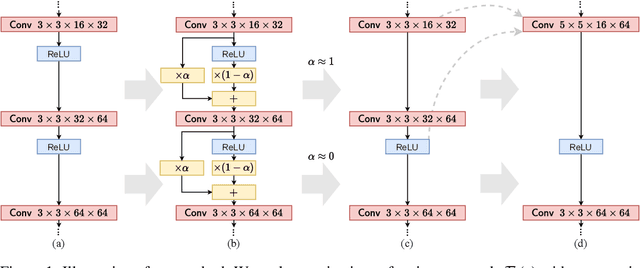

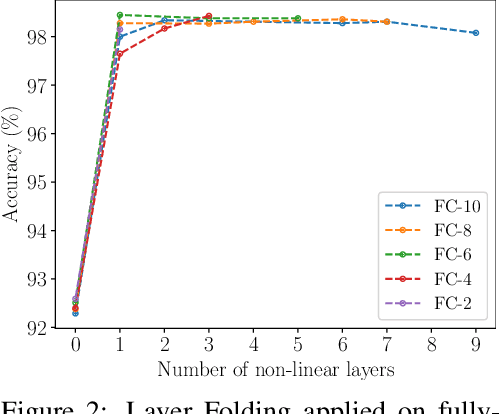

Despite the increasing prevalence of deep neural networks, their applicability in resource-constrained devices is limited due to their computational load. While modern devices exhibit a high level of parallelism, real-time latency is still highly dependent on networks' depth. Although recent works show that below a certain depth, the width of shallower networks must grow exponentially, we presume that neural networks typically exceed this minimal depth to accelerate convergence and incrementally increase accuracy. This motivates us to transform pre-trained deep networks that already exploit such advantages into shallower forms. We propose a method that learns whether non-linear activations can be removed, allowing to fold consecutive linear layers into one. We apply our method to networks pre-trained on CIFAR-10 and CIFAR-100 and find that they can all be transformed into shallower forms that share a similar depth. Finally, we use our method to provide more efficient alternatives to MobileNetV2 and EfficientNet-Lite architectures on the ImageNet classification task.