 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOVE: A Large-Scale Multi-Dimensional Predictions Dataset Towards Meaningful LLM Evaluation
Mar 04, 2025Recent work found that LLMs are sensitive to a wide range of arbitrary prompt dimensions, including the type of delimiters, answer enumerators, instruction wording, and more. This throws into question popular single-prompt evaluation practices. We present DOVE (Dataset Of Variation Evaluation) a large-scale dataset containing prompt perturbations of various evaluation benchmarks. In contrast to previous work, we examine LLM sensitivity from an holistic perspective, and assess the joint effects of perturbations along various dimensions, resulting in thousands of perturbations per instance. We evaluate several model families against DOVE, leading to several findings, including efficient methods for choosing well-performing prompts, observing that few-shot examples reduce sensitivity, and identifying instances which are inherently hard across all perturbations. DOVE consists of more than 250M prompt perturbations and model outputs, which we make publicly available to spur a community-wide effort toward meaningful, robust, and efficient evaluation. Browse the data, contribute, and more: https://slab-nlp.github.io/DOVE/
The Mighty ToRR: A Benchmark for Table Reasoning and Robustness
Feb 26, 2025



Despite its real-world significance, model performance on tabular data remains underexplored, leaving uncertainty about which model to rely on and which prompt configuration to adopt. To address this gap, we create ToRR, a benchmark for Table Reasoning and Robustness, that measures model performance and robustness on table-related tasks. The benchmark includes 10 datasets that cover different types of table reasoning capabilities across varied domains. ToRR goes beyond model performance rankings, and is designed to reflect whether models can handle tabular data consistently and robustly, across a variety of common table representation formats. We present a leaderboard as well as comprehensive analyses of the results of leading models over ToRR. Our results reveal a striking pattern of brittle model behavior, where even strong models are unable to perform robustly on tabular data tasks. Although no specific table format leads to consistently better performance, we show that testing over multiple formats is crucial for reliably estimating model capabilities. Moreover, we show that the reliability boost from testing multiple prompts can be equivalent to adding more test examples. Overall, our findings show that table understanding and reasoning tasks remain a significant challenge.
JuStRank: Benchmarking LLM Judges for System Ranking
Dec 12, 2024



Given the rapid progress of generative AI, there is a pressing need to systematically compare and choose between the numerous models and configurations available. The scale and versatility of such evaluations make the use of LLM-based judges a compelling solution for this challenge. Crucially, this approach requires first to validate the quality of the LLM judge itself. Previous work has focused on instance-based assessment of LLM judges, where a judge is evaluated over a set of responses, or response pairs, while being agnostic to their source systems. We argue that this setting overlooks critical factors affecting system-level ranking, such as a judge's positive or negative bias towards certain systems. To address this gap, we conduct the first large-scale study of LLM judges as system rankers. System scores are generated by aggregating judgment scores over multiple system outputs, and the judge's quality is assessed by comparing the resulting system ranking to a human-based ranking. Beyond overall judge assessment, our analysis provides a fine-grained characterization of judge behavior, including their decisiveness and bias.
Can You Trust Your Metric? Automatic Concatenation-Based Tests for Metric Validity
Aug 22, 2024



Consider a scenario where a harmfulness detection metric is employed by a system to filter unsafe responses generated by a Large Language Model. When analyzing individual harmful and unethical prompt-response pairs, the metric correctly classifies each pair as highly unsafe, assigning the highest score. However, when these same prompts and responses are concatenated, the metric's decision flips, assigning the lowest possible score, thereby misclassifying the content as safe and allowing it to bypass the filter. In this study, we discovered that several harmfulness LLM-based metrics, including GPT-based, exhibit this decision-flipping phenomenon. Additionally, we found that even an advanced metric like GPT-4o is highly sensitive to input order. Specifically, it tends to classify responses as safe if the safe content appears first, regardless of any harmful content that follows, and vice versa. This work introduces automatic concatenation-based tests to assess the fundamental properties a valid metric should satisfy. We applied these tests in a model safety scenario to assess the reliability of harmfulness detection metrics, uncovering a number of inconsistencies.
