 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Hyper-Parameter Optimization Methods for Retrieval Augmented Generation
May 06, 2025Finding the optimal Retrieval-Augmented Generation (RAG) configuration for a given use case can be complex and expensive. Motivated by this challenge, frameworks for RAG hyper-parameter optimization (HPO) have recently emerged, yet their effectiveness has not been rigorously benchmarked. To address this gap, we present a comprehensive study involving 5 HPO algorithms over 5 datasets from diverse domains, including a new one collected for this work on real-world product documentation. Our study explores the largest HPO search space considered to date, with two optimized evaluation metrics. Analysis of the results shows that RAG HPO can be done efficiently, either greedily or with iterative random search, and that it significantly boosts RAG performance for all datasets. For greedy HPO approaches, we show that optimizing models first is preferable to the prevalent practice of optimizing sequentially according to the RAG pipeline order.
JuStRank: Benchmarking LLM Judges for System Ranking
Dec 12, 2024



Given the rapid progress of generative AI, there is a pressing need to systematically compare and choose between the numerous models and configurations available. The scale and versatility of such evaluations make the use of LLM-based judges a compelling solution for this challenge. Crucially, this approach requires first to validate the quality of the LLM judge itself. Previous work has focused on instance-based assessment of LLM judges, where a judge is evaluated over a set of responses, or response pairs, while being agnostic to their source systems. We argue that this setting overlooks critical factors affecting system-level ranking, such as a judge's positive or negative bias towards certain systems. To address this gap, we conduct the first large-scale study of LLM judges as system rankers. System scores are generated by aggregating judgment scores over multiple system outputs, and the judge's quality is assessed by comparing the resulting system ranking to a human-based ranking. Beyond overall judge assessment, our analysis provides a fine-grained characterization of judge behavior, including their decisiveness and bias.
HowSumm: A Multi-Document Summarization Dataset Derived from WikiHow Articles
Oct 08, 2021



We present HowSumm, a novel large-scale dataset for the task of query-focused multi-document summarization (qMDS), which targets the use-case of generating actionable instructions from a set of sources. This use-case is different from the use-cases covered in existing multi-document summarization (MDS) datasets and is applicable to educational and industrial scenarios. We employed automatic methods, and leveraged statistics from existing human-crafted qMDS datasets, to create HowSumm from wikiHow website articles and the sources they cite. We describe the creation of the dataset and discuss the unique features that distinguish it from other summarization corpora. Automatic and human evaluations of both extractive and abstractive summarization models on the dataset reveal that there is room for improvement.
A Study of Human Summaries of Scientific Articles
Feb 10, 2020

Researchers and students face an explosion of newly published papers which may be relevant to their work. This led to a trend of sharing human summaries of scientific papers. We analyze the summaries shared in one of these platforms Shortscience.org. The goal is to characterize human summaries of scientific papers, and use some of the insights obtained to improve and adapt existing automatic summarization systems to the domain of scientific papers.
A Summarization System for Scientific Documents
Aug 29, 2019