Benchmark Agreement Testing Done Right: A Guide for LLM Benchmark Evaluation
Jul 18, 2024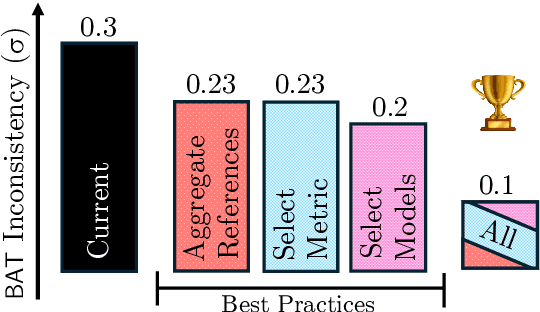
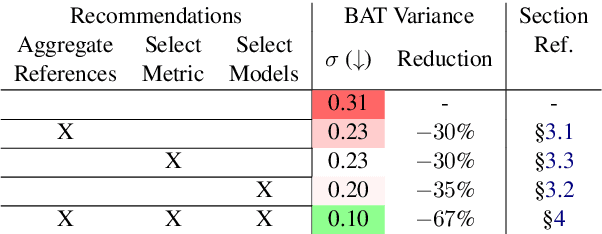
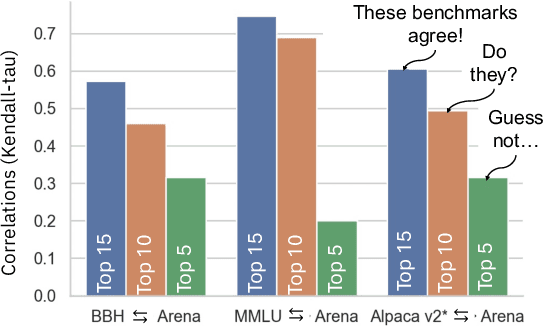
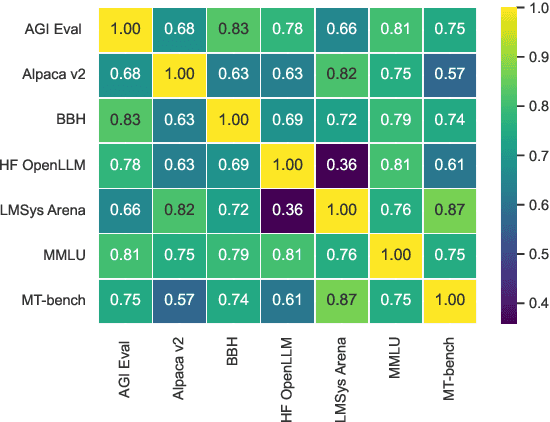
Recent advancements in Language Models (LMs) have catalyzed the creation of multiple benchmarks, designed to assess these models' general capabilities. A crucial task, however, is assessing the validity of the benchmarks themselves. This is most commonly done via Benchmark Agreement Testing (BAT), where new benchmarks are validated against established ones using some agreement metric (e.g., rank correlation). Despite the crucial role of BAT for benchmark builders and consumers, there are no standardized procedures for such agreement testing. This deficiency can lead to invalid conclusions, fostering mistrust in benchmarks and upending the ability to properly choose the appropriate benchmark to use. By analyzing over 40 prominent benchmarks, we demonstrate how some overlooked methodological choices can significantly influence BAT results, potentially undermining the validity of conclusions. To address these inconsistencies, we propose a set of best practices for BAT and demonstrate how utilizing these methodologies greatly improves BAT robustness and validity. To foster adoption and facilitate future research,, we introduce BenchBench, a python package for BAT, and release the BenchBench-leaderboard, a meta-benchmark designed to evaluate benchmarks using their peers. Our findings underscore the necessity for standardized BAT, ensuring the robustness and validity of benchmark evaluations in the evolving landscape of language model research. BenchBench Package: https://github.com/IBM/BenchBench Leaderboard: https://huggingface.co/spaces/per/BenchBench
Holmes: Benchmark the Linguistic Competence of Language Models
Apr 29, 2024We introduce Holmes, a benchmark to assess the linguistic competence of language models (LMs) - their ability to grasp linguistic phenomena. Unlike prior prompting-based evaluations, Holmes assesses the linguistic competence of LMs via their internal representations using classifier-based probing. In doing so, we disentangle specific phenomena (e.g., part-of-speech of words) from other cognitive abilities, like following textual instructions, and meet recent calls to assess LMs' linguistic competence in isolation. Composing Holmes, we review over 250 probing studies and feature more than 200 datasets to assess syntax, morphology, semantics, reasoning, and discourse phenomena. Analyzing over 50 LMs reveals that, aligned with known trends, their linguistic competence correlates with model size. However, surprisingly, model architecture and instruction tuning also significantly influence performance, particularly in morphology and syntax. Finally, we propose FlashHolmes, a streamlined version of Holmes designed to lower the high computation load while maintaining high-ranking precision.
Unitxt: Flexible, Shareable and Reusable Data Preparation and Evaluation for Generative AI
Jan 25, 2024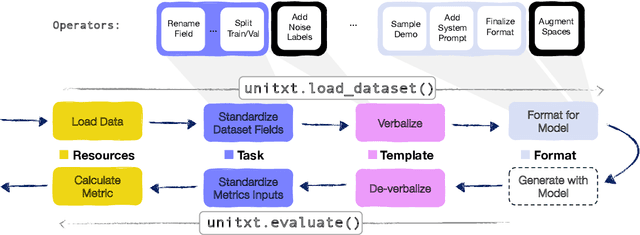

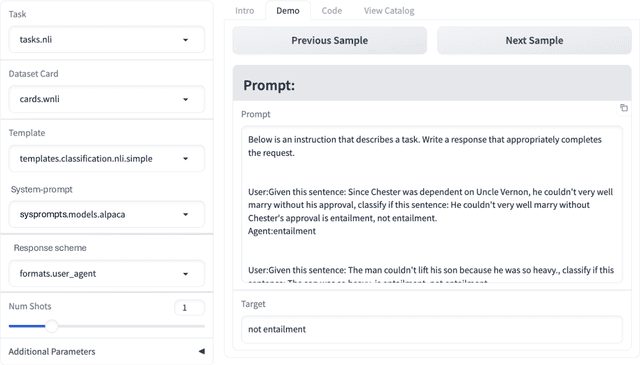

In the dynamic landscape of generative NLP, traditional text processing pipelines limit research flexibility and reproducibility, as they are tailored to specific dataset, task, and model combinations. The escalating complexity, involving system prompts, model-specific formats, instructions, and more, calls for a shift to a structured, modular, and customizable solution. Addressing this need, we present Unitxt, an innovative library for customizable textual data preparation and evaluation tailored to generative language models. Unitxt natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively. Join the Unitxt community at https://github.com/IBM/unitxt!