We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.
Unsupervised Dual-Cascade Learning with Pseudo-Feedback Distillation for Query-based Extractive Summarization
Nov 01, 2018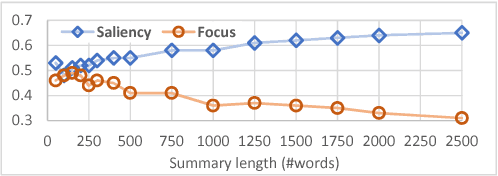
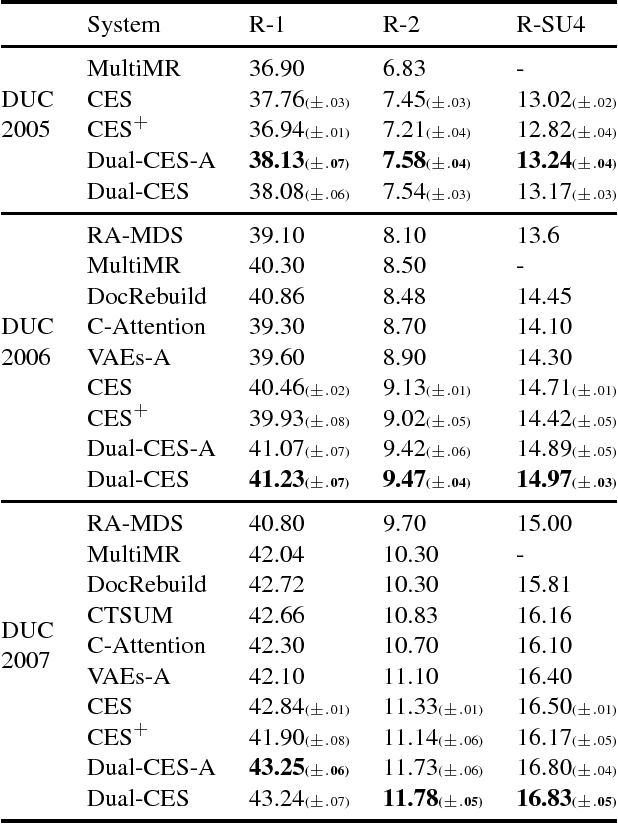
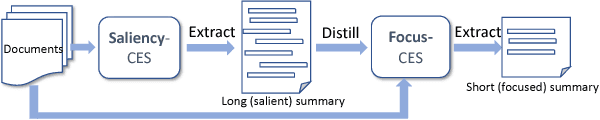
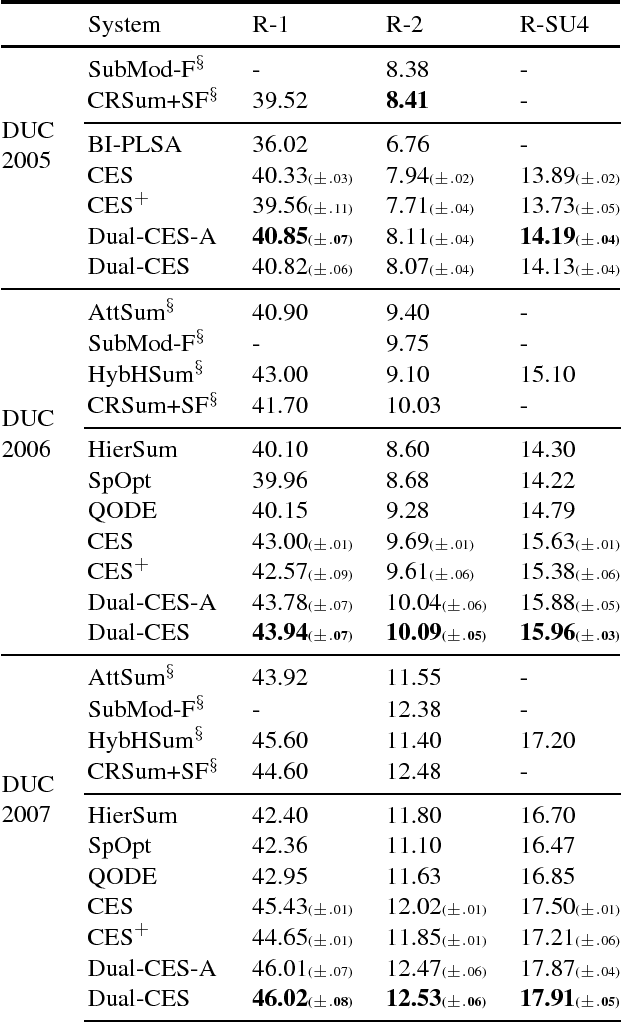
We propose Dual-CES -- a novel unsupervised, query-focused, multi-document extractive summarizer. Dual-CES is designed to better handle the tradeoff between saliency and focus in summarization. To this end, Dual-CES employs a two-step dual-cascade optimization approach with saliency-based pseudo-feedback distillation. Overall, Dual-CES significantly outperforms all other state-of-the-art unsupervised alternatives. Dual-CES is even shown to be able to outperform strong supervised summarizers.