Efficient Benchmarking (of Language Models)
Aug 31, 2023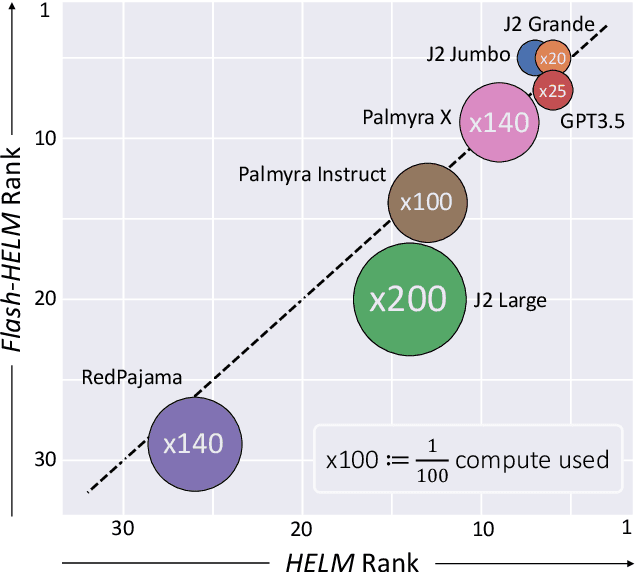
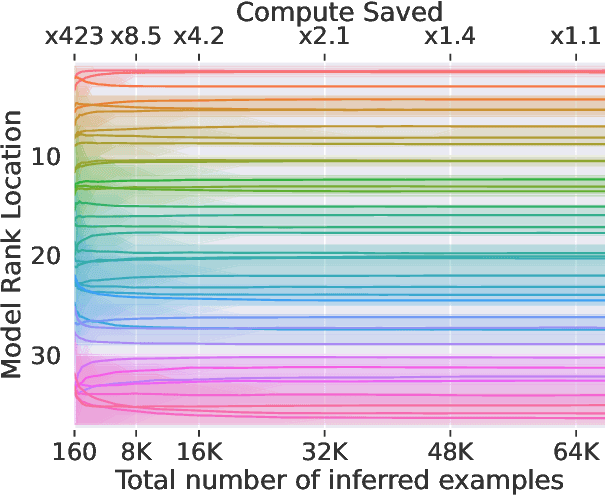
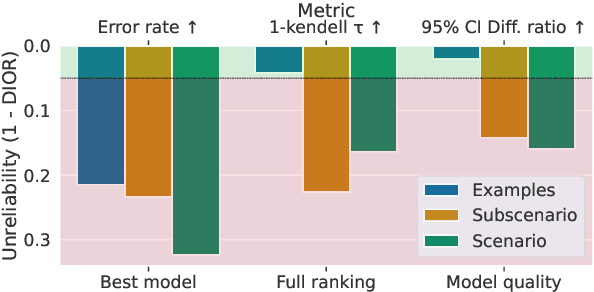
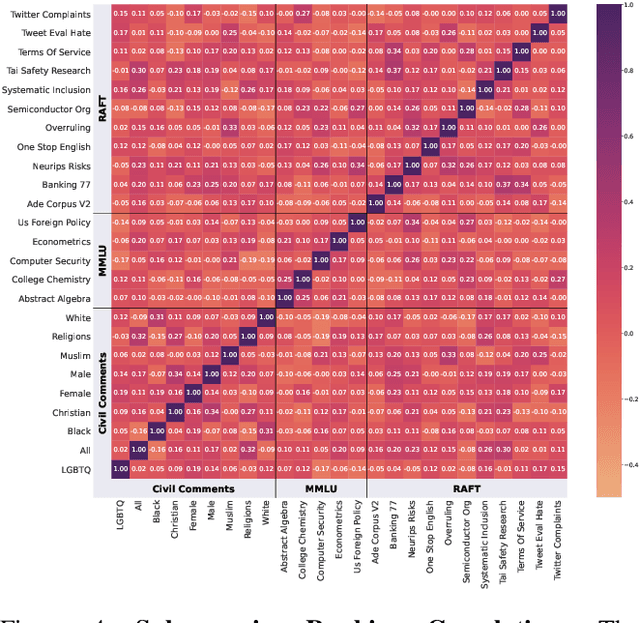
The increasing versatility of language models LMs has given rise to a new class of benchmarks that comprehensively assess a broad range of capabilities. Such benchmarks are associated with massive computational costs reaching thousands of GPU hours per model. However the efficiency aspect of these evaluation efforts had raised little discussion in the literature. In this work we present the problem of Efficient Benchmarking namely intelligently reducing the computation costs of LM evaluation without compromising reliability. Using the HELM benchmark as a test case we investigate how different benchmark design choices affect the computation-reliability tradeoff. We propose to evaluate the reliability of such decisions by using a new measure Decision Impact on Reliability DIoR for short. We find for example that the current leader on HELM may change by merely removing a low-ranked model from the benchmark and observe that a handful of examples suffice to obtain the correct benchmark ranking. Conversely a slightly different choice of HELM scenarios varies ranking widely. Based on our findings we outline a set of concrete recommendations for more efficient benchmark design and utilization practices leading to dramatic cost savings with minimal loss of benchmark reliability often reducing computation by x100 or more.
Active Learning for Natural Language Generation
May 24, 2023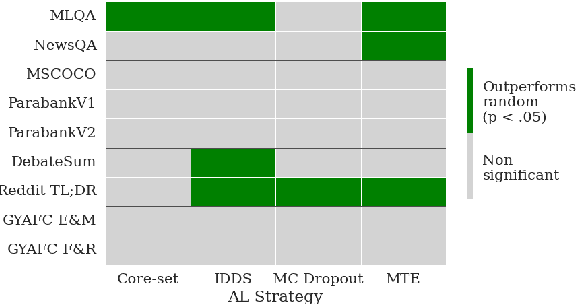

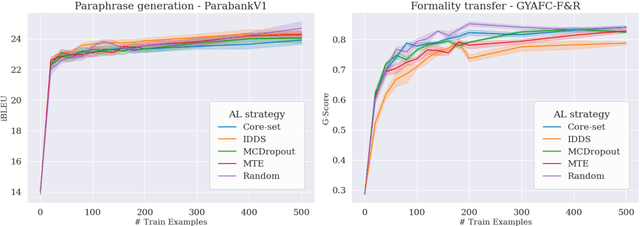

The field of text generation suffers from a severe shortage of labeled data due to the extremely expensive and time consuming process involved in manual annotation. A natural approach for coping with this problem is active learning (AL), a well-known machine learning technique for improving annotation efficiency by selectively choosing the most informative examples to label. However, while AL has been well-researched in the context of text classification, its application to text generation remained largely unexplored. In this paper, we present a first systematic study of active learning for text generation, considering a diverse set of tasks and multiple leading AL strategies. Our results indicate that existing AL strategies, despite their success in classification, are largely ineffective for the text generation scenario, and fail to consistently surpass the baseline of random example selection. We highlight some notable differences between the classification and generation scenarios, and analyze the selection behaviors of existing AL strategies. Our findings motivate exploring novel approaches for applying AL to NLG tasks.
nBIIG: A Neural BI Insights Generation System for Table Reporting
Nov 08, 2022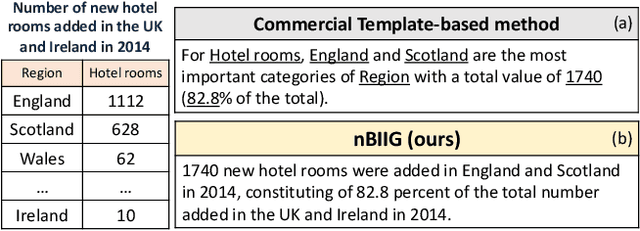
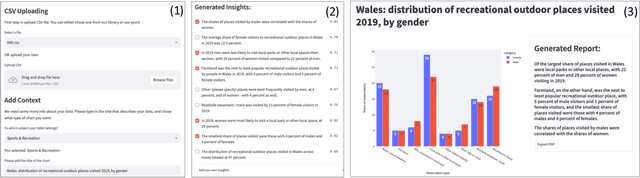
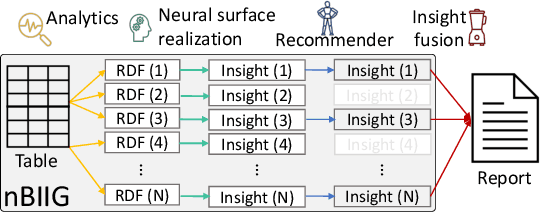
We present nBIIG, a neural Business Intelligence (BI) Insights Generation system. Given a table, our system applies various analyses to create corresponding RDF representations, and then uses a neural model to generate fluent textual insights out of these representations. The generated insights can be used by an analyst, via a human-in-the-loop paradigm, to enhance the task of creating compelling table reports. The underlying generative neural model is trained over large and carefully distilled data, curated from multiple BI domains. Thus, the system can generate faithful and fluent insights over open-domain tables, making it practical and useful.